
14.RoBERTa를 활용한 NLI 실습
!pip install transformers
from transformers import pipeline, AutoTokenizer
classifier = pipeline(
'text-classification',
model='Huffon/klue-roberta-base-nli',
return_all_scores=True
)
tokenizer = AutoTokenizer.from_pretrained('Huffon/klue-roberta-base-nli')
tokenizer.sep_token
classifier(f'나는 악기를 연주하는 것을 좋아해. {tokenizer.sep_token} 나는 음악을 듣고 연주하는 것이 싫어.')
# ENTAILMENT: 함축 // NEUTRAL: 중의 // CONTRADICTION: 모순
classifier(f'여러 남성들이 축구를 하고 있어요.{tokenizer.sep_token}남자들은 스포츠를 좋아해')
classifier(f'여러 남성들이 축구를 하고 있어요.{tokenizer.sep_token} 어떤 남자들은 스포츠를 좋아해')
15. BART를 활용한 요약 실습
15-1. BART
reference
https://github.com/seujung/KoBART-summarization
GitHub - seujung/KoBART-summarization: Summarization module based on KoBART
Summarization module based on KoBART. Contribute to seujung/KoBART-summarization development by creating an account on GitHub.
github.com
OpenAI에서 개발한 자연어처리 딥러닝 모델 중 하나
Transformer 아키텍처를 기반으로 양방향 인코더-디코더 구조를 갖고 있음.
문장요약, 번역, 텍스트생성에 뛰어난 성능을 보여주는 모델.
기사를 요약하는 예제를 확인
!pip install -U transformers datasets pytorch-lightning==1.5.10 streamlit==1.2.0
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained('digit82/kobart-summarization')
model = BartForConditionalGeneration.from_pretrained('digit82/kobart-summarization')
text = """
1일 오후 9시까지 최소 20만3220명이 코로나19에 신규 확진됐다. 또다시 동시간대 최다 기록으로, 사상 처음 20만명대에 진입했다.
방역 당국과 서울시 등 각 지방자치단체에 따르면 이날 0시부터 오후 9시까지 전국 신규 확진자는 총 20만3220명으로 집계됐다.
국내 신규 확진자 수가 20만명대를 넘어선 것은 이번이 처음이다.
동시간대 최다 기록은 지난 23일 오후 9시 기준 16만1389명이었는데, 이를 무려 4만1831명이나 웃돌았다. 전날 같은 시간 기록한 13만3481명보다도 6만9739명 많다.
확진자 폭증은 3시간 전인 오후 6시 집계에서도 예견됐다.
오후 6시까지 최소 17만8603명이 신규 확진돼 동시간대 최다 기록(24일 13만8419명)을 갈아치운 데 이어 이미 직전 0시 기준 역대 최다 기록도 넘어섰다. 역대 최다 기록은 지난 23일 0시 기준 17만1451명이었다.
17개 지자체별로 보면 서울 4만6938명, 경기 6만7322명, 인천 1만985명 등 수도권이 12만5245명으로 전체의 61.6%를 차지했다. 서울과 경기는 모두 동시간대 기준 최다로, 처음으로 각각 4만명과 6만명을 넘어섰다.
비수도권에서는 7만7975명(38.3%)이 발생했다. 제주를 제외한 나머지 지역에서 모두 동시간대 최다를 새로 썼다.
부산 1만890명, 경남 9909명, 대구 6900명, 경북 6977명, 충남 5900명, 대전 5292명, 전북 5150명, 울산 5141명, 광주 5130명, 전남 4996명, 강원 4932명, 충북 3845명, 제주 1513명, 세종 1400명이다.
집계를 마감하는 자정까지 시간이 남아있는 만큼 2일 0시 기준으로 발표될 신규 확진자 수는 이보다 더 늘어날 수 있다. 이에 따라 최종 집계되는 확진자 수는 21만명 안팎을 기록할 수 있을 전망이다.
한편 전날 하루 선별진료소에서 이뤄진 검사는 70만8763건으로 검사 양성률은 40.5%다. 양성률이 40%를 넘은 것은 이번이 처음이다. 확산세가 계속 거세질 수 있다는 얘기다.
이날 0시 기준 신규 확진자는 13만8993명이었다. 이틀 연속 13만명대를 이어갔다.
"""
text = text.replace('\n', ' ') # 엔터키를 모두 띄어쓰기로 바꿔서 한줄로 만듦
raw_input_ids = tokenizer.encode(text)
print(raw_input_ids) # 한줄을 인코딩해서 만듦

input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id] # 시작토큰과 끝토큰을 붙여줌
print(input_ids)

summary_ids = model.generate(torch.tensor([input_ids]), num_beams=4, max_length=512, eos_token_id=1) # torch tensor로 변경 후 모델에 삽입함
print(summary_ids) # summary_ids: 요약한 내용에 대한 id값

tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True) # decode해서 요약한 값을 확인함

GitHub - seujung/KoBART-summarization: Summarization module based on KoBART
Summarization module based on KoBART. Contribute to seujung/KoBART-summarization development by creating an account on GitHub.
github.com
16. DistillBERT를 활용한 MRC실습
16-1. MRC(Machine Reading Comprehension)
주어진 질문에 정확한 답변을 추출하는 자연어 처리 작업
컴퓨터가 사람처럼 텍스트를 이해하고 추론하여 정보를 얻고 질문에 맞는 답변을 찾는 과정
!pip install -U transformers datasets scipy scikit-learn evaluate
import datasets
import random
import pandas as pd
from datasets import load_dataset, ClassLabel
from IPython.display import display, HTML # HTML로 화면에 출력
from transformers import AutoTokenizer, pipeline
raw_datasets = load_dataset('klue', 'mrc')
raw_datasets # train과 validation dataset의 확인

# 실제 data의 확인
raw_datasets['train'][0]

# 특정 항목만 가져오고 싶은 경우
print('context: ', raw_datasets['train'][0]['context'])
print('question: ', raw_datasets['train'][0]['question'])
print('answers: ', raw_datasets['train'][0]['answers'])

# validation에서의 특정 항목만 가져오고 싶은 경우
print('context: ', raw_datasets['validation'][0]['context'])
print('question: ', raw_datasets['validation'][0]['question'])
print('answers: ', raw_datasets['validation'][0]['answers'])

# dataset을 뿌려줄 함수 생성
def show_random_elements(dataset, num_examples=10): # dataset의 임의의 데이터 10개를 출력
picks =[]
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks: # 만약, pick한 data가 또 pick에 있는 데이터라면, 다시 pick함.
pick=random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items(): # dataset의 feature의 item만큼 반복함
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: type.names[i])
# label class를 string으로 변환시켜서 column에 적용
display(HTML(df.to_html()))
show_random_elements(raw_datasets['train'])
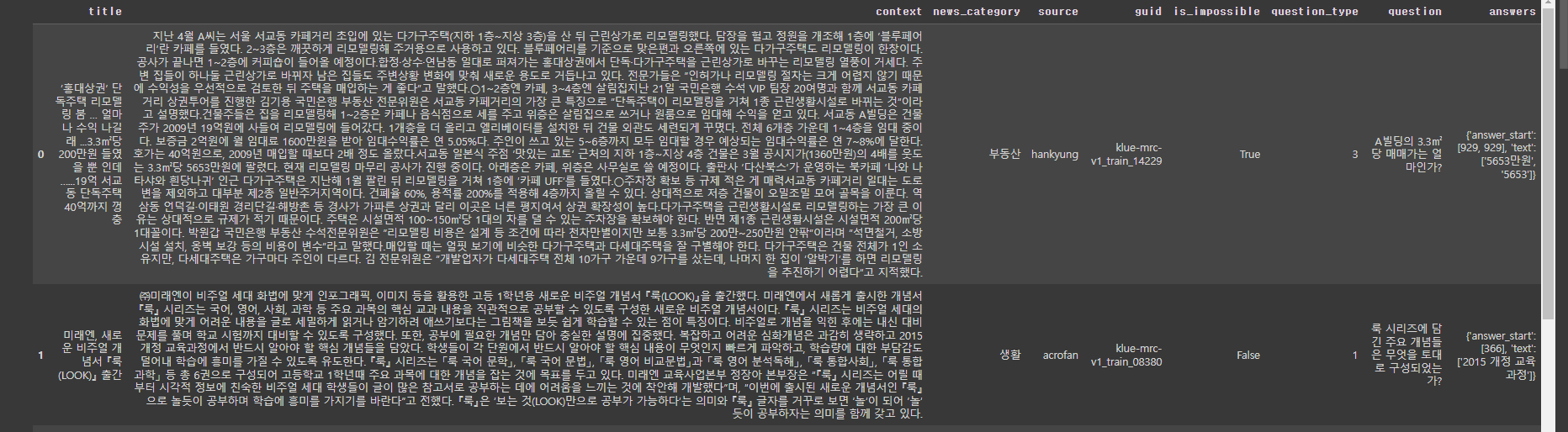
tokenizer = AutoTokenizer.from_pretrained('bespin-global/klue-bert-base-mrc')
context = raw_datasets['train'][0]['context']
question = raw_datasets['train'][0]['question']
inputs = tokenizer(question, context)
tokenizer.decode(inputs['input_ids'])

# tokenizer에 옵션을 줌
inputs = tokenizer(
question,
context,
max_length=100,
truncation='only_second', # 두 문장이 있는 경우 두번째 문장을 삭제함.
stride=50, # 삭제 시 겹치는 부분을 50
return_overflowing_tokens=True,
return_offsets_mapping=True
)
for ids in inputs['input_ids']:
print(tokenizer.decode(ids))
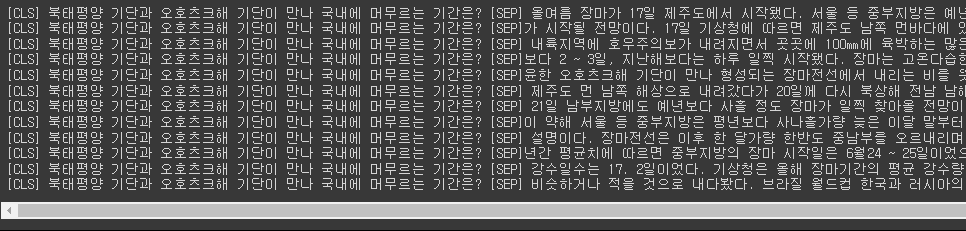
inputs.keys() # return된 옵션들을 확인

inputs['input_ids'][0][:10]

inputs['token_type_ids'][0][:10]

inputs['overflow_to_sample_mapping']

print(inputs['offset_mapping'])

question_answerer = pipeline('question-answering', model='domyoung/squad-test')
question_answerer (question=question, context=context)
context = '''
갤럭시를 사용하며, 정말 특이하게 딩굴 키보드를 사용한다. 가족이 모두 체육인 집안이다. 아버지가 유도선수, 어머니가 육상선수 출신이다. 그러니 지금의 운동신경은 부모님으로부터 물려받은 것이라고 봐도 된다. 그의 형 또한 명지대학교에서 골키퍼로 활약 중이라고 한다. 축구를 시작한 계기가 공부가 하기 싫어서였다고 한다. 본래 초등학교 시절의 포지션은 지금처럼 센터백이 아니라 공격수 출신이었다고 한다. 한때 SNS를 매우 활발히 했다. 안 끼는 곳이 없다 싶을 정도로 다른 선수들 글에 댓글도 열심히 남기는 편이었다. 상당히 재치있는 글도 많이 올렸는데 시비거는 팬과 키배를 벌이거나 도발해오는 이란 팬에게 노빠꾸로 극딜을 먹인 일이 유명하다. 그러나 이후 본인이 이런저런 일로 많이 데이다 보니 지금은 예전보다 자제하고 있다. 최강희 감독을 영입한 텐진 취안젠에서 김신욱과 함께 영입 대상이 되었다.# 이에 팬들은 당연히 김신욱이라면 모를까, 김민재의 중국 진출은 절대 반대하고 있었고, 이 와중에 유망주 중국화 시킬 셈이냐며 최강희 감독 또한 비난을 받았다. 그러나 취안젠이 망했고[23], 최강희도 계약 해지를 당해서 김민재 영입전은 그렇게 흐지부지됐다. 여배우 신도현과 친한 것으로 보인다. 김민재가 드라마 땐뽀걸즈 촬영 현장에 신도현을 위해 커피차를 보냈고 인스타그램에서도 댓글을 남기는 등 매우 친밀한 사이다. 인터뷰에 의하면 베이징 생활은 대체로 만족했지만, 음식에 들어가는 고수에 적응하는 것은 좀 힘들었다고 한다. 베이징 궈안 이적 후 ACL에서 유독 K리그 구단만 만나면 실수를 하는 애국자 기믹(...)이 제대로 생겼다. 2019년 친정 전북과의 조별 예선에서는 김민재답지 않은 빌드업 미스로 전북에게 선취골을 내주고 2020년 조별 예선 FC 서울전과 8강전 울산 현대전에서는 핸드볼 파울을 저질러 PK를 내줬다. 베이징 궈안에서 같은 동료였던 헤나투 아우구스투에게 수비하는 방법을 보면서 많이 배웠다고 한다.# 예전에 머리 스타일을 짧게 잘라 축구 유튜버 채널에 출연했다. 당시 헤어 스타일이 군대 입영하는 병사처럼 짧아진 이유에 대해 밝히길 중국 리그 시절 현지에서 커트를 했을 때 엉망이 돼서 차라리 잘됐다 생각하고 그냥 밀어버렸다고 한다. 박주호와 장현수에게 수비수에 대한 지능적 플레이를 많이 배웠다고 한다. 김영권에게도 많이 배우긴 했지만 그는 즉석에서 물어볼 수 있기 때문에 많이 따라다니진 않았다고 말했다. 매사에 완벽주의자라서 한 번이라도 수비를 실수하면 정말 화가 많이 나고 스스로 용납이 안 된다고 한다. 자신이 축구선수가 안 됐으면 뭘 했을거라 생각하냐는 질문에 "집이 통영이라서 수산업을 했을 것 같다" 라고 이야기를 했었다. 대표팀에선 주로 황희찬, 나상호, 황인범과 함께 96라인으로 불린다. 롤모델은 처음엔 세르히오 라모스와 페페였지만 최근에는 다요 우파메카노로 바뀌었다고 한다.그런데 우파메카노가 두살 더 어리다. 둘의 플레이스타일도 꽤 비슷한데, 뇌지컬과 피지컬이 동시에 된다는 점과 센터백치고 발재간이 좋다는 점이 공통점. 결국 둘은 같은 팀에서 뛰게 되었다. 프리미어 리그 무대에선 언젠가는 꼭 뛰어보고 싶다고 밝혔다. 유튜브에서는 주로 자신의 스폐셜 영상을 많이 본다고 한다. 닮은 꼴로는 김신영이 주로 언급되는데 옛날부터 김신영을 닮았다는 말을 많이 들었다고 한다. 최근에는 허각, 그리고 가수 양다일을 닮았다는 이야기를 많이 듣는다. 그래서 양다일이 노래하는 유튜브 영상에 "김민재 선수 앞으로 나폴리에서도 좋은 활약 보여주세요!", "김민재 노래도 잘하네?" 같은 개드립스러운 댓글이 있었을 정도였다.# 그리고, 김민재 본인도 고알레 유투브 채널에서 이 댓글을 실제로 봤다고 한다.# 하지만, 김민재와 가장 닮은 사람은 다름아닌 K리그에서 활약하는 정동식 축구심판인데, 나이를 고려하면 김민재가 정동식 심판을 닮은 것이긴 하다. 거대한 몸집과 큰 키에 상반되는 귀여운 얼굴을 가져 은근히 여성팬들이 많다.
'''
question = '자신이 축구선수가 안 됐으면 뭘 했을거라 생각하는지?'
question_answerer (question=question, context=context)

17.KLUE
17-1. KLUE의 개요
한국어, 자연어 이해 평가 데이터셋
한국어 언어모델의 공정한 평가를 위한 목적으로 8개의 종류가 포함된 공개 데이터셋
- 뉴스 헤드라인 분류
- 문장 유사도 비교
- 자연어 추론
- 개체명 인식
- 관계 추출
- 형태소 및 의존 구문 분석
- 기계 독해 이해
- 대화 상태 추적
한국어 언어 모델의 공정한 성능 비교를 위해 평가 시스템을 구축함.
17-2. 학습 데이터
광범위한 주제와 다양한 스타일을 포괄하기 위해 다양하며 공개적으로 사용 가능한 한국어 말뭉치를 수집.
약 62GB 크기의 최종 사전 학습 코퍼스를 구축.
1) MODU: 국립국어원에서 배포하는 한국어 말뭉치 모음.
2) CC-100-Kor: CC-100은 CC-Net을 사용하여 대규모 다국어 웹 크롤링 코퍼스를 구축.
3) 나무위키: 나무위키는 한국어 웹 기반 백과사전으로, 위키백과와 유사하지만 자유로운 형식임.
4) 뉴스스크롤: 2011년부터 2020년까지 발행한 12,800,000개의 뉴스 기사로 구성되어있으며,
뉴스 집계 플랫폼에서 수집.
5) 국민청원: 사회적 이슈에 대한 행정 조치를 요청하는 청와대 국민청원모음
17-3. KLUE-TC task
Topic Classification. 주어진 뉴스 표제가 어떤 토픽에 속하는지를 분류해줌
!pip install -U transformers datasets scipy scikit-learn
!pip install accelerate -U
import datasets
import random
import numpy as np
import pandas as pd
from datasets import load_dataset, ClassLabel, load_metric
from IPython.display import display, HTML
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification, TrainingArguments, Trainer
model_checkpoint = 'klue/roberta-base'
batch_size = 64
task = 'ynat' # task의 list: ['ynat', 'sts', 'nli', 'ner', 're', 'dp', 'mrc', 'wos']
datasets = load_dataset('klue', task)

# datasets 확인
datasets

# datasets의 train을 10개정도만 가져오기
datasets['train'][:10]

# dataset을 뿌려줄 함수 생성
def show_random_elements(dataset, num_examples=10): # dataset의 임의의 데이터 10개를 출력
picks =[]
for i in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks: # 만약, pick한 data가 또 pick에 있는 데이터라면, 다시 pick함.
pick=random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items(): # dataset의 feature의 item만큼 반복함
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
# label class를 string으로 변환시켜서 column에 적용
display(HTML(df.to_html()))
show_random_elements(datasets['train'])
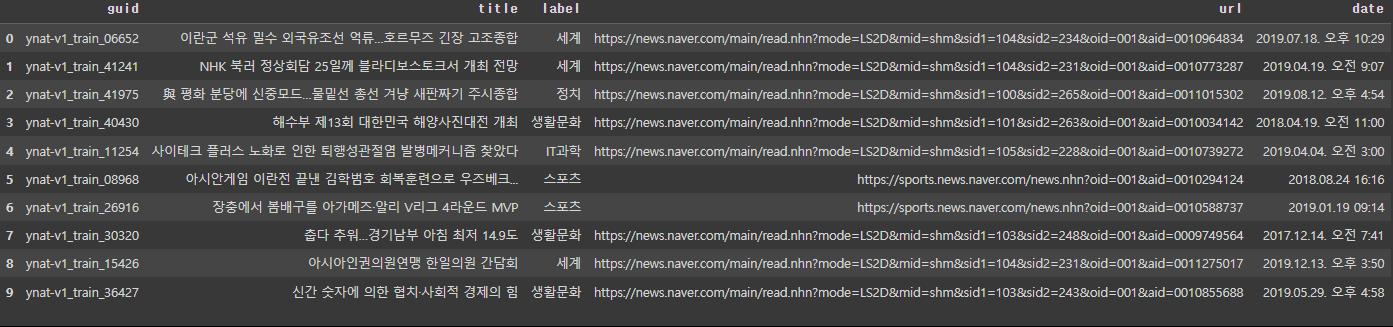
metric = load_metric('f1') # f1 score를 metric으로 설정할 수 있음

# 예측값과 label을 임의로 뽑아옴
fake_preds = np.random.randint(0, 2, size=(64,))
fake_labels = np.random.randint(0, 2, size=(64,))
fake_preds, fake_labels

metric.compute(predictions=fake_preds, references=fake_labels)

# 학습에 이용할 tokenizer 객체 생성
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
# 임의의 기사제목을 가져와서 토큰화함
tokenizer('신간 아름답거나 혹은 위태롭거나')
# input_ids: 0에서 시작해서 2로 끝남

# CLS가 0번, EOS가 2번인것을 알 수 있음.
print(tokenizer.cls_token_id, tokenizer.eos_token_id)

tokenizer

# train의 인덱스 0번에 해당하는 제목을 가져옴
print(f"sentence 1: {datasets['train'][0]['title']}")

# roberta 모델을 이용하기 위해 title을 뽑아내 tokenizer후 return해주는 함수를 생성
def preprocess_function(examples):
return tokenizer(
examples['title'],
truncation = True,
return_token_type_ids = False
)
preprocess_function(datasets['train'][:5])

encoded_datasets = datasets.map(preprocess_function, batched=True)
# batched=True: batch단위로 병렬처리 여부

# 토큰을 이용하여 모델의 사전학습
num_labels = 7 # 기사의 class가 총 7개이기 때문에 7가지로 분류함
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)

# 예측객체를 입력하면 class별 예측결과를 확인하는 함수 생성
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1) # 가장 높은 확률을 뽑아냄
return metric.compute(predictions=predictions, references=labels, average='macro')
# references=labels: f1 score의 차이를 보여줌
metric_name = 'f1' # metric name은 f1 score
args = TrainingArguments(
'test-tc',
evaluation_strategy='epoch',
save_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size = batch_size,
per_device_eval_batch_size = batch_size,
num_train_epochs = 5, # epoch을 5회 실행
weight_decay=0.01, # 0.01(1%): L2 정규화의 가중치
load_best_model_at_end = True, # 최적의 값이 출력되었을 때 epoch을 정지
metric_for_best_model=metric_name
)
# trainer 객체 생성
trainer = Trainer(
model,
args,
train_dataset = encoded_datasets['train'],
eval_dataset=encoded_datasets['validation'],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# 학습
trainer.train()
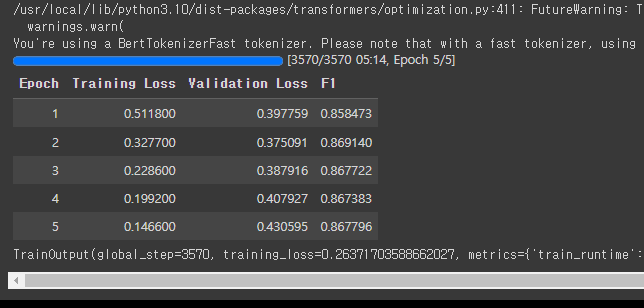
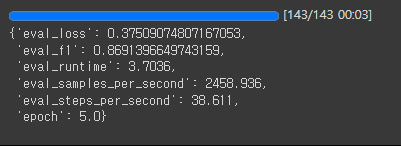
# 검증
trainer.evaluate()
classifier = pipeline(
'text-classification',
model='./test-tc/checkpoint-1428',
return_all_scores=True
)

classifier('왓츠앱稅 230원에 성난 레바논 민심…총리사퇴로 이어져종합2보')
# 기사제목만 보고 정상적으로 label4인 세계에 대한 분류를 찾을 수 있음.
* 0 (IT과학)
* 1 (경제)
* 2 (사회)
* 3 (생활문화)
* 4 (세계)
* 5 (스포츠)
* 6 (정치)



