
1. 데이터 전처리 프로파일링
!pip install -U pandas-profiling
import pandas as pd
import pandas_profiling
data = pd.read_csv('/content/spam.csv', encoding='latin1')
data[:5]
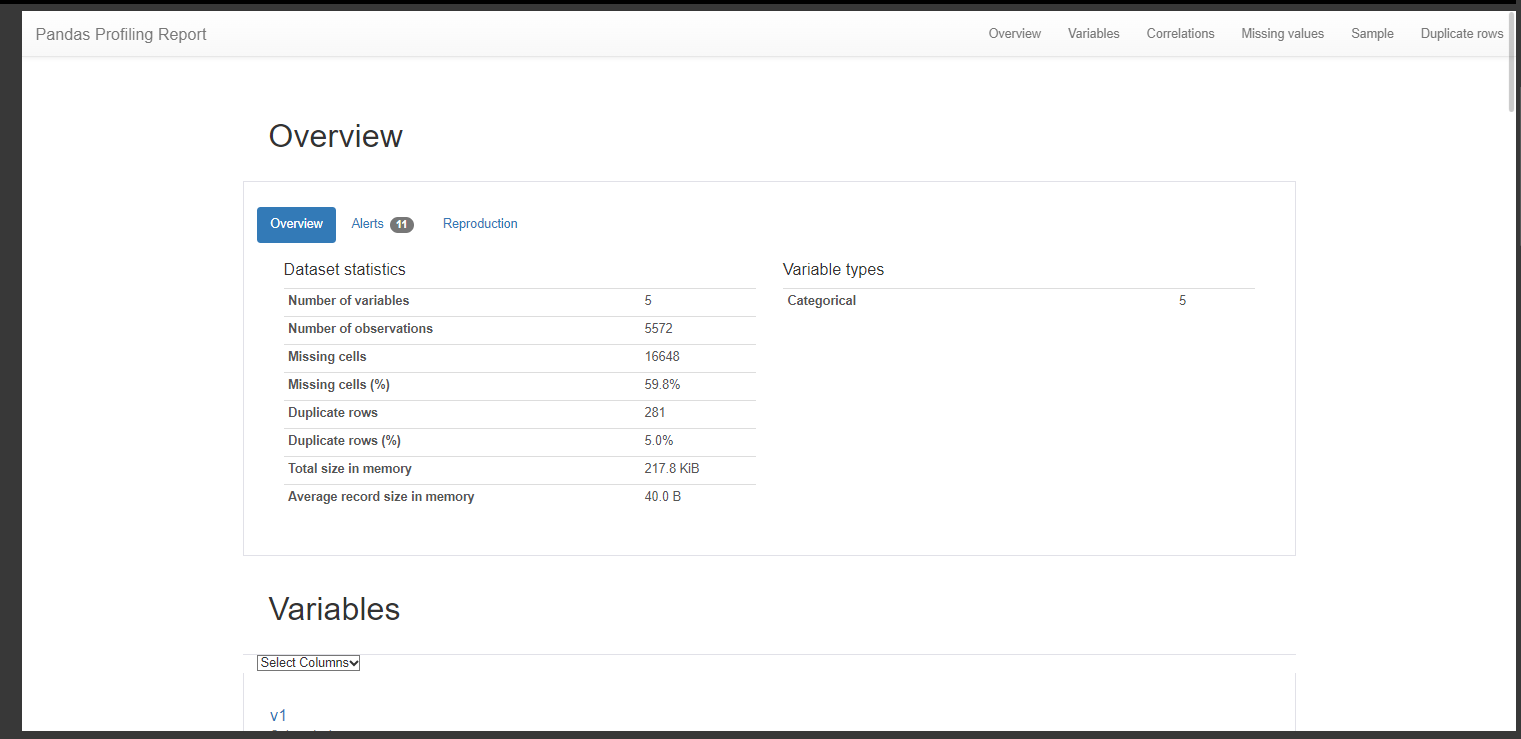
# 리포트 파일 생성
pr = data.profile_report()
pr.to_file('./pr_report.html')
pr
2. 단어 토큰화
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
import nltk
nltk.download('punkt')
print('단어 토큰화1: ', word_tokenize("Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is as cherry as cherry goes for a pastry shop."))
word_tokenize는 Don't를 Do와 n't로 분리하였으며, Jone's는 Jone과 's로 분리함
print('단어 토큰화2: ', WordPunctTokenizer().tokenize("Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is as cherry as cherry goes for a pastry shop."))

WordPunctTokenizer는 구두점을 별도로 분류하는 특징을 가짐.
word_tokenize와는 달리 Don't를 Don과 ', t 3가지로 분리하였으며, 마찬가지로 Jone's를 Jone, ', s로 분리함.
print('단어 토큰화3: ', text_to_word_sequence("Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is as cherry as cherry goes for a pastry shop."))

keras의 text_to_word_sequence는 기본적으로 모든 알파벳을 소문자로 바꾸면서 마침표나 컴마, 느낌표
등의 구두점을 제거하지만 어퍼스트로피( ' )는 보존함.
3. 표준 토큰화
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. It doesn't have a food chain or restaurant of their own,"
print('트리뱅크 워드토크나이저 : ', tokenizer.tokenize(text))

from nltk.tokenize import sent_tokenize
text = "His barber kept his word. But keeping such a huge secret to himself was driving me crazy. Finally, the barber went up a mountain and almost to the edge of a cliff. He dug a hole in the midst of some reeds. He looked about, to make sure no one was near."
print('문장 토큰화1 : ', sent_tokenize(text))

4. 문장 토큰화
!pip install kss
import kss
text = "딥 러닝 자연어 처리가 재미있기는 합니다. 그런데 문제는 영어보다 한국어로 할 때 너무 어렵습니다. 이제 해보면 알걸요?"
print('한국어 문장 토큰화 : ',kss.split_sentences(text))

from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
import nltk
nltk.download('averaged_perceptron_tagger')
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
print('단어 토큰화:', tokenized_sentence)
print('품사 태깅:', pos_tag(tokenized_sentence))

!pip install konlpy
from konlpy.tag import Okt
from konlpy.tag import Kkma
okt = Okt()
kkma = Kkma()
print('OKT 형태소 분석:' , okt.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 품사 태깅:' , okt.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('OKT 명사 추출:' , okt.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))

print('꼬꼬마 형태소 분석:' , kkma.morphs("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('꼬꼬마 품사 태깅:' , kkma.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))
print('꼬꼬마 명사 추출:' , kkma.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))




