
# 1. 필요한 모듈 및 라이브러리 설치
!pip install albumentations
import os
import cv2
import torch
import numpy as np
import albumentations as A
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
import torchvision
import torch.nn as nn
from ipywidgets import interact
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import make_grid
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from util import CLASS_NAME_TO_ID, visualize, save_model # 직접 만든 util.py에서 가져옴
from collections import defaultdict
from torchvision.ops import nms
from albumentations.pytorch import ToTensorV2
# 2. 데이터셋 확인
data_dir = './DataSet/'
data_dir_train = './DataSet/train/'
data_df = pd.read_csv(os.path.join(data_dir, 'df.csv'))
data_df

# 3. file 확인
index = 0
image_files = [fn for fn in os.listdir(data_dir_train) if fn.endswith('jpg')]
image_file = image_files[index]
image_file

# 4. train set의 이미지 확인
image_path = os.path.join(data_dir_train, image_file)
image_path

# 5. 이미지 불러들이기
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image.shape

# 6. 0번 이미지의 meta 정보 가져오기
image_id = image_file.split('.')[0] # 파일명과 확장명이 나눠져서 리스트에서 인덱싱
meta_data = data_df[data_df['ImageID'] == image_id]
meta_data

# 7. 카테고리 이름 뽑아오기
cate_names = meta_data['LabelName'].values
cate_names
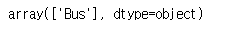
# 8. bounding box 좌표 가져오기
bboxes = meta_data[['XMin', 'XMax', 'YMin', 'YMax']].values
bboxes
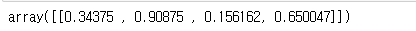
# 9. 높이, 너비 가져오기
img_H, img_W, _ = image.shape
img_H, img_W

# 10. class id 가져오기 // 버스인지 트럭인지 확인할 수 있는 번호
class_ids = [CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names]
class_ids

# 11. YOLO 방식의 좌표사용법 가져오기
# 'XMin', 'XMax', 'YMin', 'YMax'
unnorm_bboxes = bboxes.copy()
print(unnorm_bboxes)
# X_cen, Y_cen, W, H
unnorm_bboxes[0][0] = (bboxes[0][0] + bboxes[0][1])/2
unnorm_bboxes[0][1] = (bboxes[0][2] + bboxes[0][3])/2
unnorm_bboxes[0][2] = bboxes[0][1] - bboxes[0][0]
unnorm_bboxes[0][3] = bboxes[0][3] - bboxes[0][2]
print(unnorm_bboxes)
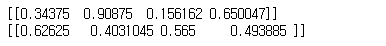
# 12.
unnorm_bboxes = bboxes.copy()
# XMax', 'YMin'의 자리를 바꿈
# 'XMin', 'YMin','XMax', 'YMax'
unnorm_bboxes[:, [1,2]] = unnorm_bboxes[:, [2,1]]
# 'XMax' - 'XMin', 'YMax' - 'YMin'
# 'XMin', 'YMin', w, h
unnorm_bboxes[:, 2:4] -= unnorm_bboxes[:, 0:2]
# 'XMin', 'YMin' += (w, h)/2
# 'XMin' + (w/2), 'YMin' + (h/2)
# X_cen, Y_cen, W, H
unnorm_bboxes[:, 0:2] += (unnorm_bboxes[:, 2:4]/2)
print(unnorm_bboxes)
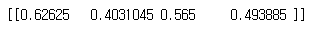
# 13. 높이 너비 가져오기
unnorm_bboxes[:,[0,2]] *= img_W
unnorm_bboxes[:,[1,3]] *= img_H
unnorm_bboxes
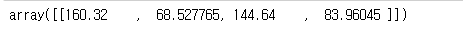
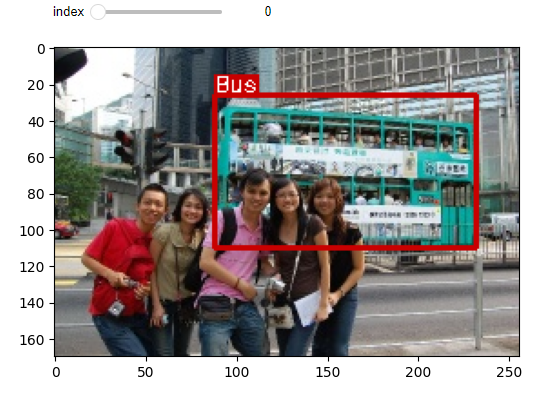
# 14. interact로 시각화
@interact(index=(0, len(image_files)-1))
def show_sample(index=0):
image_file = image_files[index]
image_path = os.path.join('./DataSet/train/',image_file)
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_id = image_file.split('.')[0]
meta_data = data_df[data_df['ImageID'] == image_id]
cate_names = meta_data['LabelName'].values
bboxes = meta_data[['XMin', 'XMax', 'YMin', 'YMax']].values
img_H, img_W, _ = image.shape
class_ids = [CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names]
unnorm_bboxes = bboxes.copy()
unnorm_bboxes[:, [1,2]] = unnorm_bboxes[:, [2,1]]
unnorm_bboxes[:, 2:4] -= unnorm_bboxes[:, 0:2]
unnorm_bboxes[:, 0:2] += (unnorm_bboxes[:, 2:4]/2)
unnorm_bboxes[:,[0,2]] *= img_W
unnorm_bboxes[:,[1,3]] *= img_H
# 시각화
canvas = visualize(image, unnorm_bboxes, class_ids) # 이미지, box좌표, 클래스(0 or 1)
plt.figure(figsize=(6,6))
plt.imshow(canvas)
plt.show()
# 15. dataset 검출 class 생성
class Detection_dataset():
def __init__(self, data_dir, phase, transformer=None):
self.data_dir = data_dir
self.phase = phase
self.data_df = pd.read_csv(os.path.join(self.data_dir, 'df.csv'))
self.image_files = [fn for fn in os.listdir(os.path.join(self.data_dir, phase)) if fn.endswith('jpg')]
self.transformer = transformer
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
filename, image = self.get_image(index)
bboxes, class_ids = self.get_label(filename)
if self.transformer:
transformed_data = self.transformer(image=image,bboxes=bboxes,class_ids=class_ids)
image = transformed_data['image']
bboxes = np.array(transformed_data['bboxes'])
class_ids = np.array(transformed_data['class_ids'])
target = np.concatenate((bboxes,class_ids[:,np.newaxis]),axis=1)
return image, target, filename
def get_image(self, index):
filename = self.image_files[index]
image_path = os.path.join(self.data_dir, self.phase, filename)
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return filename, image
def get_label(self, filename):
image_id = filename.split('.')[0]
meta_data = data_df[data_df['ImageID'] == image_id]
cate_names = meta_data['LabelName'].values
class_ids = np.array([CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names])
bboxes = meta_data[['XMin', 'XMax', 'YMin', 'YMax']].values
bboxes[:, [1, 2]] = bboxes[:, [2, 1]]
#센터값으로 변경
bboxes[:,2:4] -= bboxes[:, 0:2]
bboxes[:,0:2] += (bboxes[:, 2:4]/2)
return bboxes, class_ids
# 객체 생성
dataset = Detection_dataset(data_dir=data_dir, phase='train', transformer=None)
dataset[3] # array형태로 출력됨

index = 20
image, target, filename = dataset[index]
target, filename # array로 출력
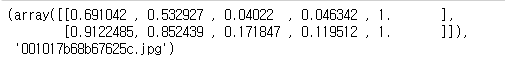
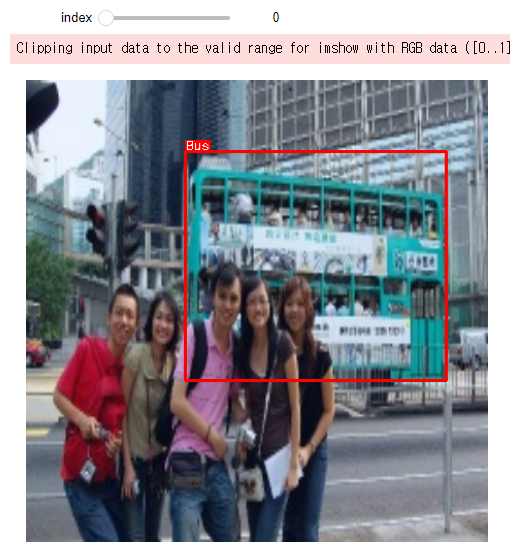
bboxes = target[:, 0:4] # key,value가 없는 dict형태가 아니기때문에 0에서 4까지를 뽑는 slicing
class_ids = target[:, 4]
img_H, img_W, _ = image.shape
bboxes[:, [0,2]] *= img_W # 정규화되어있으므로 곱해주는 과정이 필요
bboxes[:, [1,3]] *= img_H # 정규화되어있으므로 곱해주는 과정이 필요
canvas = visualize(image, bboxes, class_ids)
plt.figure(figsize=(6, 6))
plt.imshow(canvas)
plt.show()

# 위의 코드를 interact로 바꿔보기
@interact(index=(0, len(dataset)-1))
def show_sample(index=0):
image, target, filename = dataset[index]
bboxes = target[:, 0:4]
class_ids = target[:, 4]
img_H, img_W, _ = image.shape
bboxes[:, [0,2]] *= img_W # 정규화되어있으므로 곱해주는 과정이 필요
bboxes[:, [1,3]] *= img_H # 정규화되어있으므로 곱해주는 과정이 필요
canvas = visualize(image, bboxes, class_ids)
plt.figure(figsize=(6, 6))
plt.imshow(canvas)
plt.axis('off')
plt.show()

Albumentations
* 이미지 데이터 증강 모듈
* 다양한 증강기법: 회전, 이동, 크기조정, 반전, 색상변환
* 빠른 성능을 갖고 있음
* API를 제공
* https://albumentations.ai/
Albumentations
Albumentations: fast and flexible image augmentations
albumentations.ai
IMAGE_SIZE = 448
transformer = A.Compose([
A.Resize(height=IMAGE_SIZE, width=IMAGE_SIZE),
A.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225)),
ToTensorV2()
],
# yolo format으로 bounding box 계산
bbox_params = A.BboxParams(format='yolo', label_fields=['class_ids'])
)
transformed_dataset = Detection_dataset(data_dir=data_dir, phase='train', transformer=transformer)
transformed_dataset[3]

@interact(index=(0, len(dataset) - 1))
def show_sample(index=0):
image, target, filename = transformed_dataset[index]
bboxes = target[:, 0:4]
class_ids = target[:, 4]
_, img_H, img_W = image.shape
bboxes[:, [0, 2]] *= img_W
bboxes[:, [1, 3]] *= img_H
np_image = make_grid(image, normalize=True).cpu().permute(1, 2, 0).numpy()
canvas = visualize(np_image, bboxes, class_ids)
plt.figure(figsize=(6, 6))
plt.imshow(canvas)
plt.axis('off')
plt.show()
#collate_fn: DataLoader에서 데이터를 배치 사이즈씩 나누고, 각 배치에 대하여 해당 함수를 실행한 후에 반환하라고 하는 콜백함수.
def collate_fn(batch):
image_list = []
target_list = []
filename_list = []
for img, target, filename in batch:
image_list.append(img)
target_list.append(target)
filename_list.append(filename)
return torch.stack(image_list, dim=0), target_list, filename_list
BATCH_SIZE = 8 #2의 배수로 주는게 좋음
trainset = Detection_dataset(data_dir = data_dir, phase = 'train', transformer = transformer)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
for index, batch in enumerate(trainloader):
images = batch[0]
targets = batch[1]
filenames = batch[2]
if index == 0:
break
print(targets)
print(filenames)

def build_dataloader(data_dir, batch_size=4, image_size=448):
transformer = A.Compose([
A.Resize(image_size, image_size),
A.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225)),
ToTensorV2()
],
bbox_params = A.BboxParams(format='yolo',label_fields=['class_ids'])
)
dataloaders = {}
train_dataset = Detection_dataset(data_dir=data_dir, phase='train', transformer=transformer)
dataloaders['train'] = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
val_dataset = Detection_dataset(data_dir=data_dir, phase='val', transformer=transformer)
dataloaders['val'] = DataLoader(val_dataset, batch_size=1, shuffle=False, collate_fn=collate_fn)
return dataloaders
BATCH_SIZE = 4
dloaders = build_dataloader(data_dir, batch_size=4)
for phase in ['train', 'val']:
for index, batch in enumerate(dloaders[phase]):
images = batch[0]
targets = batch[1]
filenames = batch[2]
print(targets)
if index == 0:
break

resnet18 = torchvision.models.resnet18(pretrained=True)
resnet18


layers = [m for m in resnet18.children()]
layers

testnet = nn.Sequential(*layers[:-2])
testnet




