
5. 워드 임베딩 시각화
5-1. 네이버 영화리뷰 데이터셋
총 200,000개 리뷰로 구성된 데이터로, 영화 리뷰를 긍/부정으로 분류하기 위해 만들어진 데이터셋.
리뷰가 긍정인 경우 1, 부정인 경우 0으로 표시한 레이블로 구성되어있음.
# 한글 글꼴 적용
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf# train set/test set 불러오기
* train set
https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
* test set
https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt
import urllib.request
import pandas as pd
# URL을 이용한 파일 파운로드
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='rating_train.txt')
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='rating_test.txt')
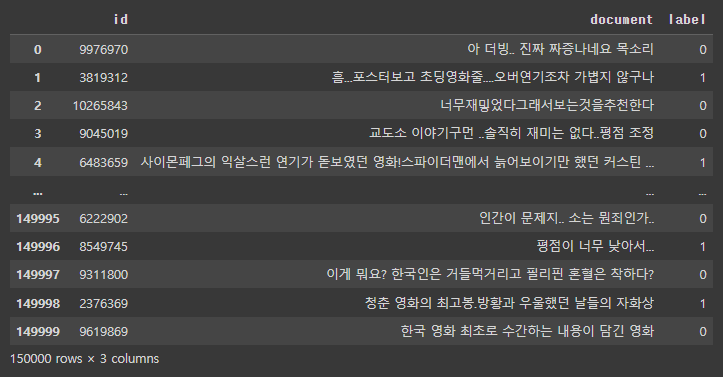
# train dataset을 table로 생성
train_dataset = pd.read_table('rating_train.txt')
print(train_dataset)
# dataset 개수 확인
len(train_dataset)
review_df = pd.DataFrame(train_dataset)
review_df
5-2. 데이터 전처리
# 데이터가 너무 방대하여 런타임 끊김이 빈번하게 발생하기 때문에,
dataset의 데이터를 6000개로 줄인 후 진행
train_dataset = train_dataset.loc[0:6000]
# 결측치를 확인하고 결측치를 제거
train_dataset.replace('', float('NaN'), inplace=True)
train_dataset.isnull().values.any()
# True가 존재한다는 것은 결측치가 존재한다는 의미

train_dataset = train_dataset.dropna().reset_index(drop=True)
len(train_dataset)
# 5개의 결측치가 존재했다는 것을 알 수 있음

# 열을 기준으로 중복 데이터를 제거
train_dataset = train_dataset.drop_duplicates(['document']).reset_index(drop=True)
len(train_dataset)
# 약 3800개 가량의 중복데이터가 존재했다는 것을 알 수 있음.
# 한글이 아닌 문자를 포함하는 데이터 제거 (ㅋㅋㅋ와 같은 이모티콘은 제거하지 않음)
train_dataset['document'] = train_dataset['document'].str.replace('[^ㄱ-ㅎㅏ-ㅣ가-힣]', ' ')
train_dataset
# 너무 짧은 단어는 제거 (단어 길이 1 이하)
train_dataset['document'] = train_dataset['document'].apply(lambda x: ' '.join([token for token in x.split() if len(token) > 1]))
train_dataset

# 전체 길이 10이하, 단어 개수가 5개 이하인 데이터 제거
train_dataset = train_dataset[train_dataset.document.apply(lambda x: len(str(x)) >10 and len(str(x).split())>5)].reset_index(drop=True)
train_dataset

# 불용어제거
!pip install konlpy

# 형태소 분석기는 Okt 사용
from konlpy.tag import Okt
# 불용어 직접 만들기
stopwords = ['의', '가', '이', '은', '들', '는', '좀', '잘', '걍', '과', '도', '를', '으로', '자', '에', '와', '한', '하다']
# train dataset의 리스트화
train_dataset = list(train_dataset['document'])
# 형태소 분석
okt=Okt()
tokenized_data = [ ]
for sentence in train_dataset: # 토큰화
tokenized_sentence = okt.morphs(sentence, stem=True) # stem=True: 어절의 어미를 원형처리해줌
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords]
tokenized_data.append(stopwords_removed_sentence)
tokenized_data[0]

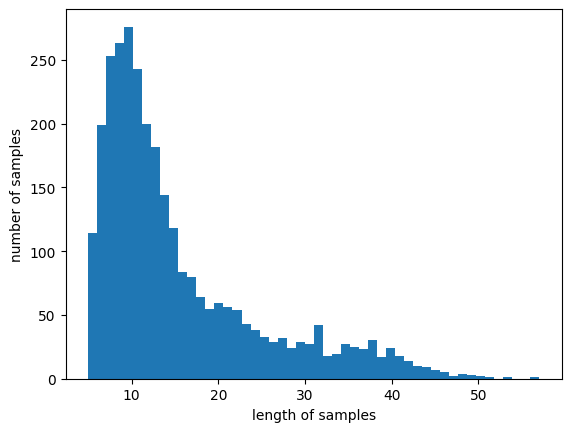
# matplotlib hist함수를 이용해서 length of samples와 number of samples를 그려서 표현해볼 예정
# review의 최대 길이와 평균 길이를 출력
import matplotlib.pyplot as plt
print('리뷰의 최대 길이: ', max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이: ', sum(map(len, tokenized_data)) / len(tokenized_data))
plt.hist([len(review) for review in tokenized_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
5-3. Word Embedding 구축
from gensim.models import Word2Vec
gensim: 파이썬에서 자연어 처리 작업을 수행하기 위한 오픈 소스 라이브러리. 주요 기능: 1) 토픽 모델링: gensim은 LDA(Latent Dirichlet Allocation) 및 LSI(Latent Semantic Indexing)와 같은 토픽 모델링 알고리즘을 구현하고 있음. 이를 사용하여 텍스트 데이터에서 주제 추출 및 문서 군집화를 수행할 수 있음. 2) 워드 임베딩: gensim은 Word2Vec, FastText, GloVe와 같은 유명한 워드 임베딩 알고리즘을 구현하고 있음. 이를 사용하여 단어를 고차원 벡터로 표현하고, 단어 간의 의미적 유사성을 계산할 수 있음. 3) 문서 유사성 검색: gensim은 TF-IDF와 코사인 유사도를 사용하여 문서 간의 유사성을 계산하는 기능을 제공함. 이를 통해 문서 검색, 추천 시스템 등에서 문서 간의 관련성을 평가할 수 있음. 4) 토큰화와 코퍼스 처리: gensim은 문서를 토큰화하고, 토큰을 처리하여 코퍼스(corpus)를 만드는 기능을 제공함. 코퍼스는 텍스트 데이터를 처리하기 쉽게 변환한 객체로, 토픽 모델링 및 워드 임베딩 작업에 사용됨. 5) 모델 저장 및 로딩: gensim은 학습된 모델을 저장하고 로드할 수 있는 기능을 제공함. 이를 통해 모델을 재사용하거나 배포할 수 있음. 이와 같이, gensim은 사용하기 쉽고 효율적인 자연어 처리 도구로 알려져 있으며, 다양한 자연어 처리 작업에서 널리 사용되고 있음. |
# Word2Vec 모델의 생성
embedding_dim = 100 # 차원: 100
model = Word2Vec(
sentences = tokenized_data, # 워드 임베딩을 학습시킬 문장들의 리스트로, 미리 토큰화된 상태여야 함.
vector_size = embedding_dim, # 임베딩 차원의 크기로, 각 단어는 이 벡터의 차원에 따라 표현됨.
window = 5, # 주변 단어의 윈도우 크기. 예를 들어, 현재 단어의 좌우 5개 단어까지를 주변 단어로 고려함.
min_count = 5, # 모델에 포함할 최소 단어 등장 횟수. 이 값보다 적게 등장한 단어는 모델에 제외.
workers = 4, # 모델 학습에 사용할 스레드 개수. 빠른 학습을 위해 병렬 처리를 할 수 있음. 기본값:1.
# !lscpu: cpu의 정보를 확인할 수 있는 코드
sg=0 # 학습 알고리즘을 선택하는 매개변수. 0: CBOW, 1: Skip-gram
)
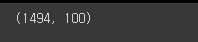
# embedding 행렬의 크기 확인.
# 12107개의 단어가 존재 및 각 단어는 미리 설정한 embedding_dim=100의 차원으로 구성되어있음.
model.wv.vectors.shape
# vocab 내부의 단어 20개만 가져오기
word_vectors = model.wv
vocabs = list(word_vectors.index_to_key)
vocabs[:20]

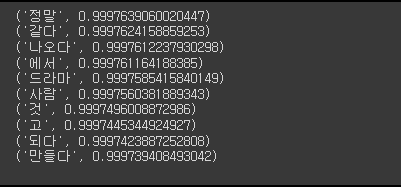
# 유사 단어를 뽑는 테스트 진행 1
for sim_word in model.wv.most_similar('영화'):
print(sim_word)
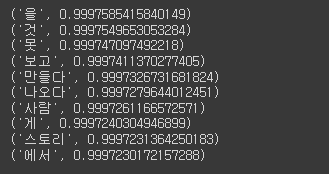
# 유사 단어를 뽑는 테스트 진행 2
for sim_word in model.wv.most_similar('좋다'):
print(sim_word)
# 단어 A와 단어 B의 유사도를 확인
model.wv.similarity('좋다', '괜찮다')
5-4. word embedding 시각화
# font를 import
import matplotlib.font_manager
font_manager: 텍스트 표시에 사용할 수 있는 폰트 관리 기능을 제공하는 matplotlib의 모듈. 이 모듈을 사용하면 matplotlib를 통해 그래프, 플롯, 그림 등에서 사용할 폰트를 선택하고 설정할 수 있음. 주요 기능: 1) 폰트 로딩: 시스템에 설치된 폰트들을 검색하고 로딩할 수 있음. findfont() 함수를 사용하여 특정 폰트를 찾을 수 있고, FontProperties 클래스를 사용하여 폰트 파일의 경로 및 속성을 지정할 수 있음. 2) 폰트 캐싱: 폰트를 캐싱하여 성능을 향상시킴. 한 번 폰트를 로딩하고 캐싱한 후에는 다시 로딩하지 않고 캐시된 폰트를 사용할 수 있음. 3) 폰트 선택 및 설정: matplotlib에서 사용할 폰트를 선택하고 설정하는 기능을 제공. FontProperties 클래스를 사용하여 폰트 속성을 설정하고, rcParams를 통해 전역 폰트 설정을 변경할 수 있음. 4) 폰트 샘플링: 사용 가능한 폰트를 샘플링하여 미리보기를 제공하는 기능도 포함함. fontManager 클래스를 사용하여 시스템에 설치된 폰트를 샘플링하고, 이를 통해 원하는 폰트를 시각적으로 확인할 수 있음. matplotlib의 font_manager 모듈은 텍스트 표시에 사용할 폰트를 관리하고 설정하는 데 유용한 도구임. 이를 통해 그래프 및 플롯에서 폰트를 선택하고 설정하여 시각적인 결과물을 보다 정교하게 제어할 수 있음. |
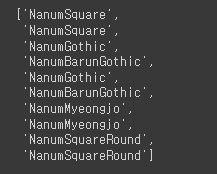
# 설치된 font 중 Nanum으로 시작하는 폰트를 for문을 순회하여 확인
font_list = matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
[matplotlib.font_manager.FontProperties(fname=font).get_name() for font in font_list if 'Nanum' in font]
# font를 NanumBarunGothic으로 설정
plt.rc('font', family='NanumBarunGothic')
# for문을 순회하여 word_vector_list에 값들의 가중치를 저장
word_vector_list = [word_vectors[word] for word in vocabs]
word_vector_list[0] # index 0번만 확인 # 100개

# 차원을 축소하여 2차원 평면에 재확인할 예정 # PCA를 사용하지 않고 TSNE을 사용할 예정
# PCA가 자주 이용되는 차원축소방식이지만 군집의 변별력을 해친다는 단점이 있음.
# PCA를 개선한 방식이 t-SNE 차원축소방식임
from sklearn.manifold import TSNE
import numpy as np
TSNE: t-SNE(T-Distributed Stochastic Neighbor Embedding) 알고리즘을 구현한 sklearn.manifold 모듈의 클래스. t-SNE는 고차원의 데이터를 저차원으로 축소하는 비선형 차원 축소 기법 중 하나로, 시각화를 위해 주로 사용됨. t-SNE는 데이터의 유사성을 보존하면서 저차원 공간에 투영하는데, 이를 통해 복잡한 데이터의 구조와 패턴을 시각적으로 파악할 수 있음. t-SNE는 특히 고차원 데이터를 2차원 또는 3차원으로 축소하여 데이터 포인트 간의 관계를 시각화하는 데 유용함. 주요 매개변수: 1) n_components: 축소된 차원의 개수를 지정. 일반적으로 2나 3을 사용하여 2차원 또는 3차원으로 시각화함. 2) perplexity: t-SNE 알고리즘의 가까운 이웃의 중요성을 조절하는 매개변수. 더 높은 값은 전역 구조를 보다 잘 보존하지만, 더 많은 이웃을 고려하여 계산량이 증가함. 3) learning_rate: 학습 속도를 조절하는 매개변수. 값이 높을수록 빠르게 학습하지만, 수렴에 실패할 가능성이 있고, 값이 낮을수록 수렴까지의 시간이 오래 걸릴 수 있음. 4) fit_transform(): TSNE 객체를 초기화한 후 사용되며 고차원 데이터를 받아 저차원으로 변환해주는 메소드. t-SNE를 사용하여 저차원으로 축소된 데이터를 시각화하면, 복잡한 데이터의 패턴과 군집, 유사성 등을 시각적으로 이해할 수 있음. 주로 클러스터링, 이상치 탐지, 시각적 데이터 탐색 등에 활용되며, 데이터의 구조를 파악하고 시각적으로 표현하기 위한 강력한 도구. |
tsne = TSNE(learning_rate = 100)
transformed = tsne.fit_transform(np.array(word_vector_list))
x_axis_tsne = transformed[:, 0] # x축
y_axis_tsne = transformed[:, 1] # y축
6. Seq2Seq
6-1. 문장 임베딩
문장 임베딩은 자연어 처리에서 문장을 고차원 벡터로 표현하는 기법.
단어 임베딩이 단어 수준의 표현을 학습하는 것과 달리, 문장 임베딩은 문장 전체의 의미와 구조를
반영하는 벡터 표현을 생성함. 문장 임베딩은 다양한 자연어 처리 작업에 활용될 수 있음.
2017년 이전의 임베딩 기법들은 대부분 단어 수준의 모델(Word2Vec, FastText, GloVe)
단어수준 임베딩 기법은 자연어의 특성인 모호성, 동음이의어를 구분하기 어렵다는 한계를 지님.
2017년 이후에는 ELMo(Embeddings from Language Models)와 같은 모델이 발표되고,
Transformer와 같은 언어모델에서 문장 수준의 언어 모델링을 고려하며 한계점이 해소되기 시작.
6-1-1. 언어모델
* 자연어처리 작업은 자연어 문장을 생성하거나 예측하는 방식으로 결과를 표현.
* 자연어처리 작업에서는 자연어를 수치화하여 표현할 수 있는 언어모델을 사용.
* 언어 모델은 자연어문장 혹은 단어에 확률을 할당하여 컴퓨터가 처리할 수 있도록 하는 모델로 주어진 입력에 대해 가장 자연스러운 단어 시퀀스를 찾을 수 있음.
6-1-2. 언어 모델링
주어진 단어들로부터 아직 모르는 단어들을 예측하는 작업
사람은 수많은 단어와 문장을 듣고 쓰고 말하며 언어 능력을 학습해왔기 때문에 문장구성 및 의미상 가장 적합한 단어를 판단할 수 있음.
문장을 기계에게 보여주고 적합한 단어를 예측하도록 학습(기계 역시 사람과 같은 프로세스로 동작함)
언어 모델은 텍스트 기반의 수많은 문장을 통해 어떤 단어가 어떤 어순으로 쓰인 것이 가장 자연스러운 문장인지를 학습.
6-2. 자연어처리 모델 구조
자연어처리 분야의 인공지능 모델은 근 10년동안 수많은 모델 구조에 걸쳐 진화해왔음.
사용되지 않은 모델들도 있으나, 해당 모델이 나온 이유와 구조, 한계점들을 공부하는 것은 자연어처리 분야에서 통찰력을 얻는데 도움이 될 것이므로 공부하는 것을 추천함.
현재에도 분야별로 다양한 모델들이 공개되고 있는데, 자연어처리에서 핵심은 공개된 모델들 중
어떤 언어 모델이 내가 풀고자하는 문제에 가장 적합한지를 탐색하는 것임.
대부분의 분야에서 Transformer 계열의 모델이 가장 인기있지만, 특정 자연어 작업처리에 특화된 세부적인 테크닉들이 다르므로 최신 연구 동향과 SOTA 모델들을 팔로업하는 것을 추천함. https://paperswithcode.com/sota
Papers with Code - Browse the State-of-the-Art in Machine Learning
11325 leaderboards • 4259 tasks • 8370 datasets • 100099 papers with code.
paperswithcode.com
6-2-1. 자연어처리 분야의 주요 언어모델
Seq2Seq (가장 먼저 나옴)
ELMo
Transformer
GPT
BERT (가장 최근에 나옴)
6-3. Seq2Seq의 배경
Seq2Seq 모델이 등장하기 전 DNN(Deep Neural Network) 모델은 사물인식, 음성인식 등에서 꾸준히
성과를 냈음. (예: CNN, RNN, LSTM, GRU...)
모델 입/출력의 크기가 고정된다는 한계점이 존재했기 대문에 자연어처리와 같은 가변적인 길이의
입/출력을 처리하는 문제들을 제대로 해결할 수 없었음.
RNN의 한계성을 참고하는 웹사이트
https://ardino-lab.com/rnn%EC%9D%98-%EA%B5%AC%EC%A1%B0-%EB%B0%8F-%ED%95%9C%EA%B3%84/
RNN의 구조 및 한계 – Onds' ML Notes
5.2.1 RNN의 한계 RNN의 구조를 다시 한번 보자. RNN은 계속해서 같은 셀의 반복으로 구성된다. 반복 횟수는 입력의 길이(sequence)에 따라 달라지는데 입력의 길이가 길면 그만큼 시간 축이 길게 펼쳐
ardino-lab.com
* RNN은 Seq2Seq가 등장하기 전에 입/출력을 시퀀스 단위로 처리할 수 있는 모델이었음.
* RNN은 셀을 재귀적으로 활용하여 연속된 입/출력을 처리할 수 있는 모델.
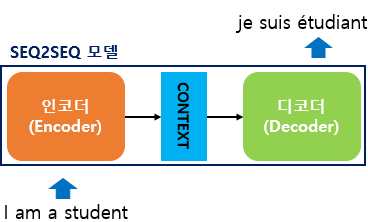
6-3-1. Seq2Seq(Sequence To Sequence)
시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 모델.
예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translation)이 그러한 대표적인 예인데,
입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇으로 만들 수 있고,
입력 시퀀스와 출력 시퀀스를 각각 입력 문장과 번역 문장으로 만들면 번역기로 만들 수 있음.
그 외에도 내용 요약(Text Summarization), STT(Speech to Text) 등에서 쓰일 수 있음.

2014년 구글에서 논문으로 제안한 모델.
LSTM(Long Short Term Memory) 또는 GRU(Gated Recurrent Unit)기반의 구조를 가지고 고정된 길이의 단어 시퀀스를 입력으로 받아 입력 시퀀스에 알맞은 길이의 시퀀스를 출력해주는 언어 모델.
본 논문은 2개의 LSTM을 각각 Encoder와 Decoder로 사용해 가변적인 길이의 입출력을 처리하고자 했음.
Seq2Seq 모델은 기계 번역 작업에서 큰 성능향상을 가져왔고, 특히 긴 문장을 처리하는데 강점이 있음. https://wikidocs.net/24996
14-01 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
이번 실습은 케라스 함수형 API에 대한 이해가 필요합니다. 함수형 API(functional API, https://wikidocs.net/38861 )에 대해서 우선 숙지 후…
wikidocs.net
과제
1. 규제 (릿지, 라쏘)
2. 엘라스틱넷
3. 스태킹(Stacking)
4. 블렌딩(Weighted Blending)
해당 키워드를 활용해서 자유 주제로 예제를 1개 만듦들기
꼭 4개가 모두 들어갈 필요는 없지만, 최대한 참고하며 어떻게 사용되는지도 디테일하게 작성하는것을 추천함.
팀 발표 진행 예정



