
2. 자연어 전처리
2-1. 코퍼스(Corpus)
일정한 주제나 목적을 가진 텍스트의 집합으로 사전적으로 '말뭉치', '대량의 텍스트 데이터' 를 의미함.
자연어 처리에 사용되는 훈련 데이터로 사용되며 일반적으로 문서, 대화, 뉴스 기사와 같은 다양한 형태로
구성될 수 있음.
주로 자연어 처리 모델이 언어의 특성을 학습하고 이해하는 데 도움을 줌.
예를 들어, 기계 번역 시스템을 구축하기 위해 영어-한국어 번역을 학습시키기 위한 코퍼스를 수집할 수 있음.
이 코퍼스는 수백만 개의 문장으로 구성된 영어 문장과 해당 문장에 대한 한국어 번역으로 이루어짐.
모델은 코퍼스에서 통계적인 패턴과 구조를 학습하여 문장의 의미를 이해하고,
언어의 문법적 특성과 관계를 파악함. 이렇게 학습한 모델은 실제 자연어 처리 작업에서 문장을 생성하거나
분류, 요약, 감성 분석 등 다양한 작업을 수행하는 데 사용될 수 있음.
2-2. 토큰화(Tokenization)
텍스트를 작은 단위로 나누는 과정. 이 과정에서 텍스트는 토큰(token)이라고 불리는 작은 단위로 분리됨.
토큰(Token)은 일반적으로 단어, 문장, 형태소 등과 같은 단위로 정의됨.
토큰화는 자연어 처리에서 중요한 단계임. 텍스트를 모델에 입력으로 사용하기 전에 구조화된 형태로 변환함.
원시 데이터를 가져와서 유용한 데이터 문자열로 변환하는 프로세스라고도 함.
토큰화를 통해 문장을 단어, 형태소로 분할하여 단어 단위의 통계적 패턴을 학습하거나 분석할 수 있음.
토큰화는 다양한 방법으로 수행될 수 있으며 일반적으로 공백을 기준으로 단어를 분리하는
"공백 기반 토큰화(whitespace-based tokenization)"가 가장 간단한 형태임.
그러나 언어에 따라 문법적 특성이나 구조에 따라 다른 토큰화 알고리즘이 적용될 수도 있음.
예를 들어 영어의 경우, 공백 기반 토큰화는 단어를 분리하는데 일반적으로 사용됨.
그러나 영어의 특수한 경우를 고려해야 할 수도 있음.
예를 들어, "can't"와 "don't"와 같은 축약된 형태의 단어는 분리되지 않고 하나의 토큰으로 처리되어야 함.
또한, 한국어의 경우에는 단어 단위로 토큰화할 경우에 의미나 문법적인 정보를 제대로 파악하기 어려울 수 있기 때문에 형태소 단위로 토큰화하는 것이 더 적절한 경우가 많음. 주로 사이버보안, NFT 생성에 사용됨.
2-2-1. 토큰화 과정의 필요성
1) 단어 단위 분석 가능:
단어는 문장의 최소 단위이며, 단어 단위로 통계적인 패턴, 의미적인 관계를 파악하는 것이 중요함.
예를 들어, 기계 번역이나 감성 분석 작업에서는 단어의 의미를 정확히 파악해야 함.
2) 문장 구조 분석 가능:
문장 구조 분석은 문장의 문법적인 특성을 이해하는 데 도움을 주며, 문장의 의미를 해석하는 데 중요함.
3) 형태소 분석 가능:
한국어나 일본어와 같은 언어에서는 형태소 분석이 중요한데,
단어를 형태소 단위로 분리하면 의미와 문법적인 특성을 더 잘 이해할 수 있음.
4) 문서 통계 분석 가능:
토큰화를 통해 얻은 통계 정보는 문서의 특성 파악이나 키워드 추출, 문서 분류 등에 사용할 수 있음.
5) 자연어 이해 능력 향상:
중복을 제거한 대규모 자연어 코퍼스 내 토큰의 집합(단어사전, vocab)을 사용하여 다양한 자연어를
효율적으로 표현 가능함.
2-3. 토큰화 종류
1) 공백 기반 토큰화(Whitespace Tokenization):
텍스트를 공백 문자(스페이스, 탭, 개행 등)를 기준으로 단어로 분리하는 방법.
가장 간단한 형태의 토큰화 방법이며, 일반적으로 영어나 일부 서양 언어에 적용됨.
예를 들어, "Hello, how are you?"라는 문장은 ["Hello,", "how", "are", "you?"]로 토큰화됨.
한국어의 경우 교착어이기 때문에 공백 기반 토큰화가 부적합함.
OOV(Out Of Vocabulary) 문제가 발생할 수 있음.
OOV(Out Of Vocabulary): 모델이 학습하지 않은 단어나 텍스트로 인해 발생하는 문제. 훈련 데이터에 포함되지 않은 단어나 텍스트가 모델에 입력되는 경우,모델은 이를 이해하거나 처리하는 데 어려움을 겪을 수 있음. OOV 문제는 자연어 처리에서 흔히 발생하는 문제 중 하나임. 훈련 데이터는 제한된 크기와 범위를 가지고 있기 때문에, 그 외의 단어나 문장은 모델이 이해하지 못하는 "미지의 영역"으로 간주되며, 이는 실제 응용 프로그램에서 문제가 될 수 있음. OOV 문제가 발생할 수 있는 경우: 1) 훈련 데이터에 포함되지 않은 단어: 훈련 데이터에 없는 새로운 단어가 모델에 입력되면 OOV 문제가 발생함. 이는 신조어, 오탈자, 이름 등과 같은 특정한 단어들이 포함될 때 발생할 수 있음. 2) 훈련 데이터 범위 밖의 문장 구조: 모델이 훈련된 데이터 범위를 벗어난 문장 구조를 처리해야 할 때 OOV 문제가 발생함. 예를 들어, 훈련 데이터에서는 짧은 문장만 다루었는데, 긴 문장이 입력되는 경우 문장 구조를 이해하지 못하고 오류를 발생시킬 수 있음. 3) 특정 도메인에서의 OOV: 모델이 훈련된 데이터와 다른 도메인에서 작업을 수행할 때 OOV 문제가 발생할 수 있음. 예를 들어, 훈련 데이터가 일상 대화에 대해 학습되었는데, 전문 용어가 포함된 도메인에서 모델을 사용할 경우 해당 용어를 인식하지 못하고 문제를 일으킬 수 있음. |
2) 구두점 기반 토큰화(Punctuation Tokenization):
텍스트를 구두점(마침표, 쉼표, 물음표 등)을 기준으로 단어로 분리하는 방법.
주로 문장 단위로 텍스트를 분할할 때 사용됨.
예를 들어, "Hello, how are you?"라는 문장은 ["Hello", ",", "how", "are", "you", "?"] 로 토큰화됨.
3) 정규식 기반 토큰화(Regular Expression Tokenization):
텍스트를 특정한 정규식 패턴에 맞게 분리하는 방법.
정규식은 토큰화에 유연성을 제공하며, 사용자가 원하는 특정 패턴에 따라 토큰화를 수행할 수 음.
예를 들어, "[A-Za-z]+"라는 정규식 패턴을 사용하면 알파벳으로 이루어진 단어만을 토큰화됨.
4) 문자 토큰화(Character Tokenization):
텍스트를 개별 문자로 분할하는 방법.
이 방법은 텍스트를 가장 작은 단위인 개별 문자로 토큰화하여 처리하는 것을 의미함.
예를 들어, "Hello"라는 단어는 ["H", "e", "l", "l", "o"]와 같이 토큰화됨.
5) 서브워드 토큰화(Subword Tokenization):
단어를 더 작은 단위인 서브워드(subword)로 분할하는 방법.
서브워드는 의미를 가지는 부분단어로, 단어 내의 접사, 접두사, 어간 등과 같은 의미적인 단위를 포함함.
서브워드 토큰화는 단어 수준의 토큰화와 문자 수준의 토큰화 사이의 중간 단계로,
단어를 더 작은 단위로 분할하여 언어의 구조와 표현을 더 잘 파악할 수 있음.
서브워드(subword): 단어보다 작은 의미 단위로, 단어 내에서 발생하는 구성 요소를 나타냄. 자연어 처리에서 서브워드는 단어를 더 작은 단위로 분할하여 언어의 구조와 표현을 더 잘 파악할 수 있게 함. 서브워드는 단어의 어간, 접사, 접두사, 첨가 등과 같은 구성 요소를 포함함. 예를 들어, "unhappiness"라는 단어는 "un-"(부정 접두사), "happi-"(어간), "-ness"(명사 접미사)로 구성됨. 이 경우, "un-", "happi-", "-ness"는 서브워드임. 서브워드는 언어의 의미와 문법적인 특성을 더 잘 파악할 수 있기 때문에 자연어 처리 작업에서 유용하게 사용됨. 서브워드 토큰화(Subword Tokenization)는 텍스트를 서브워드 단위로 분할하는 과정을 의미하며, 텍스트의 희소성을 줄이고 OOV(Out Of Vocabulary) 문제를 완화하는 데 도움이 됨. 또한, 서브워드 표현은 훈련 데이터에 없는 단어를 효과적으로 처리할 수 있게 함. 서브워드 토큰화를 위해 바이트 페어 인코딩(Byte Pair Encoding, BPE)과 같은 알고리즘을 사용하거나, 형태소 분석기를 활용하여 단어를 서브워드로 분할할 수 있음. |
바이트 페어 인코딩(Byte Pair Encoding, BPE): 텍스트를 서브워드(subword) 단위로 분할하는 압축 알고리즘. 훈련 데이터에서 가장 자주 등장하는 바이트 쌍을 합쳐가며 서브워드를 만들어내는 과정을 반복함. BPE 알고리즘은 초기에는 문자 단위로 텍스트를 분할하여 시작함. 그런 다음, 주어진 텍스트에서 가장 자주 등장하는 바이트 쌍(두 개의 연속된 바이트)을 찾아 하나의 새로운 바이트로 합침. 이 합쳐진 바이트는 새로운 단어로 간주되어 텍스트에 추가됨. 이 과정을 반복하면서 텍스트의 빈도수에 따라 자주 등장하는 바이트 쌍이 서브워드로 합쳐지며, 점차적으로 텍스트가 서브워드 단위로 압축됨. BPE는 빈도수에 기반하여 자주 등장하는 바이트 쌍을 우선적으로 합치기 때문에, 자주 등장하는 어휘나 패턴을 잘 파악할 수 있으며 이를 통해 희소성을 줄이고 언어의 표현 능력을 향상시킬 수 있음. 또한, BPE는 OOV(Out Of Vocabulary) 문제를 완화하는 데 도움이 되며, 기계 번역, 자동 완성, 문서 요약 등의 자연어 처리 작업에서 널리 사용됨. BPE 알고리즘은 자연어 처리 라이브러리나 토크나이저에 구현되어 있으며, 훈련 데이터에 적용하여 서브워드 단위의 어휘를 생성할 수 있음. 이후 모델은 이 어휘를 기반으로 텍스트를 서브워드 단위로 분할하여 처리함. |
2-4. 정제(Cleaning)
텍스트 데이터를 사전 처리하는 단계 중 하나로, 토큰화작업에 불필요한 요소를 제거하거나 수정하여
텍스트의 품질을 개선하는 과정을 의미함.
정제 작업은 자연어 처리에서 텍스트 데이터를 처리하기 전에 일반적으로 수행되는 중요한 단계임.
어떤 특성이 불필요한 요소인지 판단하는 것과, 완벽한 불필요 요소의 제거는 어렵기 때문에
일종의 합의점을 찾아야 함.
2-4-1. 종류
1) 불용어(Stopword) 제거:
분석에 불필요한 단어나 불용어(stop words)를 제거하여 처리할 토큰 수를 줄이고 모델의 성능을 개선함.
불용어는 주로 언어의 문법이나 구조를 이해하는 데 도움이 되지 않는 단어로,
예를 들면 "a", "the", "is"와 같은 단어들이 있음.
'NLTK 라이브러리'에서 자주 사용되는 단어들을 불용어로 정의하고 있음.
불용어의 정의는 가변적이기 때문에 추가하고 싶은 불용어가 있다면 직접 정의할 수 있음.
보편적인 한국어 內 불용어 리스트:
https://www.ranks.nl/stopwords/korean
Korean Stopwords
www.ranks.nl
2) 특수 문자 제거:
텍스트에 있는 특수 문자나 문장 부호를 제거하거나 대체하여 토큰화 과정을 간소화하고,
문장 구조를 유지하는 데 도움을 줌.
3) 코퍼스 내 등장빈도가 적은 단어의 제거:
코퍼스 내 단어들의 빈도를 분석하여 분포를 보고 특정 threshold(한계점)를 설정한 후,
threshold(한계점) 이하의 단어들을 제거.
2-4-2. 유의해야할 점
@와 같은 특수문자는 일반적인 작업에서는 정보량이 적은 토큰일 수 있지만
'이메일'과 관련된 내용을 판단해야 하는 작업에서는 유용한 토큰으로 사용될 수 있음.
또한, 자연어 처리 작업에서 데이터를 수집한 이후에는 항상 목적에 맞지 않는 노이즈가 있는지의 여부를
검사하고 발견한 노이즈를 정제하기 위한 노력이 필요함.
2-5. 정규화(Normalization)
일반적인 머신러닝 작업에서 학습 데이터의 값들이 적당한 범위를 유지하도록
데이터의 범위를 변환하거나 스케일링하는 과정.
모든 데이터가 같은 정도의 스케일로 반영되도록 하는 것을 목표로 함.
표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어주는 것이 정규화의 핵심임.
2-5-1. 종류
1) 단어 형태 통일:
단어의 다양한 형태를 표준화하여 동일한 의미를 가진 단어들을 일관된 형태로 표현함.
예를 들어, "run", "running", "ran"과 같은 단어들을 "run"으로 표준화할 수 있음.
2) 축약형 확장:
축약된 단어를 원형이나 전체 형태로 확장하여 텍스트 데이터의 가독성과 일관성을 높임.
예를 들어, "can't"를 "cannot"으로 변환하거나 "I'm"을 "I am"으로 변환할 수 있음.
3) 표현의 통일성:
동일한 의미를 가지는 여러 가지 표현을 통일하여 언어 처리 작업에서 일관성을 유지함.
예를 들어, "U.S.A", "USA", "United States of America" 등의 표현을 "United States"로 표준화할 수 있음.
4) 철자 교정:
오탈자나 맞춤법 오류를 수정하여 텍스트의 가독성과 일관성을 향상시킴.
이를 위해 철자 교정 도구나 외부 라이브러리를 사용할 수 있음.
5) 줄임말 확장:
줄임말이나 약어를 해당하는 전체 단어로 확장하여 텍스트의 의미를 명확하게 함.
예를 들어, "Mr."를 "Mister"로 변환하거나 "etc."를 "et cetera"로 변환할 수 있음.
6) 특수문자 제거:
텍스트에 있는 특수 문자나 문장 부호를 제거하거나 대체하여 토큰화 과정을 간소화하고
문장 구조를 유지하는 데 도움을 줌.
7) 불필요한 공백 제거:
텍스트에 있는 추가적인 공백을 제거하여 텍스트의 일관성을 유지하고 토큰화 과정을 단순화함.
8) 대소문자 통일:
텍스트에 있는 대소문자를 통일시켜 토큰화 작업 중에 대소문자 구분을 제거하고 어휘의 일관성을 유지함.
9) 특정 언어 관련 작업:
특정 언어에 특화된 정규화 작업이 있을 수 있음.
예를 들어, 한국어의 경우 조사나 어미 등을 제거하거나 처리하는 작업이 포함될 수 있음.
2-5-2. 유의점
규칙이 너무 엄격한 정규화 방법 → 부작용이 심해 학습에 악영향을 줄 수 있음.
'원본의 의미를 최대한 유지하는 것'이 학습에 더욱 도움이 됨.
대화에서 사용하는 의미가 비슷한 이모티콘들을 통합하는 정규화 작업도 존재함.
(예: "ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ" → "ㅋㅋ")
2-6. 한국어 데이터의 전처리
2-6-1. 한국어의 특성
한국어는 조사나 어미가 발달되어있음.
띄어쓰기가 가능한 단위를 '어절'이라고 하는데 어절 토큰화와 단어 토큰화가 상이함.
→ 띄어쓰기만으로 단어를 분리하면 의미적인 훼손이 일어날 수 있음.
2-6-2. 형태소 분석
형태소를 비롯하여 어근/접두사/접미사/품사 등 다양한 언어적 속성의 구조를 파악하는 것을 의미.
형태소 분석 과정은 한국어 단어에서 형태소를 추출하여 분리하는 작업이며
이후에 필요에 따라 사전 정의된 품사를 해당 단어에 태깅(Tagging)하는 작업을 하기도 함.
(태깅(Tagging): 형태소의 뜻과 문맥을 고려하여 단어에 품사를 일치시키는 것.)
형태소 분석 방법
한국어의 다양한 형태소를 분석하고 분류하기 위한 목적으로 'KoNLPy 패키지'에서 분석기를 사용함.
KoNLPy 패키지의 다양한 함수를 사용하여 한국어 내 다양한 전처리를 진행할 수 있음.
1) Mecab: 일본어용 형태소 분석기를 한국어로 사용할 수 있도록 수정
2) Okt: 오픈소스 한국어 분석기. 과거 트위터 형태소 분석기.
3) Komoran: Shineware에서 개발
4) Kkma: 서울대학교 IDS 연구실 개발
각 형태소 분석기는 성능과 결과가 모두 다르기 때문에, 사용하고자하는 용도에
어떤 형태소 분석기가 적절한지를 판단하는 것이 중요함.
(예: 분석 속도를 중시한다면 Mecal을 사용하는 것이 유리함.)
2-7. 데이터 전처리 예제 실습
# 뉴스기사를 크롤링해주는 라이브러리 설치
!pip install newspaper3k
Newspaper3k: 파이썬의 라이브러리로, 웹에서 기사, 뉴스 및 기타 텍스트 기사를 추출하고 처리하는 데 사용. 이 라이브러리는 웹 사이트에서 기사의 제목, 내용, 작성자, 게시 날짜 및 기타 관련 정보를 가져올 수 있음. |
# 지원하는 언어 확인
import newspaper
newspaper.languages()

# 뉴스기사를 지원하는 class 불러오기
from newspaper import Article
# 뉴스기사 예시본 가져오기
URL = 'https://v.daum.net/v/xyz5YQI9vW'
# 따옴표처리된 URL은 임의의 기사에 대한 링크를 입력한 것
article = Article(URL, language='ko')
# 크롤링하기
article.download()
article.parse()
print('title:', article.title)
print('content:', article.text)

# 전처리 실습 목적의 임의의 text 추가
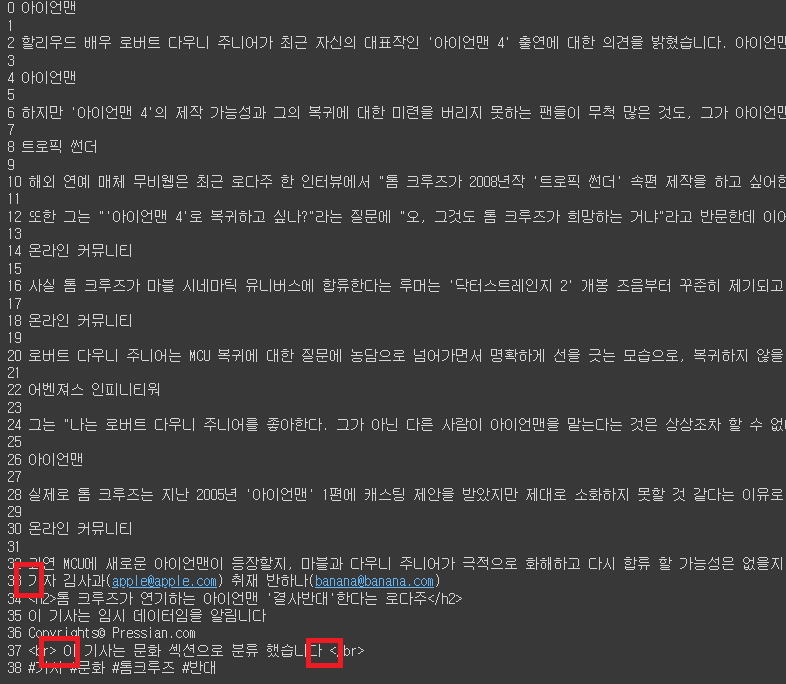
additional_info = [
"※ 기자 김사과(apple@apple.com) 취재 반하나(banana@banana.com)",
"<h2>톰 크루즈가 연기하는 아이언맨 '결사반대'한다는 로다주</h2>",
"이 기사는 임시 데이터임을 알림니다 … ",
"Copyrights© Pressian.com",
"<br> ☞ 이 기사는 문화 섹션으로 분류 했습니다 … </br>",
"#기사 #문화 #톰크루즈 #반대"
]
# 본문을 문장별로 나눈 후, 임의의 text를 추가함
context = article.text.split("\n")
context += additional_info
# 문장에 번호를 부여하여 같이 출력
for i, text in enumerate(context):
print(i, text)
# 위와 같이 예제로 사용할 기사를 준비함. 이후 전처리를 진행할 예정

2-7-1. 불용어 제거
# 불용어에 대해 정의
# '이하', '바로', '☞', '※', '…' 라는 단어를 text에서 삭제할 예정
stopwords = ['이하', '바로', '☞', '※', '…']
# 불용어 제거 함수
def delete_stopwords(context):
preprocessed_text = [ ]
for text in context:
text = [w for w in text.split(' ') if w not in stopwords]
preprocessed_text.append(' '.join(text))
return preprocessed_text
processed_context = delete_stopwords(context)
for i, text in enumerate(processed_context):
print(i, text)
# 아래 빨간 밑줄이 기존 불용어가 같이 삽입되어있었던 부분. 현재는 사라진 것을 확인할 수 있음.
2-7-2. HTML 태그 제거
# 관련 모듈(정규식을 사용할 수 있게 해줌) 불러오기
import re
def delete_html_tag(context):
preprocessed_text = []
for text in context:
text = re.sub(r'<[^>]+>', '', text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
processed_context = delete_html_tag(processed_context)
for i, text in enumerate(processed_context):
print(i, text)
# 아래 빨간 밑줄이 기존 HTML 태그가 같이 삽입되어있었던 부분. 현재는 사라진 것을 확인할 수 있음.
"re": 파이썬의 정규 표현식(Regular Expression) 모듈 |

2-7-3. 문장 분리
학습 데이터를 구성할 때 입력 데이터의 단위를 설정하기 애매해지므로
문장 단위로 모델이 학습하도록 유도하기 위해 문장 분리가 필요.
교육 간 한국어 문장 분리기 중 가장 성능이 우수한 것으로 알려진 kss 라이브러리를 사용할 예정.
https://github.com/hyunwoongko/kss
GitHub - hyunwoongko/kss: Kss: A Toolkit for Korean sentence segmentation
Kss: A Toolkit for Korean sentence segmentation. Contribute to hyunwoongko/kss development by creating an account on GitHub.
github.com
# 라이브러리 설치
!pip install kss
"kss": 한국어 문장 분리기(Korean Sentence Splitter)인 라이브러리. 이 라이브러리는 한국어 텍스트에서 문장을 인식하고 분리하는 기능을 제공. |
import kss
def sentence_seperator(processed_context):
splited_context = [ ]
for text in processed_context:
text = text.strip()
if text:
splited_text = kss.split_sentences(text)
splited_context.append(splited_text)
return splited_context
splited_context = sentence_seperator(processed_context)
for i, text in enumerate(splited_context):
print (i, text)
# 문장별로 분리가 된 것을 확인할 수 있음.

2-7-4. 이메일 제거
def delete_email(context):
preprocessed_text = []
for text in context:
text = re.sub(r'[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+', '',text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_email(splited_context)
for i, text in enumerate(preprocessed_context):
print (i, text)
# 아래 빨간 밑줄이 기존 이메일이 같이 삽입되어있었던 부분. 현재는 사라진 것을 확인할 수 있음.

2-7-5. 해시태그 제거
def delete_hashtag(context):
preprocessed_text = []
for text in context:
text = re.sub(r'#\S+', '', text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_hashtag(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 아래 빨간 밑줄이 기존 해시태그가 삽입되어있었던 부분. 현재는 사라진 것을 확인할 수 있음.

2-7-6. 저작권 관련 텍스트 제거
def delete_copyright(context):
re_patterns = [
r'\<저작권자(\(c\)|©|(C)|(\(C\))).+?\>',
r'(Copyrights)|(\(c\))|(\(C\))|©|(C)|'
]
preprocessed_text = []
for text in context:
for re_pattern in re_patterns:
text = re.sub(re_pattern, "", text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_copyright(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 아래 빨간 밑줄이 기존 저작권관련 텍스트가 삽입되어있었던 부분. 현재는 사라진 것을 확인할 수 있음.

2-7-7. 반복 횟수가 많은 문자의 정규화
!pip install soynlp
from soynlp.normalizer import *
print(repeat_normalize('ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ', num_repeats=2))
print(repeat_normalize('야!!!!!!!!!!! 너!!!!!!!!!!! 지금 뭐함????????????ㅠㅠㅠㅠㅠㅠㅠㅠ', num_repeats=2))
# 자음, 모음 한정이므로 특수문자는 바뀌지 않음.

2-7-8. 띄어쓰기 보정
!pip install git+ht1tps://github.com/haven-jeon/PyKoSpacing.git from pykospacing import Spacing spacing = Spacing() spacing('아버지가방에들어가신다')
<오류 발생. 나중에 다시 진행할 예정>
2-7-9. 중복 문장 정규화
from collections import OrderedDict
# 중복 문장을 제거해주는 함수의 생성
def duplicated_sentence_normalizer(context):
context = list(OrderedDict.fromkeys(context))
return context
normalized_context = duplicated_sentence_normalizer(preprocessed_context)
for i, text in enumerate(normalized_context):
print(i, text)

2-7-10. 정제(Cleaning)
* 형태소 분석 기반 필터링
* 데이터 후처리
# '아버지가방에들어가신다' 라는 문장을 분석
!pip install konlpy
!pip install mecab-python
!bash <(curl -s ht1tps://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
from konlpy.tag import Mecab # Mecab: 일본어분석기를 기반으로 만들어진 한국어분석기. 속도가 빠르기때문에 많이 이용함.
mecab = Mecab()
morphs = mecab.pos('아버지가방에들어가신다', join=False)
print(morphs)

# 명사(NNG), 동사(V). 형용사(J)가 포함된 문장들로 필터링할 예정
def morph_filter(context):
NN_TAGS = ['NNG', 'NNP', 'NNB' 'NP'] # 명사류 태그
V_TAGS = ['VV', 'VA', 'VX', 'VCP', 'VCN', 'XSN', 'XSA', 'XSV'] # 동사류 태그
J_TAGS = ['JKS', 'J', 'JO', 'JK', 'JKC', 'JKG', 'JKB', 'JKV', 'JKQ', 'JX', 'JC', 'JKI', 'JKO', 'JKM', 'ETM'] # 형용사류 태그
preprocessed_text = []
for text in context:
morphs = mecab.pos(text, join=False)
nn_flag = False
v_flag = False
j_flag = False
for morph in morphs:
pos_tags = morph[1].split("+") # ('신다', 'EP+EC')와 같은 부분의 해결목적
for pos_tag in pos_tags:
if not nn_flag and pos_tag in NN_TAGS:
nn_flag = True
if not v_flag and pos_tag in V_TAGS:
v_flag = True
if not j_flag and pos_tag in J_TAGS:
j_flag = True
if nn_flag and v_flag and j_flag:
preprocessed_text.append(text)
break
return preprocessed_text
post_processed_context = morph_filter(normalized_context)
for i, text in enumerate(post_processed_context):
print(i, text)
2-7-11. 문장 길이 기반 필터링
def min_max_filter(min_len, max_len, context):
preprocessed_text = []
for text in context:
if min_len < len(text) and len(text) < max_len:
preprocessed_text.append(text)
return preprocessed_text
# text의 각 문장들을 20자 이상, 60자 미만의 글자들로 구성되도록 필터링
post_processed_context = min_max_filter(20, 60, post_processed_context)
for i, text in enumerate(post_processed_context):
print(i, text)

2-7-12. 토큰화(Tokenization)
# 토큰화를 위해 tensorflow 모듈을 이용할 예정
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(post_processed_context)
tokenizer

word2idx = tokenizer.word_index
idx2word = {value: key for key, value in word2idx.items()}
idx2word
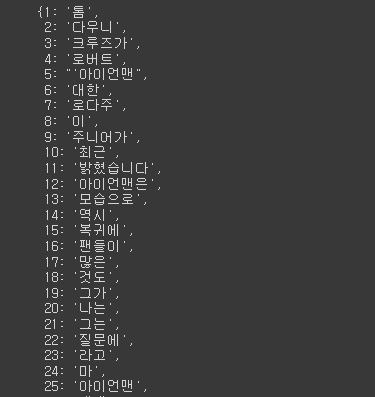
# 인코드 내역 확인
encoded = tokenizer.texts_to_sequences(post_processed_context)
encoded
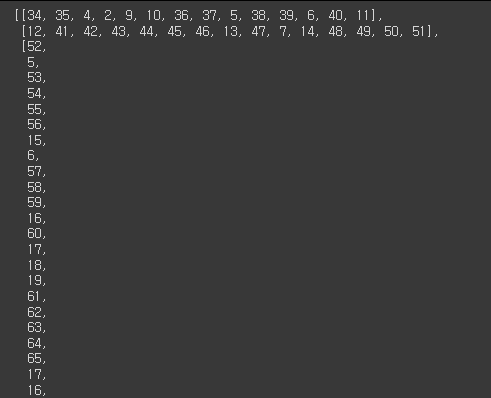
# vocab size의 확인
vocab_size = len(word2idx) + 1
vocab_size
print(f'단어 사전의 크기(vocab의 크기): {vocab_size}')

# 첫번째 줄의 문장에 대한 인덱스 번호의 확인
print(encoded[0])

과제
"BPE 알고리즘", "WordPiece Tokenizer 알고리즘"에 대해 조사하고
해당 알고리즘을 잘 설명할 수 있는 예제와 실습과제를 완성해보자.
BPE(Byte Pair Encoding)
* 코퍼스 내 단어의 등장 빈도에 따라 서브워드를 구축하는데 BPE 알고리즘을 주로 사용함.
* 관련 논문:
https://arxiv.org/abs/1508.07909 / 2016 Neural Machine Translation of Rare Words with Subword Units
라는 논문에서 처음으로 제안됨.
* 글자 단위에서 점진적으로 서브워드 집합을 만들어내는 Bottom-up 방식의 접근방식으로 자연어 코퍼스에 있는 모든 단어들을 글자 단위로 분리한 뒤에 등장 빈도에 따라 글자들을 서브워드로 통합하는 방식.
WPT(WordPiece Tokenizer)
* 관련 논문:
https://arxiv.org/abs/1609.08144 / 2016년 Google's Neural Machine Translation System Bridging the Gap between Human and Machine Translation 라는 논문에서 처음으로 제안됨.
* 병합할 두 문자가 있을 때 각 문자가 따로 있을 때를 더 줃요시 여기는지, 병합되었을 때를 더 중요시 여기는지의 차이점을 둠.
* GPT모델과 같은 생성모델의 경우에는 BPE 알고리즘을 사용
* BERT, ELECTRA와 같은 자연어 이해 모델에서는 WordPiece Tokenizer를 주로 사용.



