
7. ELMo (Embedding from Language Model)
2018년에 제안된 새로운 워드 임베딩 방법론.
ELMo라는 이름은 세서미 스트리트라는 미국 인형극의 캐릭터 이름이기도 한데, BERT나 Big Bird라는 NLP 모델 또한 ELMo에 이어 세서미 스트리트의 캐릭터의 이름을 사용함.
ELMo는 Embeddings from Language Model의 약자로, 해석하면 '언어 모델로 하는 임베딩'임.
가장 큰 특징은 사전 훈련된 언어 모델(Pre-trained language model)을 사용한다는 점.
7-1. 기존 워드 임베딩의 한계
Bank라는 단어를 생각해보자.
Bank Account(은행 계좌)와 River Bank(강둑)에서의 Bank는 전혀 다른 의미를 가지는데,
Word2Vec이나 GloVe 등으로 표현된 임베딩 벡터들은 이를 제대로 반영하지 못한다는 단점이 있음.
예를 들어서 Word2Vec이나 GloVe 등의 임베딩 방법론으로
Bank란 단어를 [0.2, 0.8, -1.2]라는 임베딩 벡터로 임베딩하였다고 하면,
이 단어는 Bank Account(은행 계좌)와 River Bank(강둑)에서의 Bank는 전혀 다른 의미임에도 불구하고
두 가지 상황 모두에서 [0.2 0.8 -1.2]의 벡터가 사용됨.
7-2. ELMo의 특징
ELMo는 크게 두 가지의 특징이 있음.
하나는 사전 훈련된(Pre-trained) 단어 표현법이라는 것과
다른 하나는 고품질 단어 표현법(문법, 문맥 내 의미, 문장의 다의성)의 이상적인 모델링이라는 것임.
ELMo는 각 단어에 고정된 embedding을 이용하는 대신 먼저 전체 문장을 봄.
그리고 특정한 task로 학습된 양방향성(bi-directional) LSTM을 이용하여 각 단어의 embedding을 생성함.
LSTM은 거대한 데이터셋에서 학습되며, 자연어를 처리하는 다른 모델에서 하나의 부분으로 이용할 수 있음.
ELMo의 단어 표현은 문장을 구성하는 각각의 단어 토큰이 전체 입력 문장,
즉 문맥을 고려하는 정보들을 표현 내에 압축한다는 점에서 전통적인 단어 임베딩과 다름.
ELMo의 단어 벡터는 LSTM의 각 layer에서 나온 hidden representation들을 종합한 표현.
LSTM(Long Short-Term Memory): 장기 단기 메모리의 약어로, 순환 신경망(Recurrent Neural Network)의 한 종류. LSTM은 RNN의 변종으로, 주로 시계열 데이터나 문장 등의 순차적인 데이터를 처리하는 데 사용됨. LSTM은 다양한 응용 분야에서 사용되며, 특히 자연어 처리(Natural Language Processing) 분야에서 문장의 의미나 문맥을 파악하는 데 활용됨. 또한 LSTM은 음성 인식, 기계 번역, 시계열 예측 등 다양한 기계 학습 작업에서 효과적으로 사용될 수 있음. |
7-3. biLM(bidirectional Language Model)
양방향 언어모델. ELMo에서 말하는 biLM은 기본적으로 다층 구조(Multi-layer)를 전제로 하며,
이는 은닉층이 최소 2개 이상이라는 의미.
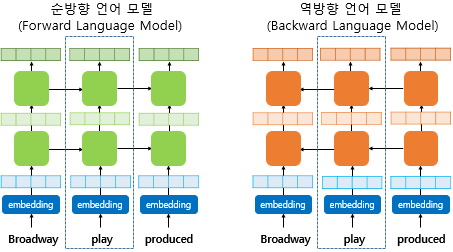
아래는 은닉층이 2개인 순방향 언어 모델과 역방향 언어 모델의 모습.
biLM의 각 시점의 입력이 되는 단어 벡터는 임베딩 층(embedding layer)을 사용해서 얻은 것이 아니라 합성곱 신경망을 이용한 문자 임베딩(character embedding)을 통해 얻은 단어 벡터임.
문자 임베딩은 마치 서브단어(subword)의 정보를 참고하는 것처럼
문맥과 상관없이 dog란 단어와 doggy란 단어의 연관성을 찾아낼 수 있으며,
또한 이 방법은 OOV에도 견고한다는 장점이 있음.
biLM은 순방향 언어모델과 역방향 언어모델이라는 두 개의 언어 모델을 별개의 모델로 보고 학습함.
결과적으로, biLM은 n개의 token으로 이루어진 입력 문장을
양방향(forward, backward)의 언어 모델링을 통해 문맥적인 표현을 반영하여 입력문장의 확률을 예측.
7-4. ELMo의 학습 방법
biLM이 언어 모델링을 통해 학습된 후 ELMo가 사전 훈련된 biLM을 통해
입력 문장으로부터 단어를 임베딩하기 위한 과정
이 예제에서는 play란 단어가 임베딩이 되고 있다는 가정 하에 ELMo를 설명함.
play라는 단어를 임베딩 하기위해서 ELMo는 위의 점선의 사각형 내부의 각 층의 결과값을 재료로 사용함.
다시 말해 해당 시점(time step)의 BiLM의 각 층의 출력값을 가져옴.
그리고 순방향 언어 모델과 역방향 언어 모델의 각 층의 출력값을 연결(concatenate)하고 추가 작업을 진행.
여기서 각 층의 출력값이란 첫번째는 임베딩 층을 말하며, 나머지 층은 각 층의 은닉 상태를 말함.
ELMo의 직관적인 아이디어는 각 층의 출력값이 가진 정보는 전부 서로 다른 종류의 정보를 갖고 있을 것이므로, 이들을 모두 활용한다는 점에 있음. 아래는 ELMo가 임베딩 벡터를 얻는 과정을 보여줌.
1) 각 층의 출력값을 연결(concatenate)
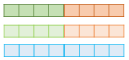
2) 각 층의 출력값 별로 가중치를 줌

이 가중치를 여기서는 s1, s2, s3이라고 함.
3) 각 층의 출력값을 모두 더함
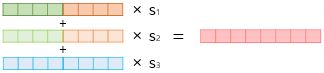
2)번과 3)번의 단계를 요약하여 가중합(Weighted Sum)을 함.
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱함
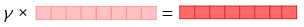
이 스칼라 매개변수를 여기서는 γ라고 함.
이렇게 완성된 벡터를 ELMo 표현(representation)이라고 함.
ELMo 표현은 기존의 임베딩 벡터와 함께 사용할 수 있음.
우선 텍스트 분류 작업을 위해서 GloVe와 같은 기존의 방법론을 사용한 임베딩 벡터를 준비했다고 가정하자.
이때, ELMo 표현을 GloVe 임베딩 벡터와 연결(concatenate)해서 입력으로 사용할 수 있음.
그리고 이때 biLM의 가중치는 고정시키고, 위에서 사용한 s1, s2, s3와 γ는 훈련 과정에서 학습됨.
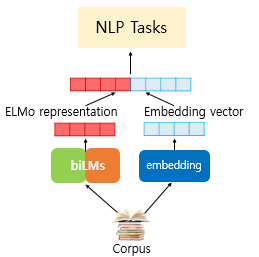
위의 그림은 ELMo 표현이 기존의 GloVe 등과 같은 임베딩 벡터와 함께 NLP 태스크의 입력이 되는 것을
보여줌.
사전 학습된 biLM이 있다면, 지도학습 형태의 다운스트림 작업을 수행하기 위한 언어 모델이 있을 때,
BiLM을 학습하는 방법은 아래와 같음
1) 사전학습된 biLM에 원하는 자연어처리 작업의 학습 데이터셋 문장들을 통과시켜서
문장을 구성하는 각각의 단어 토큰 K에 대한 Layer Representation을 계산.
2) biLM에서는 양방향 학습으로 총 L개의 layer에 대해 2L + 1개의 Layer Representation을 얻을 수
있으므로, 이들을 모두 계산한 후 에 biLM의 모든 parameter를 freeze함.
3) ELMo를 추가한 지도학습 다운스트림 작업을 수행하는 모델을 학습하여 softmax가중치를 얻을 수 있음.
7-5. ELMo 요약
기존의 단어 임베딩 구조가 문맥의 정보를 충분히 반영하지 못한다는 한계가 존재.
이러한 한계를 해결하기 위해 양방향 학습이 가능한 biLM으로부터 문맥 내 정보를 충분히 반영하는 문장
벡터 표현을 학습하는 일반적인 방법이 ELMo
실제로 넓은 범위의 NLP 문제들에서 ELMo를 적용했을 때 많은 성능향상을 가져오며,
학습 데이터가 작을수록 더 효율적인 학습이 가능함.
8. 트랜스포머(Transformer)
자연어 처리 및 기타 시퀀스 기반 작업에 사용되는 머신러닝 모델의 일종.
2017년 구글이 발표한 논문 "Attention is all you need"에서 발표.
seq2seq의 구조인 인코더-디코더를 따르면서도, 어텐션(Attention)만으로 구현됨.
RNN을 사용하지 않고 인코더-디코더 구조를 설계하였음에도 번역성능에서도
RNN보다 우수한 성능을 보여주었으며 2017년 이후 지금까지도 다양한 분야에서 사용되는 범용적인 모델.
인코더가 입력문자의 정보를 벡터로 압축할 때 입력 문장의 정보가 일부 손실됨을 보정하기 위해
어텐션 메커니즘이 제안되었으며, 실제로 seq2seq 모델에 어텐션을 사용한 구조는
어느정도 성능 향상을 가져옴.(여전히 RNN의 구조적인 문제로 한계점은 있음)
어텐션(Attention) 메커니즘: 트랜스포머와 같은 자연어 처리 모델에서 중요한 역할을 하는 메커니즘. 어텐션은 입력 시퀀스의 다른 위치들 간의 상대적인 중요성을 계산하는 방법. 어텐션 메커니즘은 특정 위치의 출력을 계산하기 위해 입력 시퀀스의 다른 위치들에 대한 가중치를 할당함. 이 가중치는 입력 시퀀스 내에서 해당 위치가 출력에 얼마나 중요한지를 나타냄. 간단히 말하면, 어텐션은 주어진 쿼리(Query)와 다른 위치인 키(Key) 사이의 유사도를 계산하여 해당 키의 값(Value)에 가중치를 부여하는 것임. 어텐션 메커니즘의 요소: 1) 쿼리(Query): 어텐션의 출력을 계산하기 위해 사용되는 위치 또는 벡터. 2) 키(Key): 입력 시퀀스의 다른 위치들에 대한 표현. 키는 보통 인코더의 출력이나 디코더의 이전 상태 등으로 사용됨. 3) 값(Value): 입력 시퀀스의 다른 위치들에 대한 실제 값. 값을 부여하는 가중치는 어텐션 메커니즘에서 중요한 역할을 함. 어텐션 메커니즘의 장점: 입력 시퀀스의 모든 위치를 고려하여 출력을 계산하므로, 전역적인 문맥 파악이 가능. 각 위치에 대한 상대적인 중요도를 계산하여 모델이 입력 시퀀스의 다른 부분에 집중할 수 있음. 모델이 임의의 위치에 대한 정보를 활용할 수 있으므로, 긴 시퀀스 처리에 유리함. |
8-1. 트랜스포머의 특징
기존 RNN은 입력을 순차적으로 처리하기 때문에 병렬화가 불가능했음.
→ 어텐션 방식으로 생각해보면 시퀀스 간 관계를 파악할 때 병렬적으로 파악할 수 있음.
트랜스포머는 RNN을 사용하지 않지만, seq2seq 모델의 구조처럼 인코더에서 입력 시퀀스를 입력받고,
디코더에서 출력시퀀스를 출력하는 인코더-디코더를 사용함.
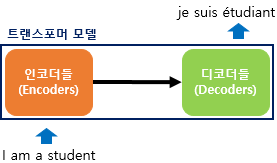
트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고,
디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지하고 있음.
이전 seq2seq 구조가 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time step)을 가지는 구조면,
트랜스포머는 인코더와 디코더라는 단위가 N개로 구성되는 구조임.
(트랜스포머를 제안한 논문에서는 인코더와 디코더의 개수를 각각 6개 사용하였음)
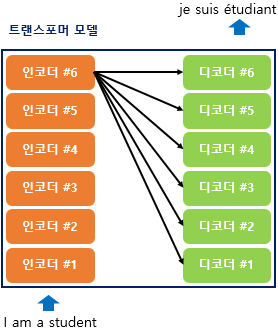
위의 그림은 인코더와 디코더가 6개씩 존재하는 트랜스포머의 구조를 보여줌.
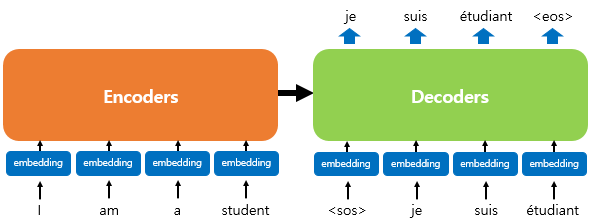
위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조.
디코더는 마치 기존의 seq2seq 구조처럼 시작 심볼 <sos>를 입력으로 받아 종료 심볼 <eos>가 나올 때까지 연산을 진행함. 이는 RNN은 사용되지 않지만 여전히 인코더-디코더의 구조는 유지되고 있음을 보여줌.
RNN, seq2seq 등은 입력이 문자단위가 아니라 연속적으로 들어옴
8-2. 포지셔널 인코딩(positional encoding)
트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로
단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음.
트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여
모델의 입력으로 사용하는데, 이를 포지셔널 인코딩(positional encoding)이라고 함.
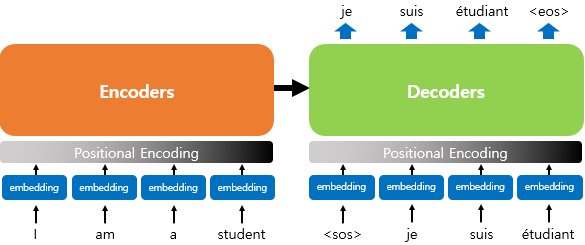
위의 그림은 입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에
포지셔널 인코딩의 값이 더해지는 것을 보여줌. 임베딩 벡터가 인코더의 입력으로 사용되기 전 포지셔널 인코딩값이 더해지는 과정을 시각화하면 아래와 같음.

위치 정보를 가진 값을 만들기 위해 sin, cos 함수를 사용함.(pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내고, i값은 임베딩 벡터 내의 차원의 인덱스를 의미, dimension model은 설정한 모델의 크기를 나타냄)

임베딩 벡터 내의 차원의 인덱스가 짝수인 경우에는 사인함수의 값을 사용하고,
홀수인 값을 사용할 경우는 코사인 함수를 사용하는 구조.
트랜스포머는 사인 함수와 코사인 함수의 값을 임베딩 벡터에 더해줌으로서 단어의 순서 정보를 더해줌.
(예: 임베딩 백터 내 위치가 (pos, 2i)인 경우에는 사인 함수를 사용하고
(pos, 2i+1)인 경우에는 코사인 함수를 사용.)
각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라 트랜스 포머의 입력으로 들어가는 임베딩 벡터의 값이 달라짐
8-3. 트랜스포머의 셀프 어텐션
'어텐션을 스스로에게 수행한다'는 의미
기존 seq2seq 모델에서 사용하는 어텐션은 디코더가 생성하는 특정 시점의 hidden state와
입력 문장들과의 관계를 계산하기 위해 사용.
이때 Query는 디코더가 생성하는 특정시점의 Hidden state이며,
key와 value는 입력 문장 내 단어 각각의 hidden state를 사용함.

위의 예시 문장은 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.' 라는 의미임.
그런데 여기서 그것(it)에 해당하는 것은 과연 길(street)일까? 동물(animal)일까?
우리는 피곤한 주체가 동물이라는 것을 아주 쉽게 알 수 있지만 기계는 그렇지 않음.
셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하므로서 그것(it)이 동물(animal)과 연관되었을 확률이
높다는 것을 찾아냄.
셀프 어텐션은 Query(Q), Key(K), Value(V)라는 세 가지 벡터를 사용함.
이때 특이한 점은 Q, K, V가 모두 동일한 벡터라는 점임.
각 단어에 대해 Q, K, V 벡터를 계산한 다음, 이 벡터들을 기반으로 어텐션 연산을 수행함.
어텐션 연산은 각 Q 벡터에 대해 모든 K 벡터들과의 어텐션 스코어를 계산하는 것으로 시작함.
이를 위해 스케일드 닷 프로덕트 어텐션을 사용할 수 있음.
어텐션 스코어는 각 K 벡터와 해당 Q 벡터 사이의 관련성을 나타냄.
어텐션 스코어를 구한 후에는 어텐션 분포도를 구할 수 있음.
어텐션 분포도는 어텐션 스코어를 정규화하여 어텐션 가중치로 사용하는 값임.
이를 통해 각 K 벡터의 중요도를 나타내며, Q 벡터와 관련이 높은 K 벡터에 더 많은 가중치를 부여함.
마지막으로 어텐션 값 또는 컨텍스트 벡터를 구성하기 위해 어텐션 분포도와 V 벡터를 가중합함.
이렇게 구한 어텐션 값은 해당 Q 벡터에 대한 정보를 담고 있는 벡터로 볼 수 있음.
이 과정을 모든 Q 벡터에 대해 반복하여 전체 문장에 대한 어텐션 값을 얻을 수 있음.
셀프 어텐션은 행렬 연산을 사용하므로 각 단어에 대한 Q, K, V 벡터를 한 번에 계산할 수 있음.
이는 일괄 계산(batch processing)이 가능하게 해주어 연산 속도를 향상시킬 수 있음.
8-4. 트랜스포머의 멀티 헤드 어텐션
* 어텐션에서는 d_model의 차원을 가진 단어 벡터를 num_heads로 나눈 차원으로 어텐션을 수행함.
* 논문 기준 512개의 차원의 각 단어 벡터를 8로 나누어 64차원의 Q, K, V 벡터로 바꿔서 어텐션을 수행한 셈
* 트랜스포머 연구진은 한 번의 어텐션을 하는 것 보다 여러 번의 어텐션을 병렬로 사용하는 것이 더욱 효과적이라 판단함.
* d_model의 차원을 num_head개로 나누면 d_model/num_head의 차원을 가지는 Q, K, V에 대해 어텐션을 num_head번 수행할 수 있음.
* 어텐션 메커니즘이 병렬로 이뤄지며 각각의 어텐션 값 행렬을 어텐션 헤드라 부름.
* d_model의 단어 임베딩을 차원축소하는데 사용되는 가중치 행렬의 값은 8개의 어텐션 헤드마다 전부 다름
* 병렬 어텐션을 모두 수행하면 모든 어텐션 헤드를 연결하며, 모두 연결된 어텐션 헤드 행렬의 크기는 (seq_len, d_model)
8-5. 포지션-와이즈 피드 포워드 신경망(Position-wise FFNN)
* 우리가 알고있는 일반적인 deep nueral network의 feed forward 신경망
* 쉽게 말하면, 각각의 학습 노드가 서로 완전히 연결된 Fully-connected NN이라고 해석할 수 있음.
8-6. 잔차연결 FFNN(Residual Connection)
- sublayer의 출력에 입력값을 더해주는 기법
* 입력과 출력은 FFNN을 지나야 하기 때문에 동일한 차원을 가지므로 덧셈이 가능.
$$ FFNN(x) = MAX(0, xW_1 + b_1)W_2 + b_2$$
8-7. 층 정규화(Layer Normalization)
* Residual Connection(잔차연결)을 거친 결과는 이어서 Layer Normalization 과정을 거침
* 수식으로 구현된 인코더는 총 num_layers만큼 순차적으로 한 후 에 마지막 춤의 인코더의 출력을 디코더에게 전달하면서 디코더 연산이 시작됨.
* 디코더 또한 num_layers 만큼의 연산을 하는데, 이때마다 인코더가 보낸 출력을
디코더 layer 각각에서 모두 사용
8-8. 트랜스포머의 디코더(decoder)
* 디코더도 인코더와 동일하게 임베딩 층과 포지셔널 인코딩을 거친 후에 문장 행렬이 입력.
* Teacher Forcing 기법을 사용하여 훈련되므로 학습 과정에서 디코더는 정답 문장에 해당하는 문장 행렬을 한 번에 통째로 입력.
* 현 시점에 대한 정답만이 아닌 미래에 나올 단어까지 참조함.
* seq2seq는 정답을 하나씩 넣어주지만, 트랜스포머는 문장을 통째로 넣어주기 때문에 현 시점의 정답이 아니라 이후에 나올 정답단어들까지 참조해서 예측.
8-9. Look-ahead mask
* Look-ahead mask는 디코더의 첫번째 sublayer에서 이루어짐
* 디코더의 첫번째 sublayer인 멀티 헤드 셀프 어텐션에서 어텐션 스코어 행렬에 마스킹을 적용하는 기법
8-10. 트랜스포머 구현
* 위에서 알아본 인코더와 디코더 구조를 조합해서 트랜스포머를 만들 수 있음.
* 인코더의 출력은 인코더-디코더 어텐션에서 사용하기 위해 디코더로 전달됨.
9. GPT
* GPT 모델은 2018년 6원 OpenAI가 논문에서 처음 제안
* GPT도 unlabeld data로부터 pre-train을 진행한 후, 이를 특정 downstream task(with labeled data)에 fine_tuning(transfer learning)을 하는 모델
* Transformer의 decoder만 사용하는 구조
9-1. GPT 모델의 특징
* 사전학습에는 대규모의 unlabled data를 사용하는데 unlabeled data에서 단어 수준 이상의 정보를 얻는 것은 매우 힘듦.
* 또한, 어떤 방법이 유용한 텍스트를 배우는데 효과적인지가 불분명함.
* 사전학습 이후에도, 어떤 방법이 fine-tuning에 가장 효과적인지 불분명
* 논문에서는 unsupervised pre-training과 supervised fine-tuning의 조합을 사용한 접근법을 제안하고 있음
* 목표는 fine-tuning에서의 미세조정만으로 다양한 자연어처리 작업에 적용할 수 있는 범용적인 표현을 사전학습에서 학습하는 것.
* 모델은 이미 효과가 검증된 2017년 공개된 transformer를 사용함
9-2. GPT 모델 구조
* GPT는 Transformer의 변형인 multi-layer Transformer decoder만 사용
* 입력 문맥 token에 multi-headed self-attention을 적용한 후, 목표 token에 대한 출력 분포를 얻기 위해 position-wise feedforward layer를 적용
9-3. GPT 모델 학습
* unsupervised pre-training: 대규모 코퍼스에서 unsupervised learning으로 언어 모델을 학습
- trainsformer 디코더를 사용하여 계속 next token prediction 학습을 하는 것
- multi-layer Transformer decoder를 사용하여 입력문맥 token에 multi-headed self-attention을 적용한 후 목표 token에 대한 출력 분포를 얻기 위해 position-wise feedforwardlayer를 적용함.
* supervised fine-tuning: 특정 작업에 대한 데이터로 모델을 fine-tuning
- fine-tuning 단계에서는 사전학습된 모델을 각 task에 맞게 input과 label로 구성된 supervised dataset에 대해 학습
- GPT-1의 output을 downstream task에 적절하게 선형변환 후 softmax에 넣음
- 결과를 task에 맞는 loss들을 결합



