
13. 특수 정렬 알고리즘
특수 정렬 알고리즘은 일반적인 정렬 알고리즘과는 다르게 특정한 기준에 따라 요소를 정렬하는 방식을 의미. 보다 특별한 규칙을 따르거나 특정한 요구 사항을 충족시키기 위해 사용되기도 함.
일반적인 정렬 알고리즘을 변형하거나 새로운 정렬 알고리즘을 개발하여 구현할 수 있으며,
특수 정렬 알고리즘의 선택은 주어진 문제나 데이터의 특성에 따라 달라짐.
예를 들어, 버블 정렬의 변형인 '개선된 버블 정렬'은 최솟값을 맨 끝으로 이동시키는 대신,
최솟값과 최댓값을 번갈아가며 정렬하는 특수 정렬 알고리즘임.
이렇게 하면 정렬된 요소들이 중앙을 기준으로 대칭적으로 배치됨.
또 다른 예로는 짝수와 홀수를 번갈아가며 정렬하는 특수 정렬 알고리즘이 있음.
이 알고리즘은 먼저 짝수 번째 인덱스에 짝수를 정렬, 홀수 번째 인덱스에 홀수를 정렬하여 배열을 정렬함.
13-1. 계수 정렬(Counting Sort)
계수 정렬은 정수나 정수로 표현할 수 있는 자료에 대해서만 동작하는 비교 기반 정렬 알고리즘으로,
각 요소의 개수를 세어 정렬하는 방식으로 동작함.
요소들이 양의 정수인 경우에 가장 잘 동작하며, 요소의 크기 범위가 제한적일 때 효율적임.
실행 단계:
1) 각 요소의 개수를 세어 빈도수 배열에 저장.
2) 빈도수 배열을 누적합 배열로 변환하여 각 요소의 정렬된 위치를 계산.
3) 원래 배열을 순회하며 누적합 배열을 참조하여 정렬된 결과를 생성.

조건: -O(N) ~ O(N) 사이 범위의 정수.
주로 작은 범위의 정수 정렬 시 유용함.
숫자의 발생 누적 횟수를 계산한 후, 누적 계산 결과대로 숫자를 배치.
counting_sort(list[], n): # list[0...n-1] count_list[] for i <- 0 to k # k는 list[0...n-1]에서 최대값 count_list[i] <- 0 for j <- 0 to n-1 # list[j] = 원래 리스트의 실제 값 -> count_list[]의 인덱스로 사용 # 해당 인덱스의 값을 1증가 -> ++ count_list[list[j]]++ for i <- 1 to k # 누적합 계산 -> return_list의 인덱스를 쉽게 알기 위해 count_list[i] = count_list[i] + count_list[i-1] for j <- 0 to n-1 # count_list의 값은 갯수, result_list의 인덱스이기 때문에 -1 result_list[count_list[list[j]] - 1] <- list[j] # 값을 하나 배정했으면 갯수 -1 count_list[list[j]]-- return result_list |
13-1-1. 구현
def counting_sort(alist):
k = max(alist)
counting_list = [0 for _ in range(k+1)]
result_list = [0 for _ in range(len(alist))]
for j in range(len(alist)):
# 동일한 값마다 갯수 1씩 증가
counting_list[alist[j]] += 1
print('각 횟수 계산 결과')
print(counting_list)
# 누적합으로 인덱스 계산
for i in range(k):
counting_list[i+1] = counting_list[i] + counting_list[i+1]
print('누적합인덱스 계산 결과')
print(counting_list)
for j in range(len(alist)):
result_list[counting_list[alist[j]]-1] = alist[j]
counting_list[alist[j]] -= 1
return result_list
from collections import defaultdict
def counting_sort_dict(alist):
counting_dict = defaultdict(list)
result_list = []
for element in alist:
counting_dict[element].append(element)
for key in range(min(counting_dict), max(counting_dict) + 1):
result_list.extend(counting_dict[key])
return result_list
13-1-2. 테스트
import random as r
cs_list = [r.randint(1,10) for _ in range(30)]
print(cs_list)
cs_list_sort = counting_sort(cs_list)
print(cs_list_sort)
import random as r
csd_list = [r.randint(1,10) for _ in range(30)]
print(csd_list)
csd_list_sort = counting_sort_dict(csd_list)
print(csd_list_sort)
13-2. 기수 정렬(Radix Sort)
기수 정렬은 비교 기반 정렬 알고리즘이 아닌 자리수를 기준으로 정렬하는 알고리즘으로,
각 요소의 자리수를 비교하여 정렬함. 일반적으로 10진수를 기준으로 설명.
가장 낮은 자리수부터 가장 높은 자리수까지 반복적으로 정렬을 수행함.
안정적인 정렬 알고리즘이기 때문에 안정성이 요구되는 경우에 유용함.
일반적으로 MSD(Most Significant Digit)와 LSD(Least Significant Digit) 기수 정렬이 있음.
1) MSD 기수 정렬: 가장 높은 자리수부터 정렬을 수행.
2) LSD 기수 정렬: 가장 낮은 자리수부터 정렬을 수행.
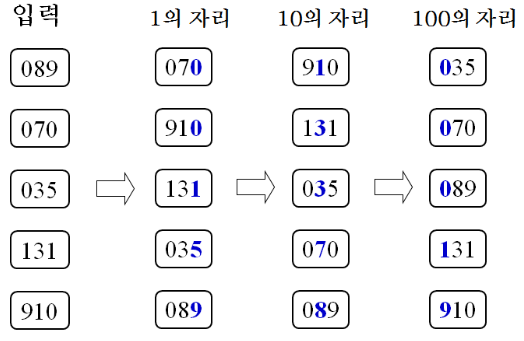
조건:
1) 비교 가능성
기수 정렬은 비교 기반의 정렬 알고리즘이 아니기 때문에 요소들이 서로 비교가능해야 함.
일반적으로 정수 형태로 표현된 데이터에 적용됨.
2) 동일한 자리수
정렬할 요소들은 동일한 자리수를 가져야 함.
예를 들어, 3자리 정수들끼리 정렬하거나, 문자열의 길이가 모두 동일한 경우에 적용할 수 있음.
작동:
1) 정렬할 요소들을 가장 낮은 자리수부터 가장 높은 자리수까지 반복.
2) 현재 자리수를 기준으로 0부터 9까지의 버킷(또는 큐)을 생성.
3) 정렬할 요소들을 현재 자리수에 맞게 버킷에 분배함.
예를 들어, 현재 자리수가 3이라면, 3의 자리수가 0인 요소들은 버킷 0에, 3의 자리수가 1인 요소들은
버킷 1에 저장됨.
4) 버킷에 저장된 요소들을 순서대로 꺼내 재배열함. 이때, 버킷에 저장된 순서를 유지함.
즉, 버킷 0부터 순서대로 요소를 꺼내고, 버킷 1, 2, ..., 9까지 순서대로 꺼내 재배열함.
5) 위의 과정을 가장 높은 자리수까지 반복함.
# k는 최대 자릿수 radix_sort(list[], n, k) for i <- 1 to k i번 째 자릿에 대해 list[0...n-1]을 안정성을 유지하며 정렬 |



