
3. 임베딩(embedding)
3-2. 임베딩 구축 방법
3-2-5. 분포 가설(Distributional Hypothesis) 및 언어 모델
분포가설은 단어의 의미는 그 단어가 주변에 등장하는 단어들과의 분포적인 관계에 의해 결정된다는 가설.
즉, 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가지는 경향이 있다고 보는 것.
언어 모델은 분포 가설을 기반으로 한 모델을 의미함.
언어 모델은 단어들이 나타나는 확률 분포를 학습하여 다음 단어를 예측하는 작업을 수행함.
또한, 단어들의 의미와 문맥을 이해하고 문장 생성, 기계 번역 등
다양한 자연어 처리 작업에 활용할 수 있음.
예를 들어, "나는 밥을"이라는 문장에서 다음에 올 단어를 예측하는 언어 모델은
"먹는다"라는 단어가 나올 확률이 높다고 예측할 것이며,
이는 "나는", "밥을"과 "먹는다"가 자주 함께 등장하고, 분포적인 관계를 가지고 있기 때문임.
언어 모델은 훈련 데이터에서 이러한 분포적인 관계를 학습하여 단어들의 확률 분포를 추정함.
통계 기반 언어 모델에서는 등장 빈도와 확률을 통해 이를 계산함.
딥러닝 기반 언어 모델에서는 딥러닝 아키텍처를 사용하여
입력과 출력 사이의 관계를 모델링하고 확률적으로 예측함.
분포가설은 목표 단어의 단어들, 즉 window 크기에 따라 정의되는 문맥의 의미를 이용해
단어를 벡터로 표현하는 것이 목표이다.
이러한 목표와 관련하여 분포가설에 대한 표현방법을 분산표현이라 함.
PMI(Pointwise Mutual Information)
두 단어 간의 관련성을 측정하는 통계적 척도.
두 단어가 함께 등장하는 정도를 비교하여 그 관련성을 수치적으로 나타냄.
PMI는 주로 통계 기반 언어 모델에서 사용되는데, 단어 간의 분포적 관계를 파악하는 데 도움을 줌.
여기서 P(x, y)는 단어 x와 y가 함께 등장할 확률,
P(x)와 P(y)는 각각 단어 x와 y가 개별적으로 등장할 확률을 나타냄.
PMI의 값은 로그를 취하여 계산되므로,
값이 양수인 경우 단어 A와 B가 기대보다 자주 함께 등장하는 것을 나타내며,
값이 음수인 경우 두 단어가 기대보다 적게 함께 등장하는 것을 나타냄.
PMI는 두 단어 간의 상호정보량(Mutual Information)을 측정하여
두 단어 간의 관련성을 나타내는 척도로 사용함.
관련 웹사이트: https://arxiv.org/abs/1301.3781
Efficient Estimation of Word Representations in Vector Space
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best per
arxiv.org
3-2-6. 문장 구성 예측
1) 통계 기반 언어 모델:
단어들의 등장 빈도와 확률을 기반으로 문장의 구성을 예측하는 모델.
이전의 가설들은 단어의 등장 순서를 중요하게 고려하지 않았으나,
언어 모델은 단어들의 시퀀스 정보를 명시적으로 학습함.
언어 모델은 단어들이 동시에 나타날 확률을 반환하기도 함.
예를 들어, "나는 밥을 먹는다"라는 문장이 주어졌을 때,
언어 모델은 "나는", "밥을", "먹는다"라는 단어들이 동시에 나타날 확률을 추정함.
이를 통해 문장 전체를 확률적으로 표현할 수 있음.
2) 딥러닝 기반 언어 모델:
딥러닝 모델을 사용하여 입력과 출력 사이의 관계를 유연하게 정의할 수 있음.
통계 기반 언어 모델에 비해 더욱 유연한 예측과 학습이 가능.
통계 기반 모델과 달리 입력된 단어 시퀀스에 기반하여 다음 단어를 예측하는 작업을 수행함.
MLM(Masked Language Modeling): 마스크 언어 모델. 문장 중간의 특정 위치에 마스크를 씌워 어떤 단어가 오는지 예측하는 과정에서 학습을 진행함. 문장 전체를 보고 중간에 있는 단어를 예측하므로 양방향 학습이 가능하며, 대표적인 모델로 BERT가 있음. |
NTP(Next Token Prediction): 다음 문장 예측. 주어진 단어 시퀀스를 가지고 다음 단어로 어떤 단어가 올지 예측하는 과정에서 학습함. 단어를 순차적으로 입력받은 후 다음 단어를 맞춰야하기 때문에 일방향 학습이며, 대표적인 모델로 GPT와 ELMo가 있음. |
3-3. 텍스트 유사도(Text Similarity)
두 개의 텍스트(문장 또는 문서) 간의 유사성을 측정하는 방법.
텍스트 유사도는 자연어 처리 분야에서 많이 사용되며, 문서 분류, 정보 검색, 기계 번역, 질의 응답 시스템 등
다양한 응용 분야에서 중요한 요소임.
3-3-1. 유클리디안 거리 기반 유사도(Euclidean Distance-based Similarity)
유클리디안 거리는 두 점 사이의 직선 거리를 계산하는 방법.
벡터 공간에서 두 점 사이의 유클리디안 거리는 각 차원의 차이를 제곱한 후 합산한 값의 제곱근으로 계산.
유클리디안 거리를 기반으로 하는 유사도는 거리가 가까울수록 유사하다고 판단하기 때문에,
유클리디안 거리가 작을수록 두 텍스트나 벡터 간의 유사도가 높다고 볼 수 있음.
자카드 유사도나 코사인 유사도 만큼 유용하게 사용되는 방법은 아니나,
자연어처리 분야뿐만 아니라 다른 분야에서도 범용적으로 사용되는 거리 측정 기법.
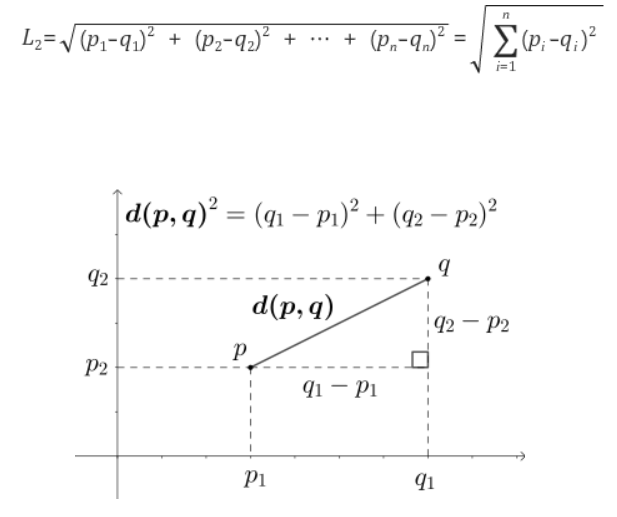
▲ p와 q 사이의 직선거리를 유클리드 거리(Euclidean Distance)라고 함.
3-3-2. 맨하탄 거리 기반 유사도(Manhattan Distance-based Similarity)
맨하탄 거리는 두 점 사이의 가로 세로로 이동하는 거리를 계산하는 방법.
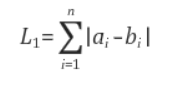
벡터 공간에서 두 점 사이의 맨하탄 거리는 각 차원의 차이를 절댓값으로 계산한 후 합산한 값.
맨하탄 거리를 기반으로 하는 유사도는 거리가 가까울수록 유사하다고 판단함.
맨하탄 거리는 유클리디안 거리와 달리 대각선 방향으로 이동하는 거리를 고려하지 않으므로,
좌표 평면에서 가로 세로로 이동하는 경로로 거리를 측정함.
다차원 공간 상에서 두 좌표간 최단거리를 구하는 방법이 아니다보니 잘 사용하지 않는 편.
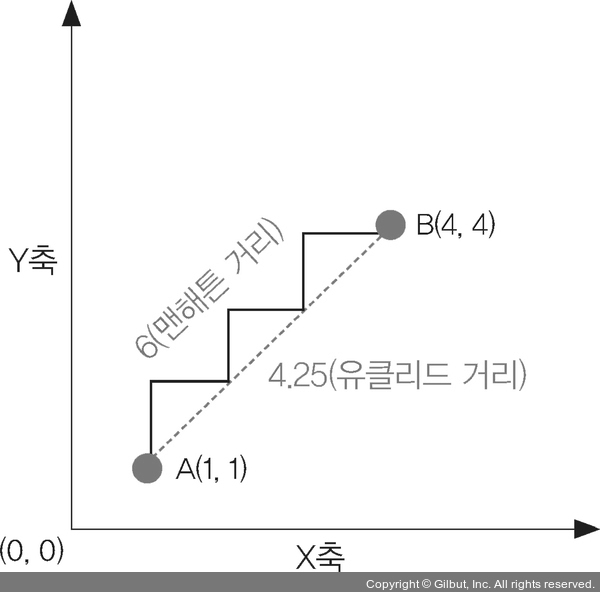
▲ 맨해튼 거리와 유클리드 거리의 비교
3-3-3. 코사인 유사도(Cosine Similarity)
벡터 간의 유사성을 계산하는 방법 중 하나임.
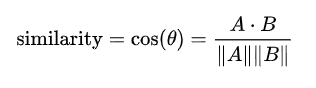
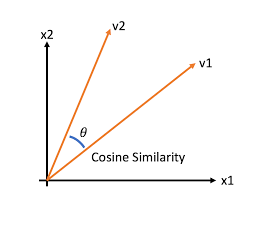
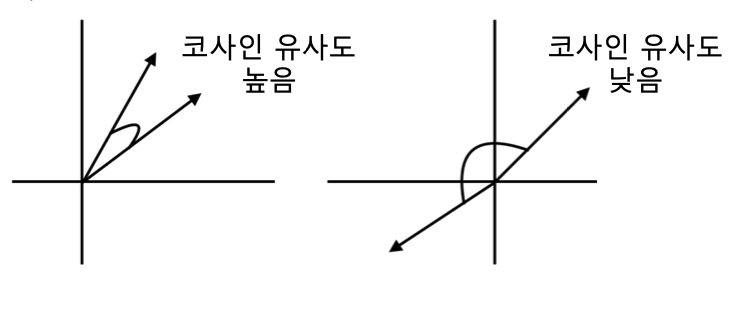
코사인 유사도는 두 벡터 간의 각도를 이용하여 유사도를 계산하며, 각도가 작을수록 유사도가 높다고 판단.
코사인 유사도는 방향에 대한 유사성을 측정하기 때문에 벡터의 크기에 영향을 받지 않음.
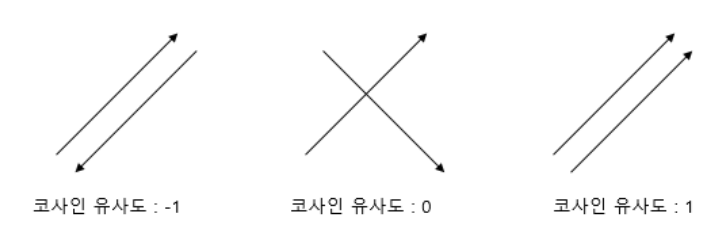
두 벡터의 방향이 완전히 동일한 경우는 1, 90도의 각을 이루면 0, 180도로 반대의 방향은 -1의 값을 가짐.
-1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사함.
두 벡터가 가리키는 강향이 얼마나 유사한가를 의미하기 때문에 자연어 내 유사도 계산에 더 적합함.
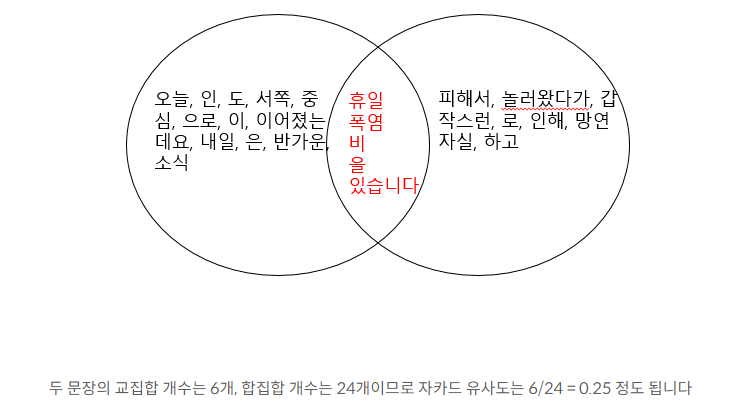
3-3-4. 자카드 유사도(Jaccard Similarity)
두 '집합' 간의 유사성을 측정하는 방법 중 하나. 특히, 텍스트나 문서의 유사도를 계산하는 데에 널리 활용됨.
두 집합의 교집합 크기를 전체 집합의 합집합 크기로 나눈 값으로 계산되며,
두 집합이 얼마나 많은 공통 요소를 가지고 있는지를 나타내는 지표임.
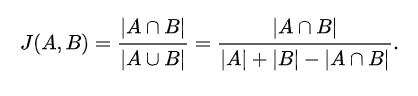
* 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식.
* 수치화된 벡터 없이 단어 집합만으로 계산할 수 있음.
* 두 집합의 교집합인 공통된 단어의 개수를 두 집합의 합집합, 전체 단어의 개수로 나누는 것
* 전체 합집합 중 공통의 단어의 개수에 따라 0과 1 사이의 값을 가지며, 1에 가까울 수록 유사도가 높음.
3-4. 유사도 측정 실습
* sen_1, sen_2: 의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략) * sen_1, sen_3: 의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경) * sen_2, sen_4: 문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정. * sen_1, sen_5: 의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정 * sen_1, sen_6: 의미가 서로 다른 문장 간 유사도 계산을 해볼 예정 |
sen_1 = '오늘 점심에 배가 너무 고파서 밥을 너무 많이 먹었다.'
sen_2 = '오늘 점심에 배가 고파서 밥을 많이 먹었다.'
sen_3 = '오늘 배가 너무 고파서 점심에 밥을 너무 많이 먹었다.'
sen_4 = '오늘 점심에 배가 고파서 비행기를 많이 먹었다.'
sen_5 = '어제 저녁에 밥을 너무 많이 먹었더니 배가 부르다.'
sen_6 = '이따가 오후 7시에 출발하는 비행기가 3시간 연착 되었다고 하네요.'
training_documents = [sen_1, sen_2, sen_3, sen_4, sen_5, sen_6]
# newpaper3k 라이브러리를 이용
!pip install newspaper3k
newspaper3k: 파이썬의 웹 스크래핑 라이브러리 중 하나로, 온라인 뉴스 기사를 수집하고 분석하는 기능을 제공함. newspaper3k를 사용하면 다양한 언론사의 기사를 자동으로 크롤링하여 텍스트 데이터를 추출할 수 있음. |
from newspaper import Article
URL = 'https://v.daum.net/v/20230628094638774'
# 따옴표처리된 부분은 임의의 뉴스 기사 링크를 삽입
article = Article(URL, language='ko')
article.download()
article.parse()
news_title = article.title
news_context = article.text
print('title:', news_title)
print('context:', news_context)

# 문장 분리 목적 전처리 실행
news_context = article.text.split('\n')
for text in news_context:
print(text)

# 여전히 문장이 길어 효과가 미미함. 따라서, 한국어 문장분리기인 kss를 이용하여 분리해볼 예정.
!pip install kss
kss(Korean Sentence Splitter): 한국어 문장 분리를 수행하는 파이썬 라이브러리. 주어진 텍스트를 문장 단위로 적절하게 분리하는 기능을 제공. |
import kss
# 코드를 한 줄로 분리하는 함수를 생성
def sentence_seperator(processed_context):
splited_context = [ ]
for text in processed_context:
text = text.strip()
if text:
splited_text = kss.split_sentences(text)
splited_context.extend(splited_text)
return splited_context
splited_context = sentence_seperator(news_context) # 문장 분리
for text in enumerate(splited_context):
print(text)

# 위에서 작성한 sen_1부터 sen_6까지의 6줄을 기사의 상단에 붙임
augmented_training_documents = training_documents + splited_context
for text in augmented_training_documents:
print(text)

# bag of words 기반 문서-단어 행렬을 활용한 문장 간 유사도 측정
from sklearn.feature_extraction.text import CountVectorizer
CountVectorizer: scikit-learn 라이브러리에서 제공하는 텍스트 데이터를 특성 벡터로 변환하는 기능을 제공하는 모듈. 이 모듈은 텍스트 데이터를 입력으로 받아 각 문서의 단어 빈도를 기반으로 특성 벡터를 생성. |
bow_vectorizer = CountVectorizer()
bow_vectorizer.fit(augmented_training_documents)
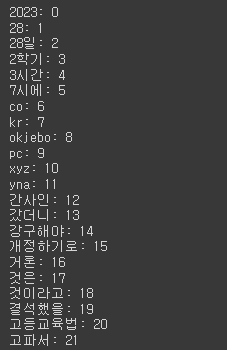
# 해당 단어들을 vocab으로 만듦. values값에는 index가 들어감.
word_idxes = bow_vectorizer.vocabulary_
word_idxes

# 해당 vocab의 index값을 오름차순하여 정렬
for key, idx in sorted(word_idxes.items()):
print(f'{key}: {idx}')
# vocab을 이용하여 원핫인코딩
import pandas as pd
result = [ ]
vocab = list(word_idxes.keys())
for i in range(len(augmented_training_documents)):
result.append([])
d = augmented_training_documents[i]
for j in range(len(vocab)):
target = vocab[j]
result[-1].append(d.count(target))
result
# DataFrame으로 만들기
tf = pd.DataFrame(result, columns=vocab)
tf
# 유사도를 측정할 문장들을 문장-단어 행렬기반 embedding 변환
bow_vector_sen_1 = bow_vectorizer.transform([sen_1]).toarray()[0]
bow_vector_sen_2 = bow_vectorizer.transform([sen_2]).toarray()[0]
bow_vector_sen_3 = bow_vectorizer.transform([sen_3]).toarray()[0]
bow_vector_sen_4 = bow_vectorizer.transform([sen_4]).toarray()[0]
bow_vector_sen_5 = bow_vectorizer.transform([sen_5]).toarray()[0]
bow_vector_sen_6 = bow_vectorizer.transform([sen_6]).toarray()[0]
print(bow_vector_sen_1)
print(bow_vector_sen_2)
print(bow_vector_sen_3)
print(bow_vector_sen_4)
print(bow_vector_sen_5)
print(bow_vector_sen_6)

# 코사인 기반 유사도 계산을 위해 함수를 정의
import numpy as np
from numpy import dot
from numpy.linalg import norm
dot: NumPy 라이브러리에서 제공되는 함수로, 두 배열의 내적(점곱)을 계산하는 기능을 수행. norm: NumPy 라이브러리에서 제공되는 함수로, 벡터의 크기 또는 길이를 계산하는 기능을 수행. |
def cos_sim(A, B):
return dot(A, B) / norm((A)*norm(B))
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략): {cos_sim(bow_vector_sen_1, bow_vector_sen_2)}') # 1이 나오면 가장 유사함.
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경): {cos_sim(bow_vector_sen_1, bow_vector_sen_3)}')
print(f'문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정.: {cos_sim(bow_vector_sen_2, bow_vector_sen_4)}')
print(f'의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정: {cos_sim(bow_vector_sen_1, bow_vector_sen_5)}')
print(f'의미가 서로 다른 문장 간 유사도 계산을 해볼 예정: {cos_sim(bow_vector_sen_1, bow_vector_sen_6)}')

# TF-IDF 기반 문서-단어 행렬을 활용한 문장 간 유사도 측정
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfv = TfidfVectorizer().fit(augmented_training_documents)
for key, idx in sorted(tfidfv.vocabulary_.items()):
print(f'{key}: {idx}')
# ndarray로 변환
sk_tf_idf = tfidfv.transform(augmented_training_documents).toarray()
print(sk_tf_idf)
# TF-IDF 행렬에서 얻어지는 유사도의 값들을 0~1로 스케일링하기위해 L1 정규화 진행
def l1_normalize(v):
norm = np.sum(v)
return v/norm
# data가 있는 객체의 생성
fidf_vectorizer = TfidfVectorizer()
fidf_matrix_l1 = fidf_vectorizer.fit_transform(augmented_training_documents)
fidf_norm_l1 = l1_normalize(fidf_matrix_l1)
fidf_norm_l1

# data 확인
tf_sen_1 = fidf_norm_l1[0:1]
tf_sen_2 = fidf_norm_l1[1:2]
tf_sen_3 = fidf_norm_l1[2:3]
tf_sen_4 = fidf_norm_l1[3:4]
tf_sen_5 = fidf_norm_l1[4:5]
tf_sen_6 = fidf_norm_l1[5:6]
# ndarray로 변경
tf_sen_1.toarray()
# 유클리디안 거리기반 유사도 측정 실습
from sklearn.metrics.pairwise import euclidean_distances
# sen1과 sen2의 유클리디안 거리기반 유사도
euclidean_distances(tf_sen_1, tf_sen_2)
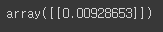
# 위의 내용을 함수로 변경
def euclidean_distances_value(vec_1, vec_2):
return round(euclidean_distances(vec_1, vec_2)[0][0], 3) # 차원을 낮춰서 소수점 셋째자리까지 출력
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략): {euclidean_distances_value(tf_sen_1, tf_sen_2)}')
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경): {euclidean_distances_value(tf_sen_1, tf_sen_3)}')
print(f'문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정.: {euclidean_distances_value(tf_sen_2, tf_sen_4)}')
print(f'의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정: {euclidean_distances_value(tf_sen_1, tf_sen_5)}')
print(f'의미가 서로 다른 문장 간 유사도 계산을 해볼 예정: {euclidean_distances_value(tf_sen_1, tf_sen_6)}')

# 맨하탄 거리기반 유사도 측정 실습
from sklearn.metrics.pairwise import manhattan_distances
def manhattan_distances_value(vec_1, vec_2):
return round(manhattan_distances(vec_1, vec_2)[0][0], 3)
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략): {manhattan_distances_value(tf_sen_1, tf_sen_2)}')
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경): {manhattan_distances_value(tf_sen_1, tf_sen_3)}')
print(f'문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정.: {manhattan_distances_value(tf_sen_2, tf_sen_4)}')
print(f'의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정: {manhattan_distances_value(tf_sen_1, tf_sen_5)}')
print(f'의미가 서로 다른 문장 간 유사도 계산을 해볼 예정: {manhattan_distances_value(tf_sen_1, tf_sen_6)}')

# 코사인 유사도 측정 실습
from sklearn.metrics.pairwise import cosine_similarity
def cosine_similarity_value(vec_1, vec_2):
return round(cosine_similarity(vec_1, vec_2)[0][0], 3)
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략): {cosine_similarity_value(tf_sen_1, tf_sen_2)}')
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경): {cosine_similarity_value(tf_sen_1, tf_sen_3)}')
print(f'문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정.: {cosine_similarity_value(tf_sen_2, tf_sen_4)}')
print(f'의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정: {cosine_similarity_value(tf_sen_1, tf_sen_5)}')
print(f'의미가 서로 다른 문장 간 유사도 계산을 해볼 예정: {cosine_similarity_value(tf_sen_1, tf_sen_6)}')

# 언어 모델을 활용한 문장 간 유사도 측정 # BERT모델 이용 예정
!pip install transformers
from transformers import AutoModel, AutoTokenizer, BertTokenizer
transformers: Hugging Face에서 개발한 파이썬 라이브러리로, 최신의 자연어 처리(NLP) 모델과 사전 학습된 다양한 언어 모델을 사용할 수 있게 해주는 도구. AutoModel: transformers 라이브러리의 모듈 중 하나로, 사전 학습된 언어 모델을 자동으로 선택하여 로드하는 기능을 제공. 주어진 모델 이름을 기반으로 가장 최신의 모델을 자동으로 선택하고, 해당 모델의 인스턴스를 생성하여 사용할 수 있음. 예를 들어, AutoModel.from_pretrained('bert-base-uncased')를 사용하면 BERT 언어 모델의 인스턴스를 생성할 수 있음. AutoTokenizer: transformers 라이브러리의 모듈 중 하나로, 토크나이저(tokenizer)를 자동으로 선택하여 로드하는 기능을 제공. AutoTokenizer.from_pretrained('bert-base-uncased')와 같이 사용하여 BERT 언어 모델에 해당하는 토크나이저를 생성할 수 있음. BertTokenizer: transformers 라이브러리에 포함된 모듈 중 하나로, BERT 언어 모델에 해당하는 토크나이저를 제공함. BERT 언어 모델은 토큰 분할을 위해 특정한 토크나이저를 사용하는데, 이를 위해 BertTokenizer를 사용할 수 있음. BertTokenizer는 BERT 토큰화를 수행하여 텍스트를 토큰으로 분할하고, 각 토큰에 대한 인덱스와 어텐션 마스크 등의 정보를 생성함. |
MODEL_NAME = "bert-base-multilingual-cased"
model = AutoModel.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# sen의 tensor 형태 객체 생성
bert_sen_1 = tokenizer(sen_1, return_tensors='pt')
bert_sen_2 = tokenizer(sen_2, return_tensors='pt')
bert_sen_3 = tokenizer(sen_3, return_tensors='pt')
bert_sen_4 = tokenizer(sen_4, return_tensors='pt')
bert_sen_5 = tokenizer(sen_5, return_tensors='pt')
bert_sen_6 = tokenizer(sen_6, return_tensors='pt')
# 각 embedding 된 문자에 대한 가중치(weight) 매개변수 생성
sen_1_outputs = model(**bert_sen_1) # **: dictionary 형태의 파라미터
sen_1_pooler_output = sen_1_outputs.pooler_output
sen_2_outputs = model(**bert_sen_2)
sen_2_pooler_output = sen_2_outputs.pooler_output
sen_3_outputs = model(**bert_sen_3)
sen_3_pooler_output = sen_3_outputs.pooler_output
sen_4_outputs = model(**bert_sen_4)
sen_4_pooler_output = sen_4_outputs.pooler_output
sen_5_outputs = model(**bert_sen_5)
sen_5_pooler_output = sen_5_outputs.pooler_output
sen_6_outputs = model(**bert_sen_6)
sen_6_pooler_output = sen_6_outputs.pooler_output
# 딥러닝을 이용하여 유사도를 계산할 예정. # torch의 neural network 모듈을 불러옴
from torch import nn
# 코사인 유사도 함수의 객체화
cos_sim = nn.CosineSimilarity(dim=1, eps=1e-6)
eps: nn.CosineSimilarity의 생성자 매개변수 중 하나로, 소수점 아래로 내적 연산을 수행할 때 발생할 수 있는 작은 값에 대한 보정값입니다. 코사인 유사도(Cosine Similarity)의 두 벡터가 거의 수직이거나 거의 평행할 경우에는 코사인 값이 매우 작거나 매우 큰 값이 될 수 있고, 이러한 경우 작은 수치 오차가 큰 영향을 미칠 수 있음. eps 매개변수는 이러한 작은 수치 오차를 보정하기 위한 작은 값임. 기본적으로 1e-8로 설정되어 있음. 일반적으로 이 값을 수정할 필요는 없지만, 특정 상황에서 안정성을 보장하기 위해 필요한 경우 적절한 값을 설정할 수 있음. |
# neral network(딥러닝)를 이용한 유사도 계산
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (조사가 생략): {cos_sim(sen_1_pooler_output, sen_2_pooler_output)}')
print(f'의미가 유사한 문장 간 유사도 계산을 해볼 예정 (순서가 변경): {cos_sim(sen_1_pooler_output, sen_3_pooler_output)}')
print(f'문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간의 유사도 계산을 해볼 예정.: {cos_sim(sen_2_pooler_output, sen_4_pooler_output)}')
print(f'의미는 다르지만 비슷한 주제를 갖는 문장 간 유사도 계산을 해볼 예정: {cos_sim(sen_1_pooler_output, sen_5_pooler_output)}')
print(f'의미가 서로 다른 문장 간 유사도 계산을 해볼 예정: {cos_sim(sen_1_pooler_output, sen_6_pooler_output)}')

딥러닝으로 학습을 하였을 때의 유사도 계산은 완벽하지 않기 때문에 오차가 많이 발생함.
BERT모델이 한국어에 대한 내용의 파악이 어려움
과제
아래12개의 정의 및 비슷한 예제를 찾아서 조사해오기
# 1. 재귀 호출
# 2. 버블 정렬
# 3. 삽입 정렬
# 4. 선택 정렬
# 5. 퀵 정렬
# 6. 순차 탐색
# 7. 이진 탐색
# 8. 너비우선탐색
# 9. 깊이우선탐색
# 10. 탐욕알고리즘
# 11. 최단경로알고리즘 (다익스트라 알고리즘)
# 12. 최소 신장 트리 알고리즘(MST)



