
11. BERT를 활용한 단어 추론 실습
허깅 페이스(Hugging Face)

트랜스포머(transformer)를 기반으로 다양한 모델과 학습데이터, 학습방법을 구현해놓은 모듈.
질의응답, 텍스트분류, 텍스트요약, 개체명인식, 텍스트생성, 번역, 언어모델에 사용됨.
!pip install transformers
import torch
from transformers import BertTokenizer, BertModel, BertForMaskedLM
KLUE(Korean Language Understanding Evaluation)
카카오에서 개발한 한국어 자연어 이해를 평가 목적으로 개발된 벤치마크 데이터셋과 모델.(한국형 BERT)
KLUE는 한국어 문장에 대한 다양한 자연어 처리(NLP) 작업을 수행할 수 있는 모델을 구축하는 데 도움을 줌.
KLUE는 문장 분류, 감성 분석, 개체명 인식, 의미역 결정 등 다양한 자연어 처리 작업을 포함하는
8개의 서브 태스크로 구성되어 있음.
KLUE 데이터셋은 실제로 수동으로 레이블링된 다양한 종류의 한국어 문장으로 구성되어 있으며,
이를 사용하여 모델의 성능을 평가할 수 있음.
사전훈련(pre-training) 및 다양한 작업에 대해 세부 조정(fine-tuning)하는 과정을 통해 학습을 함.
tokenizer = BertTokenizer.from_pretrained('klue/bert-base')
text = '[CLS] 이순신은 누구입니까? [SEP] 16세기 말 조선의 명장이자 충무공이며 임진왜란 및 정유재란 당시 조선 수군을 지휘했던 제독이다 [SEP]'
tokenized_text = tokenizer.tokenize(text)
print(tokenized_text)

# 16번 인덱스의 단어를 MASK로 마스킹함
masked_index = 16
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)

# 인덱스로 변환
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
print(indexed_tokens)

# seperate 기준으로 앞의 8개가 1개 문장이므로 모두 0으로 채워줌.
segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1,1,1,1,1,1,1,1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# 모델을 학습
model = BertModel.from_pretrained('klue/bert-base')
model.eval() # 평가모드로 전환하여 추가학습을 하지 않음
# MASK를 씌운 후 pre-trained를 진행
model = BertForMaskedLM.from_pretrained('klue/bert-base')
model.eval()
# gpu로 변경
tokens_tensor = tokens_tensor.to('cuda')
segments_tensors = segments_tensors.to('cuda')
model.to('cuda')
# gradient를 돌리지 않는 구간 생성
with torch.no_grad():
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
encoded_layers = outputs[0]
# masked_index의 값 출력
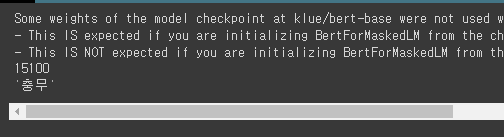
predicted_index = torch.argmax(encoded_layers[0,masked_index]).item()
print(predicted_index)
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0] # convert_ids_to_token(): index번호를 다시 token으로 변환
print(predicted_token)
12. ELECTRA를 활용한 NER 실습
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately):
2020년 공개된 생성기와 구분기 두 개의 모델을 사용하여 pre-training과 fine-tuning을 수행하는 언어 모델.
GPT와 같은 사전 학습 언어 모델과 달리 사전 학습 단계에서 생성기로부터 언어 모델을 학습하지 않고,
구분기를 학습시키는 방식을 사용.
ELECTRA의 핵심 개념은 MLM 대신 대체 언어 모델(RTD; Replaced Token Detection)을 사용하는 것임. ELECTRA는 토큰 중 일부를 랜덤하게 마스킹하고, 마스킹된 위치에서 실제 토큰을 대체함.
그런 다음 구분기는 이 대체된 토큰을 실제로 구분하는 작업을 수행함.
이러한 방식은 더 효율적인 학습을 가능하게 함.
ELECTRA는 사전 학습된 언어 모델로 사용되며, 다양한 자연어 처리 작업에 대해 fine-tuning될 수 있음. ELECTRA는 BERT와 비교하여 더 효율적인 학습과 더 좋은 성능을 제공하는 것으로 알려져 있음.
Transformer 아키텍처를 사용하여 자연어처리 문제를 수행하는데 사용
GAN의 개념을 자연어처리에 적용한 것
GAN(Generative Adversarial Network)과 ELECTRA의 관련성:
ELECTRA에서 생성자는 토큰 대체를 수행하고, 구분자는 생성자의 작업을 판별하여 언어 모델을 훈련시킴. 이러한 구조는 ELECTRA가 사전 학습과 fine-tuning 단계에서 보다 효율적인 학습과 더 좋은 성능을 제공할 수 있게 함. |
!pip install transformers
# text를 받아옴
!wget https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt
!wget https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
# 해당 파일의 일부만 확인해볼 예정
!head ratings_train.txt
import pandas as pd
import torch
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
from transformers import AutoTokenizer, ElectraForSequenceClassification, AdamW
from tqdm.notebook import tqdm # 반복문 돌릴 때 사용
# gpu 사용
device = torch.device('cuda')
NSMC 데이터셋(네이버 영화평점 관련 데이터셋) 을 이용할 예정
batch_size로 쪼개어 학습하기 위해 Dataset을 DataLoader에 넣어 사용.
데이터셋을 class로 만들어 모듈화 하여 사용하는 것을 추천함
→ 확장성, 유지보수면에서 모듈단위가 더욱 유리하기 때문.
class NSMCDataset(Dataset):
def __init__(self, csv_file):
self.dataset = pd.read_csv(csv_file, sep='\t').dropna(axis=0) # tab으로 구분시킨 후 행에서 dropna로 삭제. 이후 dataset에 저장
self.dataset.drop_duplicates(subset=['document'], inplace=True) # 중복 제거
self.tokenizer = AutoTokenizer.from_pretrained("monologg/koelectra-small-v2-discriminator") # 이것을 가져다 사전학습시켜 tokenizer하겠음.
# self.를 쓰는 이유: 다른 메소드에도 똑같이 사용할 수 있게 해줌. (예: __getitem__에서 self.dataset을 사용)
def __len__(self): # '__' : 스페셜메소드라 부름
return len(self.dataset)
def __getitem__(self, idx): # getitem(): 인덱싱할 수 있는 메소드. 관례처럼 많이 사용함
row = self.dataset.iloc[idx, 1:3].values # index의 1,2의 2개 열의 값을 가져와서 row에 저장
text = row[0] # 1번 열은 text
y = row[1] # 2번 열은 y
inputs = self.tokenizer(
text,
return_tensors='pt', # pytorch tensor로 return해주겠다는 의미
truncation=True, # truncation(): 글자수 초과 시 자름
max_length=256,
pad_to_max_length=True, # 256자를 채우지 않으면 나머지 공란을 pad로 채움
add_special_tokens=True
)
input_ids = inputs['input_ids'][0]
attention_mask = inputs['attention_mask'][0]
return input_ids, attention_mask, y
# train과 test 데이터셋의 객체 생성
train_dataset = NSMCDataset('ratings_train.txt')
test_dataset = NSMCDataset('ratings_test.txt')

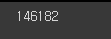
# dataset이 제대로 동작하는지를 test
len(train_dataset) # 146182개의 data가 존재
# getitem이 제대로 동작하는지를 test
train_dataset[0]
# 모델을 생성.
model = ElectraForSequenceClassification.from_pretrained('monologg/koelectra-base-v3-discriminator').to(device)
model
# model에 text와 attention_mask를 넣고 학습
# model에 넣을 때는 2차원 데이터로 넣어야 함.
epochs = 0
batch_size = 16
optimizer = AdamW(model.parameters(), lr=5e-6)
# AdamW(): 기존의 Adam보다 가중치 감쇠를 더 효과적으로 처리하는 방식을 도입하여 성능을 개선함.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
losses = []
accuracies = []
for i in range(epochs):
total_loss = 0.0
correct = 0
total = 0
batches = 0
model.train()
for input_ids_batch, attention_masks_batch, y_batch in tqdm(train_loader):
optimizer.zero_grad()
y_batch = y_batch.to(device)
y_pred = model(input_ids_batch.to(device),
attention_mask=attention_masks_batch.to(device))[0]
loss = F.cross_entropy(y_pred, y_batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(y_pred, 1)
correct += (predicted == y_batch).sum()
total += len(y_batch)
batches += 1
if batches % 100 == 0:
print('Batch Loss:', total_loss, 'Accuracy:', correct.float() / total)
losses.append(total_loss)
accuracies.append(correct.float() / total)
print('Train Loss:', total_loss, 'Accuracy:', correct.float() / total)
# 오래걸려서 취소
model.eval()
test_correct = 0
test_total = 0
for input_ids_batch, attention_masks_batch, y_batch in tqdm(test_loader):
y_batch = y_batch.to(device)
y_pred = model(input_ids_batch.to(device),
attention_mask=attention_masks_batch.to(device))[0]
_, predicted = torch.max(y_pred, 1)
test_correct += (predicted == y_batch).sum()
test_total += len(y_batch)
print('Accuracy:', test_correct.float() / test_total)
# 오래걸려서 취소
from transformers import pipeline
classifier = pipeline(
'text-classification',
model='monologg/koelectra-base-v3-discriminator',
return_all_scores=True
)
classifier('아 더럽게 재미없네')
부정이면 0, 긍정이면 1

from transformers import AutoModelForSequenceClassification, TextClassificationPipeline
tokenizer = AutoTokenizer.from_pretrained('jaehyeong/koelectra-base-v3-generalized-sentiment-analysis')
model = AutoModelForSequenceClassification.from_pretrained('jaehyeong/koelectra-base-v3-generalized-sentiment-analysis')
sentiment_classifier = TextClassificationPipeline(tokenizer=tokenizer, model=model)
review_list = [
'아 더럽게 재미없네'
]
for idx, review in enumerate(review_list):
pred = sentiment_classifier(review)
print(f'{review}\n >> {pred[0]}')

부정이라 판단하여 0이 출력될 확률이 98%임을 나타냄
13. GPT3을 활용한 생성 실습
KakaoBrain KoGTP 예제 관련 블로그
[kogpt] 🧐 한국어 생성 GPT-3 : 명문가 납시오!
😎 지난 BentoML 글을 작성하면서, 언어 생성 모델에 재미를 느껴버렸습니다 :)
velog.io
GPT 디코딩 전략 관련 참고 블로그
https://littlefoxdiary.tistory.com/46
!pip install transformers accelerate
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GPTJForCausalLM
tokenizer = AutoTokenizer.from_pretrained('MrBananaHuman/kogpt_6b_fp16', # 특정 토큰을 등록
bos_token='[BOS]', # 처음
eos_token='[EOS]', # 끝
unk_token='[UNK]', # 알수없음
pad_token='[PAD]', # 여백채움
mask_token='[MASK]')# 가림
# 모델 객체 생성
model = GPTJForCausalLM.from_pretrained('MrBananaHuman/kogpt_6b_fp16',
pad_token_id=tokenizer.eos_token_id,
torch_dtype='auto',
low_cpu_mem_usage=True) # 메모리 아껴씀
model.to('cuda', non_blocking=True) # 비동기통신(병렬처리) 요청
model.eval()
13-1. Beam Search 기반으로 생성
Beam Search는 Greedy Search 방법에서 시간복잡도를 조금 포기하고 정확도를 높이기 위해 제안된 방법.
가장 좋은 디코딩 방법은 가능한 모든 경우의 수를 고려해서 누적 확률이 가장 높은 경우를 선택하는 것이나,
이는 시간복잡도 면에서 사실상 불가능한 방법임.
Beam Searchh는 이러한 Greedy Search와 모든 경우의 수를 고려하는 방법의 타협점임.
해당 시점에서 유망하다고 판단되는 빔 K개를 골라서 진행하는 방식으로
Greedy Search가 놓칠 수 있는 시퀀스를 찾을 수 있다는 장점이 있으나,
시간복잡도 면에서는 더 느리다는 단점이 있음.
또한 Beam의 갯수(num_beam)를 얼마로 설정하냐에 따라서도 결과와 수행시간이 달라지기 때문에
적절한 갯수를 찾는 것 또한 중요함.
prompt = '야! 너는 AI지? 정말로 말을 알아듣니?'
with torch.no_grad():
tokens = tokenizer.encode(prompt, return_tensors='pt').to(device='cuda', non_blocking=True)
gen_tokens = model.generate(
tokens,
max_length=100,
num_beams=5, # 1보다 큰 값을 설정해야함
no_repeat_ngram_size=2, # ngram: 연속적인 n개의 단어 // 2-gram의 어구가 반복되지 않도록 설정
num_return_sequences=5, # 5개의 문장을 return
early_stopping=True # EOS 토큰이 나오면 생성을 중단
)
generated = tokenizer.batch_decode(gen_tokens)[0]
print(generated)
13-2. Sampling 기반으로 생성
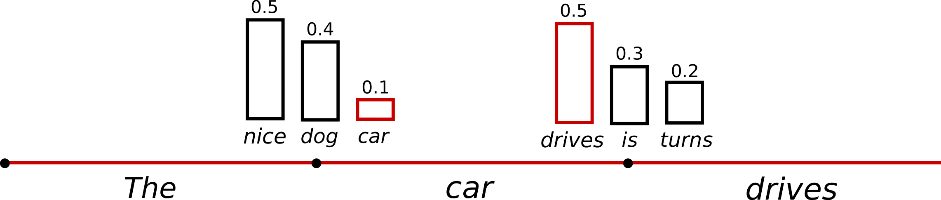
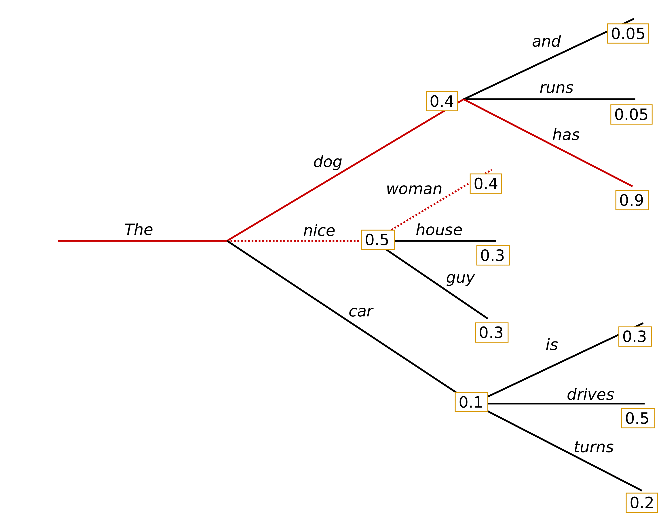
Sampling은 디코딩 방법에 랜덤성을 추가하는 대표적인 decoding 전략임.
위의 그림을 예로 설명하자면, 네모 상자 위에 적힌 숫자는 각 토큰의 해당 시점 t의 확률임.
nice는 0.5, dog은 0.4, car는 0.1임. greedy search라면 바로 nice를 선택하고 이어나가겠지만 sampling은 이 확률을 그대로 선택될 확률로 사용합니다. 즉, nice라는 토큰이 선택될 확률을 0.5로 줌으로써 다른 토큰들(dog, car)이 선택될 수 있는 랜덤성을 부여하는 방법.
prompt = '야! 너는 AI지? 정말로 말을 알아듣니?'
with torch.no_grad():
tokens = tokenizer.encode(prompt, return_tensors='pt').to(device='cuda', non_blocking=True)
gen_tokens = model.generate(
tokens,
max_length=100,
do_sample=True, # 샘플링 전략을 사용하겠다는 의미
top_k = 50, # 확률 순위가 50위 밖인 토큰은 샘플링에서 제외
top_p = 0.95, # 누적 확률이 95%인 후보집합에서만 생성
temperature = 0.75, # 낮으면 기존 단어를 재활용할 확률이 높고, 높으면 random 확률이 증가함.
num_return_sequences = 3 # 3개의 결과를 디코딩함
)
generated = tokenizer.batch_decode(gen_tokens)[0]
print(generated)
13-2-1. Top-k Sampling
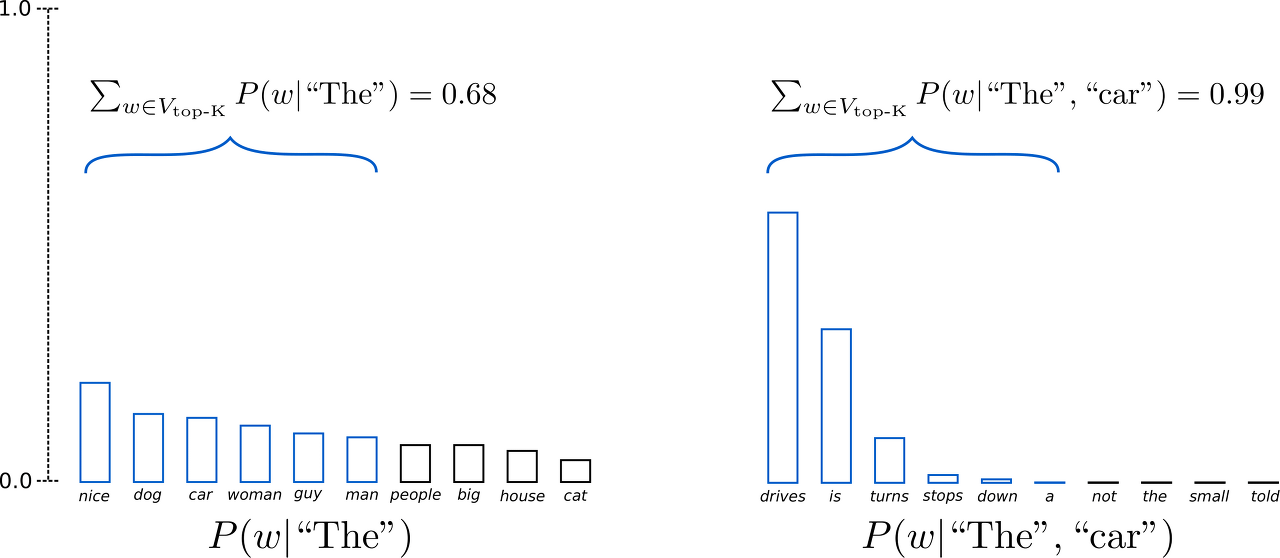
Sampling 방법을 약간 개조한 전략. 다음 토큰 선택시,
확률이 높은 K개의 토큰들만으로 한정해서 Sampling을 진행하는 방식.
이 방법은 모델의 창의성을 저하할 수 있다는 단점을 가지고 있음.
13-2-2. Top-p Sampling
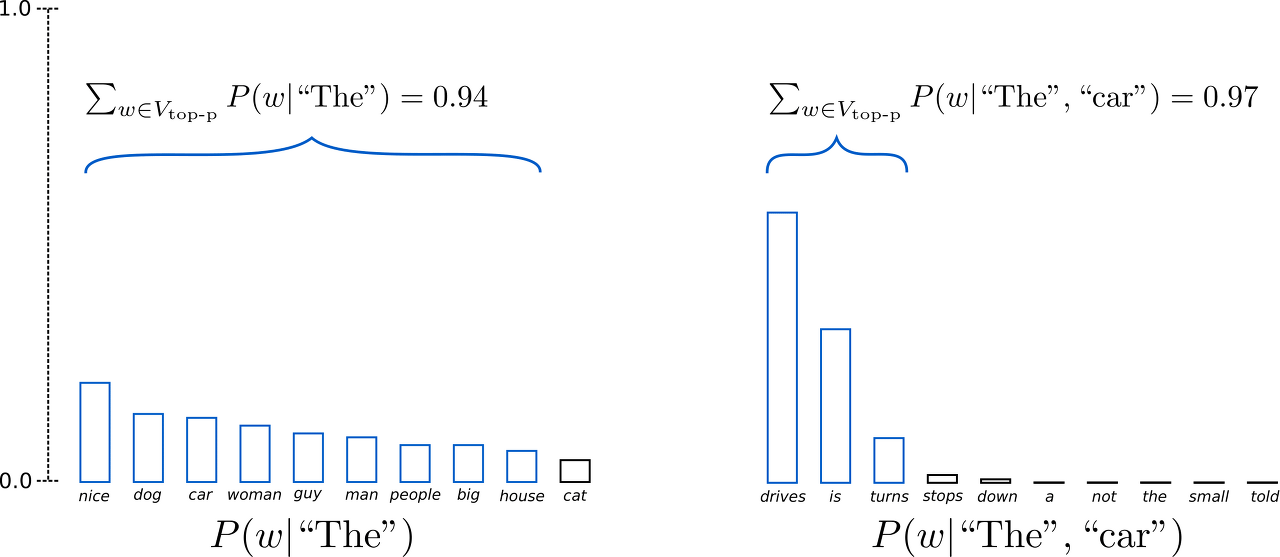
Top-k Sampling의 문제점을 개선하기 위해 제안된 방법.
확률이 높은 K개의 토큰으로부터 샘플링을 하지만,
누적 확률이 p 이상이 되는 최소한의 집합으로부터 샘플링을 하게 하는 전략.
이론 상으로는 top-p가 top-k보다 좋아보이지만, 두 전략 모두 사용해보면서 결과를 비교해보는게 가장 좋음.



