
phase = 'train'
model.train()
# train모드 아래 dloader의 phase를 가져와서 index, batch로 나눠서 순회 후 처리
for index, batch in enumerate(dloaders[phase]):
images = batch[0] # batch에 들어온 값: images, targets, filenames
targets = batch[1]
filenames = batch[2]
images = list(image for image in images) # list화해서 images에 담아줌
# target의 t만큼 items를 꺼내서 key와 value를 dict형태로 만들어 list로 묶음.
# list안에 dict가 여러 개 들어가있는 형태
targets = [{k: v for k, v in t.items()} for t in targets]
# loss값 구하기
loss = model(images, targets)
if index == 0: # index가 0에 해당하는 부분의 loss만 확인
break
loss
'''
2stage: class를 구분하는 stage. 아래에서 쳐준 box로 분류를 진행.
{'loss_classifier': tensor(1.3550, grad_fn=<NllLossBackward0>),
'loss_box_reg': tensor(0.0431, grad_fn=<DivBackward0>), // object를 분류
1 stage: 실제로 object가 존재하는지의 여부를 나타내는 stage. 예측값을 rpn_box_reg이 가짐.
'loss_objectness': tensor(0.4544, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>),
'loss_rpn_box_reg': tensor(0.0426, grad_fn=<DivBackward0>)} // object를 예측
'''
# 1바퀴 돌때마다 training해주는 함수 생성
def train_one_epoch(dataloadrs, model, optimizer, device):
train_loss = defaultdict(float) # dictionary를 float형으로 초기화
val_loss = defaultdict(float) # dictionary를 float형으로 초기화
model.train()
# train과 val을 같이 돌릴예정이므로 for문을 삽입
for phase in ['train', 'val']:
# train모드 아래 dloader의 phase를 가져와서 index, batch로 나눠서 순회 후 처리
for index, batch in enumerate(dloaders[phase]):
images = batch[0] # batch에 들어온 값: images, targets, filenames
targets = batch[1]
filenames = batch[2]
images = list(image for image in images) # list화해서 images에 담아줌
# target의 t만큼 items를 꺼내서 key와 value를 dict형태로 만들어 list로 묶음.
# list안에 dict가 여러 개 들어가있는 형태
targets = [{k: v for k, v in t.items()} for t in targets]
# val에서는 loss가 필요없으므로 with문 생성
# phase가 train일 때 gradient가 setting되도록 with문 삽입
with torch.set_grad_enabled(phase=='train'):
loss = model(images, targets)
# 각각의 loss를 sum을 내어 total_loss에 저장
total_loss = sum(each_loss for each_loss in loss.values())
if phase == 'train':
# train모드일때는 optimize를 초기화, 역전파생성, 가중치생성
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# index가 0보다 큰 경우와 상수값(VERBOSE_FREQ)이 일정할 때 마다
if (index > 0) and (index % VERBOSE_FREQ)==0:
# dataloader의 모드의 전체 길이와 index를 구한 후
text = f"{index}/{len(dataloaders[phase])} - "
for k, v in loss.items(): # loss값의 key와 value를 얻은 후
text += f'{k}: {v.item():.4f} ' # text에 더해나감
print(text)
for k, v in loss.items():
train_loss[k] += v.item() # item값을 loss값에 누적
# 누적한 값을 total_loss에 기억시켜둠 # 전체 loss값의 누적값을 확인
train_loss['total_loss'] += total_loss.item()
else: # val mode인 경우
for k, v in loss.items():
val_loss[k] += v.item() # item값을 loss값에 누적
val_loss['total_loss'] += total_loss.item()
for k in train_loss.keys():
train_loss[k] /= len(dataloaders['train']) # batch size만큼 나눔
val_loss[k] /= len(dataloaders['val']) # batch size만큼 나눔
return train_loss, val_loss # train_loss와 val_loss를 구한 값을 return
# 상수값들 정리
data_dir = './DataSet/'
is_cuda = False
NUM_CLASSES = 2 # 버스와 트럭
IMAGE_SIZE = 448
BATCH_SIZE = 8
VERBOSE_FREQ = 100 # 100마다 나누어서 출력
DEVICE = torch.device('cuda' if torch.cuda.is_available and is_cuda else 'cpu')
dataloaders = build_dataloader(data_dir=data_dir, batch_size=BATCH_SIZE, image_size=IMAGE_SIZE)
model = build_model(num_classes=NUM_CLASSES)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
num_epochs = 30
train_losses = []
val_losses = []
for epoch in range(num_epochs): # 30번 돌릴 예정
# 1번 돌릴때마다 train_loss와 val_loss를 return받도록 함
train_loss, val_loss = train_one_epoch(dataloaders, model, optimizer, DEVICE)
train_losses.append(train_loss) # train_loss 누적
val_losses.append(val_loss) # val_loss 누적
print(f"epoch:{epoch+1}/{num_epochs} - Train Loss: {train_loss['total_loss']:.4f}, Val Loss: {val_loss['total_loss']:.4f}")
if (epoch+1) % 10 == 0: # epoch 10번마다 1번 저장 -> 30번 epoch면 3번 저장
# save_model 함수 이용 <- util.py에 만들 예정
save_model(model.stat_dict(), f'model_{epoch+1}.pth')
학습에 시간이 매우 오래걸리므로 주의!
# 시각화 (강사님이 전달해주신 코드)
tr_loss_classifier = []
tr_loss_box_reg = []
tr_loss_objectness = []
tr_loss_rpn_box_reg = []
tr_loss_total = []
for tr_loss in train_losses:
tr_loss_classifier.append(tr_loss['loss_classifier'])
tr_loss_box_reg.append(tr_loss['loss_box_reg'])
tr_loss_objectness.append(tr_loss['loss_objectness'])
tr_loss_rpn_box_reg.append(tr_loss['loss_rpn_box_reg'])
tr_loss_total.append(tr_loss['total_loss'])
val_loss_classifier = []
val_loss_box_reg = []
val_loss_objectness = []
val_loss_rpn_box_reg = []
val_loss_total = []
for vl_loss in val_losses:
val_loss_classifier.append(vl_loss['loss_classifier'])
val_loss_box_reg.append(vl_loss['loss_box_reg'])
val_loss_objectness.append(vl_loss['loss_objectness'])
val_loss_rpn_box_reg.append(vl_loss['loss_rpn_box_reg'])
val_loss_total.append(vl_loss['total_loss'])
plt.figure(figsize=(8, 4))
plt.plot(tr_loss_total, label="train_total_loss")
plt.plot(tr_loss_classifier, label="train_loss_classifier")
plt.plot(tr_loss_box_reg, label="train_loss_box_reg")
plt.plot(tr_loss_objectness, label="train_loss_objectness")
plt.plot(tr_loss_rpn_box_reg, label="train_loss_rpn_box_reg")
plt.plot(val_loss_total, label="train_total_loss")
plt.plot(val_loss_classifier, label="val_loss_classifier")
plt.plot(val_loss_box_reg, label="val_loss_box_reg")
plt.plot(val_loss_objectness, label="val_loss_objectness")
plt.plot(val_loss_rpn_box_reg, label="val_loss_rpn_box_reg")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.grid("on")
plt.legend(loc='upper right')
plt.tight_layout()
# 모델을 로드하는 함수 생성
def load_model(ckpt_path, num_classes, device):
checkpoint = torch.load(ckpt_path, map_location=device)
model = build_model(num_classes=num_classes)
model.load_state_dict(checkpoint)
model = model.to(device)
model.eval() # 학습모드가 아닌 상태로 변경
return model # model을 반환
model = load_model(ckpt_path='./model_30.pth', num_classes=NUM_CLASSES, device=DEVICE)
model
Confidence Threshold
객체 탐지와 같은 작업에서 사용되는 개념
객체 탐지 모델은 입력 이미지에서 객체의 위치를 찾아내는 작업을 수행
→ 모델은 주어진 이미지 내에서 다양한 위치에 대해 객체가 존재하는지 예측하고,
각 객체에 대한 바운딩 박스와 해당 객체에 대한 신뢰도(confidence score)를 출력함
신뢰도를 조절하는 기준값
예) Confidence Threshold를 0.8로 설정하면 모델은 신뢰도가 0.8 이상인 객체만을 선택하게 됨.
Confidence Threshold를 적절하게 설정해야 객체 탐지의 정확도를 높일 수 있음.
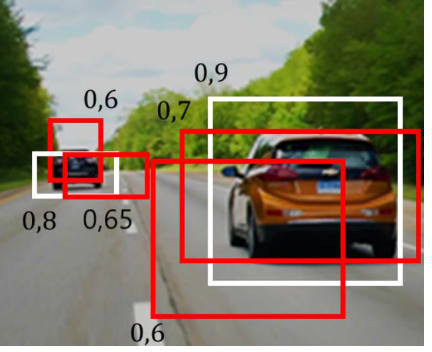
Non-Maximum Suppression(NMS)
중복된 결과를 제거하여 정확하고 겹치지 않는 객체를 식별하는데 사용
NMS가 작동되는 순서
1) 객체 탐지 모델 실행(이미지를 입력받아 바운딩 박스와 신뢰도를 출력)
2) 바운딩 박스 필터링
(겹치는 바운딩 박스들 중에서 가장 확실한 바운딩 박스만 남고 나머지 겹치는 바운딩 박스는 제거, IoU지표를 사용)
IoU(Intersection over Union)
객체 탐지나 세그멘테이션과 같은 CV에서 모델이 예측한 결과와 실제 라벨사이의 정확도를 측정하는 지표
바운딩박스나 세그멘테이션 마스크가 얼마나 겹치는지를 측정하여, 예측 결과의 정확성을 평가하는데 사용함
0과 1사이의 값으로 1에 가까울수록 예측결과가 정확하고 겹치는 영역이 많다는 것을 의미함
계산 방법
영역 A와 영역 B의 겹치는 영역 계산. 공통 부분을 계산.
교집합 계산(얼마나 겹쳐져 있는지)
합집합 계산(두 영역의 전체크기)
IoU 계산(교집합을 합집합으로 나눔. 교집합/합집합)
# 후처리 관련 함수 생성
# 0.3이하의 값들은 걸러냄 // 겹침기준은 0.2
def postprocess(prediction, conf_thres=0.3, IoU_threshold=0.2):
pred_box = prediction['boxes'].cpu().detach().numpy() # bounding box
pred_label = prediction['labels'].cpu().detach().numpy() # label
pred_conf = prediction['scores'].cpu().detach().numpy() # confidence score
valid_index = pred_conf > conf_thres # conf_thres보다 큰 pred_conf값만 valid_index에 넣겠다
pred_box = pred_box[valid_index]
pred_label = pred_label[valid_index]
pred_conf = pred_conf[valid_index]
# Tensor형으로 nms에 넣어주어야 함
valid_index = nms(torch.tensor(pred_box.astype(np.float32)), torch.tensor(pred_conf), IoU_threshold)
# nms에 의해 찾고자하는 object만 찾아짐
pred_box = pred_box[valid_index.numpy()]
# np.newaxis 대신 np.expand_dims를 사용하여 차원을 추가
pred_conf = np.expand_dims(pred_conf, axis=1)
pred_label = np.expand_dims(pred_label, axis=1)
# 결과물들을 concatenate
return np.concatenate((pred_box, pred_conf, pred_label), axis=1)
pred_images = []
pred_labels = []
# 언더바(_)는 target의 위치지만, 사용하지 않을 예정이라 언더바처리함.
for index, (images, _, filenames) in enumerate(dataloaders['val']):
images = list(image.to(DEVICE) for image in images)
filename = filenames[0]
image = make_grid(images[0].cpu().detach(), normalize=True).permute(1,2,0).numpy()
image = (image * 255).astype(np.uint8)
with torch.no_grad(): # 학습이 되지 않은 mode
prediction = model(images) # 모델에 이미지를 넣어 예측을 함
prediction=postprocess(prediction[0])
prediction[:, 2].clip(min=0, max=image.shape[1])
prediction[:, 3].clip(min=0, max=image.shape[0])
xc = (prediction[:, 0] + prediction[:, 2])/2 # X center
yc = (prediction[:, 1] + prediction[:, 3])/2 # Y center
w = prediction[:, 2] - prediction[:, 0] # width
h = prediction[:, 3] - prediction[:, 1] # height
cls_id = prediction[:, 5]
prediction_yolo = np.stack([xc, yc, w, h, cls_id], axis=1) # 하나로 합쳐줌
pred_images.append(image)
pred_labels.append(prediction_yolo) # 이미지와 라벨들을 리스트 안에 넣어줌
if index == 0:
break # 1바퀴만 돌려보기
pred_labels
@interact(index=(0, len(pred_images)-1))
def show_result(index=0):
result = visualize(pred_images[index], pred_labels[index][:, 0:4], pred_labels[index][:, 4])
plt.figure(figsize=(6,6))
plt.imshow(result)
plt.show()
예제
강사님이 주신 비디오로 bounding box를 구현해보기
video_path = './sample_video.mp4'
@torch.no_grad()
def model_predict(image, model):
tensor_image = transformer(image)
tensor_image = tensor_image.to(DEVICE)
prediction = model([tensor_image])
return prediction
video = cv2.VideoCapture(video_path)
while(video.isOpened()):
ret, frame = video.read()
if ret:
ori_h, ori_w = frame.shape[:2]
image = cv2.resize(frame, dsize=(IMAGE_SIZE, IMAGE_SIZE))
prediction = model_predict(image, model)
prediction = postprocess(prediction[0])
prediction[:, [0,2]] *= (ori_w / IMAGE_SIZE)
prediction[:, [1,3]] *= (ori_h / IMAGE_SIZE)
prediction[:, 2].clip(min=0, max=image.shape[1])
prediction[:, 3].clip(min=0, max=image.shape[0])
xc = (prediction[:,0] + prediction[:, 2]) / 2
yc = (prediction[:,1] + prediction[:, 3]) / 2
w = prediction[:,2] - prediction[:, 0]
h = prediction[:,3] - prediction[:, 1]
cls_id = prediction[:, 5]
prediction_yolo = np.stack([xc, yc, w, h, cls_id], axis=1)
canvas = visualize(frame, prediction_yolo[:, 0:4], prediction_yolo[:, 4])
cv2.imshow('camera', canvas)
key = cv2.waitKey(1)
if key == 27:
break
if key == ord('s'):
cv2.waitKey()
video.release()



