
1. 데이터셋
1-1. 데이터셋
기계 학습 모델을 학습하는데 사용되는 데이터의 모음.
데이터셋은 이미지, 오디오, 텍스트, 수치데이터 등 다양한 데이터형으로 구성될 수 있음.
특정 데이터 유형과 데이터셋의 크기는 해결되는 문제와 사용중인 모델 유형에 따라 달라짐.
1-1-1. 데이터셋의 크기
모델이 학습 중에 본 예제의 수.
적은 데이터셋: 다양한 예제가 포함되지 않아 과적합이 발생할 수 있음.
큰 데이터셋: 모델이 충분한 수의 예제를 보고 새 데이터로 일반화할 수 있음.
→ 그래서 데이터는 항상 많아야 함.
1-1-2. 데이터의 품질
주석이나 레이블이 잘못 지정된 데이터셋 → 모델의 성능에 부정적인 영향을 줄 수 있음.
다양한 개체 변형의 존재, 조건, 배경 등을 포함한 데이터셋의 다양성도 모델의 견고성을 보장하는데 중요함.
→ 올바른 데이터셋(충분한 크기와 품질을 갖춘 것)을 선택하는 것이 모델 성능에 큰 영향을 미칠 수 있음.
1-2. 어노테이션(Annotation)
데이터에 정보 또는 레이블을 추가하는 프로세스.
컴퓨터 비전에서는 이미지에서 특정 개체의 존재, 속성(색상, 크기, 모양)을 나타내는 레이블이 포함됨.
수동으로 추가하거나 컴퓨터 알고리즘을 사용하여 자동으로 생성할 수 있음.
1-2-1. 어노테이션의 종류
Bounding Box
이미지 내에서 개체의 위치 및 크기를 정의하는 작업.
객체 주위에 box를, 그리고 클래스(사람, 자동차)로 label을 지정함.
Object detection에 일반적으로 사용되며,
이미지 내에서 객체의 위치를 정의하는 간단하고 효과적인 방법임.
KeyPoint
landmark와 같은 개체 내의 특정 관심지점을 표시하는 작업.
예를 들어, 사람이나 동물의 이미지 내 관절의 위치를 예측하는 것이 목표인 task에 종종 사용.
Segmentation
이미지 내에서 객체의 경계를 정의, 표시, 인식함. 이미지 내의 객체를 분류할 때 사용함.
복잡한 형태의 어노테이션이지만 이미지 내의 객체에 대한 더 자세한 정보를 제공하므로 성능이 향상됨.
1-2-2. 어노테이션의 방법
수동 주석
마우스 또는 스타일러스와 같은 도구를 사용해서 이미지 내의 각 개체에 수동으로 레이블을 지정하는 작업.
가장 시간이 많이 걸리지만 최고 수준의 제어와 정확성을 제공함.
반자동 주석
컴퓨터 지원 도구를 사용하여 주석 프로세스의 속도를 높이는 작업.
어노테이터는 도구를 사용하여 개체 주위에 경계 상자를 그릴 수 있으며,
컴퓨터는 자동으로 개체에 해당 클래스로 레이블을 지정함.
수동 주석보다 빠르지만 정확성을 보장하려면 어느정도 사람의 인력이 필요함.
자동 주석
컴퓨터 알고리즘을 사용하여 이미지 내의 객체에 자동으로 레이블을 지정하는 작업.
가장 빠르지만 정확도는 낮음.
수작업 비용이 많이 드는 대규모 데이터셋에 사용됨.
1-2-3. 어노테이션 툴
“Data Annotation Tool Analysis – How to Use LabelMe”
https://awkvect.com/data-annotation-tool-analysis-how-to-use-labelme
Data Annotation Tool Analysis – How to Use LabelMe | Awakening Vector
awkvect.com
1-3. 데이터셋 포맷
1-3-1. Pascal VOC 데이터셋
http://host.robots.ox.ac.uk/pascal/VOC/
The PASCAL Visual Object Classes Homepage
2006 10 classes: bicycle, bus, car, cat, cow, dog, horse, motorbike, person, sheep. Train/validation/test: 2618 images containing 4754 annotated objects. Images from flickr and from Microsoft Research Cambridge (MSRC) dataset The MSRC images were easier th
host.robots.ox.ac.uk
정의
컴퓨터비전에서 Image detection을 위한 dataset으로 classification, object detection, segmentation
평가 알고리즘을 구축하거나 평가하는데 있어 매우 유명한 데이터셋.
디지털 카메라, 웹페이지 및 스캔이미지를 포함한 다양한 소스에서 가져온 이미지로 구성되며,
사람, 동물, 차량 등의 일상적인 개체를 비롯한 20개의 다양한 개체를 포함함.
각 이미지의 개체는 연도별로 어노테이션 종류가 다양함.
구조
.tar 형식의 데이터셋의 압축을 해제하면 다음과 같은 5개의 디렉토리로 구성되어 있음.
Annotations: 각 데이터의 Object class, Bounding box와 기타 부가 정보들이 들어 있는 xml 파일.
ImageSets: 각 Task에 해당하는 데이터의 파일명이 나열된 txt 파일.
JPEGImages: JPEG 원본 이미지.
SegmentationClass: Semantic Segmentation을 위한 라벨 PNG 파일.
SegmentationClass 폴더의 라벨 이미지는 물체의 Class만을 구분함. (Semantic Segmentation)
SegmentationObject: Instance Segmentation을 위한 라벨 PNG 파일.
SegmentationObject 폴더의 라벨 이미지는 각 Instance를 모두 구분함. (Instance Segmentation)

1-3-2. COCO 데이터셋
COCO - Common Objects in Context
cocodataset.org
정의
Microsoft Research에서 개발한, 컴퓨터비전을 위한 대규모 이미지 인식 데이터셋.
이미지 및 비디오의 개체를 인식하기 위한 알고리즘을 개발하고 평가할 수 있도록 설계되어있음.
디지털카메라, 웹페이지 및 스캔이미지를 포함하여 다양한 소스에서 수집된 이미지가 포함되어 있음.
사람, 동물, 차량, 일상적인 개체를 비롯한 80개의 다양한 개체가 있으며,
각 이미지의 개체는 연도별로 어노테이션 종류가 다양함.
어노테이션에는 이미지에 있는 개체 간의 특성 및 관계에 대한 정보가 포함됨.
구조
학습(training) 데이터셋: 118,000장의 이미지
검증(validation) 데이터셋: 5,000장의 이미지
테스트(test) 데이터셋: 41,000장의 이미지
json형태의 설명 파일: annotations 파일을 다운로드하면 내부에 존재.
이미지에 대한 기본적인 설명과 함께 각 이미지 파일 내부에 어떠한 객체(object)가 존재하는지,
바운딩 박스(bounding box)와 함께 그 클래스(class) 정보가 함께 주어짐.
1-3-3. ImageNet
ImageNet
Mar 11 2021. ImageNet website update.
www.image-net.org
스탠포드 비전 랩과 프린스턴 대학에서 만듦.
디지털 카메라, 웹페이지 및 스캔이미지를 포함한 다양한 소스에서 가져온 1400만개 이상의 이미지로 구성
사람, 동물, 차량 등의 일상적인 개체를 비롯한 20개의 다양한 개체가 있음.
각 이미지에는 1000개의 개체 범주 집합에서 1개 이상의 클래스 레이블이 주석으로 지정됨.
다른 데이터셋과 다르게 annotation format이 따로 없음.
Train/Validation/Test 폴더로 클래스를 구분함.
1-3-4. KITTI
https://www.cvlibs.net/datasets/kitti/
The KITTI Vision Benchmark Suite
We thank Karlsruhe Institute of Technology (KIT) and Toyota Technological Institute at Chicago (TTI-C) for funding this project and Jan Cech (CTU) and Pablo Fernandez Alcantarilla (UoA) for providing initial results. We further thank our 3D object labeling
www.cvlibs.net
Karlsruhe Institute of Technology and Toyota Technological Institute at Chicaco.
컴퓨터비전 및 로봇공학을 위한 데이터셋.
움직이는 차량에서 캡쳐한 이미지 및 비디오에서
객체인식 및 감지를 위한 알고리즘의 개발 및 평가를 위한 실제데이터를 제공하기위해 만들어짐.
움직이는 차량에서 캡처한 7,000개 이상의 이미지와 비디오로 구성됨.
도시 및 농촌 환경에서 도로, 건물, 차량 및 보행자를 포함한 다양한 객체와 장면을 포함하고있음.
각 이미지 또는 비디오의 개체에는 경계상자와 클래스 레이블이 주석으로 추가되어 있으며,
각 주석에는 3D공간에서 개체의 위치와 방향에 대한 정보도 포함되어있음.
1-4. 다양한 데이터셋
https://paperswithcode.com/datasets?mod=images&page=1
Data Annotation Tool Analysis – How to Use LabelMe | Awakening Vector
awkvect.com
2. Classification
2-1. Classification
기계 학습과 통계학에서 시스템이 일련의 특성을 기반으로 미리 정의된 여러 범주 또는 클래스 중
하나에 주어진 입력을 할당하도록 훈련되는 과정.
입력 기능과 클래스 레이블 사이에 학습된 관계를 기반으로 보이지 않는 샘플의 클래스 레이블을 예측하는 것.
Bianry Classification(이진 분류)
데이터 요소를 두 클래스 중 하나로 분류.
스팸 vs 스팸아닌메일 분류
Multiclass Classification(다중 분류)
데이터 요소를 여러 클래스 중 하나로 분류.
필기숫자 인식 및 이미지에서 개체를 인식(강아지, 고양이, 자동차 ..)
Multi-label Classification(다중 레이블 분류)
단일 데이터 요소가 여러 클래스에 속할 수 있음.
이미지 주석(개: 포유동물, 길들여진 동물 ... 둘 다 일수있음)
2-2. CNN(Convolutional Neural Network)
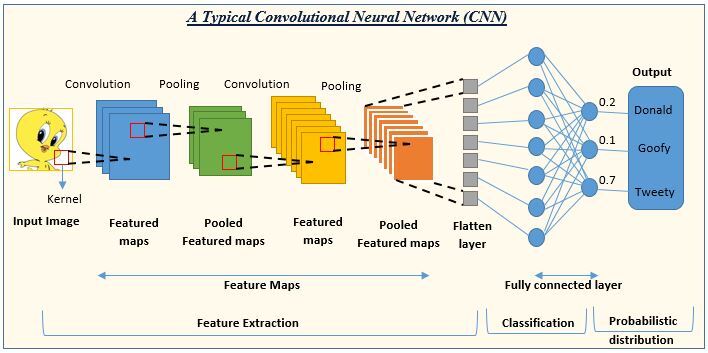
이미지 및 비디오 인식 작업을 위해 설계된 딥러닝 신경망의 한 유형으로,
컨볼루션 계층을 사용해서 입력 데이터에서 특징을 추출하고, 계층을 풀링하고, 공간 차원을 줄이고,
비선형 활성화 함수를 사용해서 비선형성을 도입하고 분류를 위해 완전히 연결된 계층을 사용.
Convolutional Layers:
입력 데이터에 필터 집합을 적용하여 특징을 추출하는 계층
필터는 입력 데이터에서 가장자리, 모양, 기능을 감지하는데 사용
Pooling Layers:
Convolution 계층 이후에는 출력이 Pooling 계층을 통과하는 경우가 많음
중요한 특징을 유지하면서 데이터의 공간 차원을 축소함
일반적으로 필드 내의 최대값이 선택되어 출력으로 사용되는 최대 풀링을 사용함
Non-Linearity:
Pooling 계층의 출력값이 ReLU와 같은 비선형 활성화 함수를 통해 전달되어 네트워크에 비선형성이 도입됨.
입력값과 출력값 간의 복잡한 비선형 관계를 학습할 때 사용
Fully-Connected Layerss:
Convolution 계층과 Pooling 계층 후 출력은 일반적으로 벡터로 평면화되고, 1개 이상의 완전 연결 계층을 통과함
FC 계층은 이전 계층의 출력이 다음 계층에 대한 입력으로 사용되는 전통적인 신경망 계층으로 작동
2-3. Classification 모델 변천사
2-3-1. LeNet-5
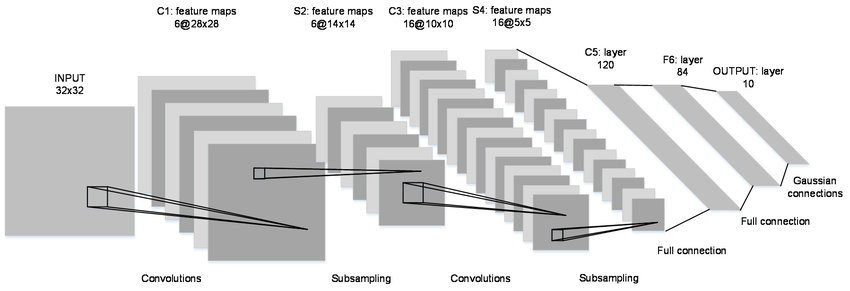
1998년 Yann LeCun 등에 의해 소개된 CNN 아키텍처.
이미지 분류 및 인식 작업을 위해 설계된 최초의 딥러닝 모델 중 하나.
컴퓨터비전 분야의 선구자였으며, 여전히 널리 사용되고 있음.
새로운 아키텍처를 비교하기 위한 벤치마크로 사용됨.
2-3-2. AlexNet
2012년 Alex에 의해 소개된 CNN 아키텍처
이미지 분류 및 인식에 대한 대규모 벤치마크인 ImageNet 데이터셋에서 상당한 성능향상을 달성한 최초의 딥러닝 모델 중 하나
딥러닝 및 컴퓨터비전 분야에서 획기적인 발전을 이루게 함
2-3-3. VGGNet
2014년 Karen Simonyan과 Andrew Zisserman이 도입한 CNN 아키텍처
Convolutional 및 max pooling layer의 여러 스택과 여러 개의 fully connected layer로 구성된 간단하고 균일한 아키텍처로 유명
쉽게 구현이 가능하고 빠르게 학습이 가능함
대규모 데이터셋에서 학습되므로 다른 컴퓨터비전 작업을 위한 사전학습된 모델로 사용할 수 있는 전이학습에 적합
2-3-4. InceptionNet
GoogLeNet으로도 알려진 CNN 아키텍처 모델
Google에서 개발했으며 아키텍처 핵심 구성요소인 Inception 모듈의 이름을 땀
필터 크기와 풀링 연산이 서로 다른 여러 병렬 convolutional branch를 사용하여 입력 이미지에서 특징을 추출하기 때문에 다른 CNN과 비교할 때 독특함.
여러 스케일로 정보를 캡처하고 특징 간의 복잡한 관계를 학습할 수 있음
2-3-5. ResNet
2015년 도입된 CNN 아키텍처
심층 아키텍처와 심층 신경망에서 일반적인 문제인 소실 그라디언트 문제를 해결하는 능력으로 유명함.
네트워크가 기본 매핑 자체가 아니라 입력값과 출력값 간의 residual mapping을 학습하는 residual learning이라는 개념을 기반으로 기울기가 사라지지 않고 훨씬 깊은 아키텍처를 학습할 수 있음.
다양한 컴퓨터 비전 작업에서 최첨단 성능을 달성했으며, 많은 딥 러닝 애플리케이션에서 여전히 인기있는 모델.
전이학습에 널리 사용되며 많은 컴퓨터비전 문제의 좋은 출발점이 됨.
2-3-6. ResNext
2016년 도입된 CNN 아키텍처
ResNet 아키텍처의 확장판. 네트워크 용량과 다양성을 높여 성능을 향상시킴.
네트워크의 병렬 경로 수를 늘려 네트워크가 기능간의 더 복잡한 관계를 학습할 수 있도록 함.
2-3-7. MobileNet
2017년 도입된 CNN 아키텍처
계산이 효율적으로 설계되어 계산 리소스가 제한된 모바일 및 임베디드 장치에 배포하는데 적합함.
효율적인 깊이별 분리 가능한 convolution을 사용하여 네트워크의 매개변수 수를 줄임.
크기가 작고 추론시간이 빠름.
다른 컴퓨터비전 작업을 위한 사전훈련된 모델로 사용할 수 있는 전이학습에 사용됨.
2-3-8. DenseNet
2017년 도입된 CNN 아키텍처
네트워크의 각 계층이 feed-forward 방식으로 다른 모든 계층에 연결되는 조밀한 연결로 유명함.
각 계층을 네트워크의 다른 모든 계층에 연결하여 기능 재사용을 장려하고 네트워크의 파라미터 수를 줄이는 형태.
특징간의 더 복잡한 관계를 학습할 수 있으며 기존 CNN에 비해 파라미터 수가 훨씬 적음. 과적합의 위험 방지 가능.
이미지 분류 및 다양한 컴퓨터비전 작업에서 최첨단 성능을 달성함.
2-3-9. ShuffleNet
2018년 도입된 CNN 아키텍처
계산 효율적으로 설계되어 계산 리소스가 제한된 모바일 및 임베디드 장치에 배포하는데 적합.
feature reordering의 한 유형인 채널셔플링을 사용하여 네트워크의 계층 간 정보 흐름을 개선
채널셔플링: 네트워크가 특징간의 보다 복잡한 관계를 학습할 수 있도록 특징 맵의 채널을 재정렬하는 것.
크기가 작고 추론 시간이 빠름
2-3-10. SE-Net
2018년 도입된 CNN 아키텍처
입력의 전역정보를 기반으로 네트워크의 특징맵을 동적으로 재보정하여 CNN의 성능을 향상.
주 매커니즘의 한 유형인 sqeeze-and-excitation block을 사용하여 네트워크의 특징맵에 가중치를 부여
먼저, 특징 맵의 공간 차원을 줄여 전역 정보 벡터를 계산한 다음 이 벡터를 사용하여 가장 중요한 특징을 강조하는 방식으로 가중치를 부여함.
이미지분류 및 다양한 컴퓨터비전작업에서 최첨단성능을 달성(SOTA를 달성)
2-3-11. EfficientNet
2019년 도입된 CNN 아키텍처
컴퓨터비전에서 굉장히 높은 정확도를 유지하며 계산. 효율적으로 설계됨.
네트워크의 크기와 깊이를 쉽게 조정하여 다양한 입력 크기와 계산 제약 조건을 처리할 수 있는 확장 가능한 아키텍처를 사용함.
사전 정의된 스케일링 계수셋을 기반으로 네트워크의 차원을 조정하는 복합 스케일링 방법을 기반으로 정확도와 계산 효율성 간의 균형을 달성함.
이미지분류 및 다양한 컴퓨터비전작업에서 최첨단성능을 달성(SOTA를 달성)



