
20. 포켓몬 분류 예제
20-1. 포켓몬 분류 데이터셋
train에 사용될 포켓몬 149종 데이터셋:
https://www.kaggle.com/datasets/thedagger/pokemon-generation-one
Pokemon Generation One
Gotta train 'em all!
www.kaggle.com
validation에 사용될 포켓몬 898종 데이터셋:
https://www.kaggle.com/hlrhegemony/pokemon-image-dataset
Complete Pokemon Image Dataset
2,500+ clean labeled images, all official art, for Generations 1 through 8.
www.kaggle.com
20-2. 데이터셋 다운로드 및 압축해제
import os
os.environ['KAGGLE_USERNAME'] = 'yunjaecho1'
os.environ['KAGGLE_KEY'] = '8f9e71f399390930859cd156dafb12c1'
# 다운로드
!kaggle datasets download -d thedagger/pokemon-generation-one
!kaggle datasets download -d hlrhegemony/pokemon-image-dataset
# 압축해제
!unzip -q pokemon-generation-one
!unzip -q pokemon-image-dataset
20-3. 디렉토리 가공
# 'dataset', 'images'로 되어있는 디렉토리의 이름을 각각 'train', 'validation'으로 변경.
os.rename('/content/dataset','/content/train')
os.rename('/content/images','/content/validation')
# validation(898개)에 있으나 train(149개)에 없는 749개의 디렉토리를 제거.
import shutil
train_dir = '/content/train'
validation_dir = '/content/validation'
validation_dirs = os.listdir(validation_dir)
for directory in validation_dirs:
directory_path = os.path.join(validation_dir, directory)
if os.path.isdir(directory_path) and not os.path.exists(os.path.join(train_dir, directory)):
shutil.rmtree(directory_path)
#train(149개)에 있으나 validation(898개)에 없는 2종의 포켓몬을 찾아 디렉토리를 추가로 만들고
# 인터넷에서 2종의 포켓몬 이미지를 validation 디렉토리에 추가.
# train과 validation을 비교하여 누락된 포켓몬 찾기
train_dirs = os.listdir(train_dir)
validation_dirs = os.listdir(validation_dir)
missing_dirs = [ ]
for directory in train_dirs:
if directory not in validation_dirs:
missing_dirs.append(directory)
for directory in missing_dirs:
print(directory)
# 누락된 포켓몬은 MrMime, Farfetched임을 알 수 있음.
# 누락된 포켓몬의 사진을 인터넷에서 찾아 로컬드라이브에 삽입한 후 validation 디렉토리로 파일이동
download_farfetched_path = '/content/farfetched.png'
download_mrmime_path = '/content/mrmime.png'
destination_farfetched_dir = '/content/validation/Farfetched'
destination_mrmime_dir = '/content/validation/Mrmime'
os.makedirs(destination_farfetched_dir)
os.makedirs(destination_mrmime_dir)
shutil.move(download_farfetched_path, destination_farfetched_dir)
shutil.move(download_mrmime_path, destination_mrmime_dir)
# validation에 존재하는 'dataset' 디렉토리의 제거
directory_path = "/content/train/dataset"
shutil.rmtree(directory_path)
20-4. PyTorch 관련 패키지 로드 및 GPU 사용 설정
# pytorch 관련 패키지 로드
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
from torch.nn import functional as F
# gpu 사용
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
20-5. Data의 Transform
# transforms.Compose를 통해 사이즈, affine, randomhorizontalflip, tensor변환을 한꺼번에 처리
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'validation': transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor()
])
}
20-6. dataset, dataloader의 생성
# dataset 생성
image_datasets = {
'train': datasets.ImageFolder('/content/train', data_transforms['train']),
'validation': datasets.ImageFolder('/content/validation', data_transforms['validation'])
}
# dataloader 생성
dataloaders = {
'train': DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}
# train과 validation에 대한 각각의 dataloader에 포함된 샘플 수 확인
print(len(dataloaders['train']))
print(len(dataloaders['validation']))

20-7. batch 1개에 대한 이미지 출력
imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4, 8, figsize=(20,10))
for img, label, ax in zip(imgs, labels, axes.flatten()):
ax.set_title(label.item())
ax.imshow(img.permute(1,2,0)) # 일반적인 탠서: (높이, 너비, 채널) # permute(1,2,0)=(너비,채널,높이)
ax.axis('off')
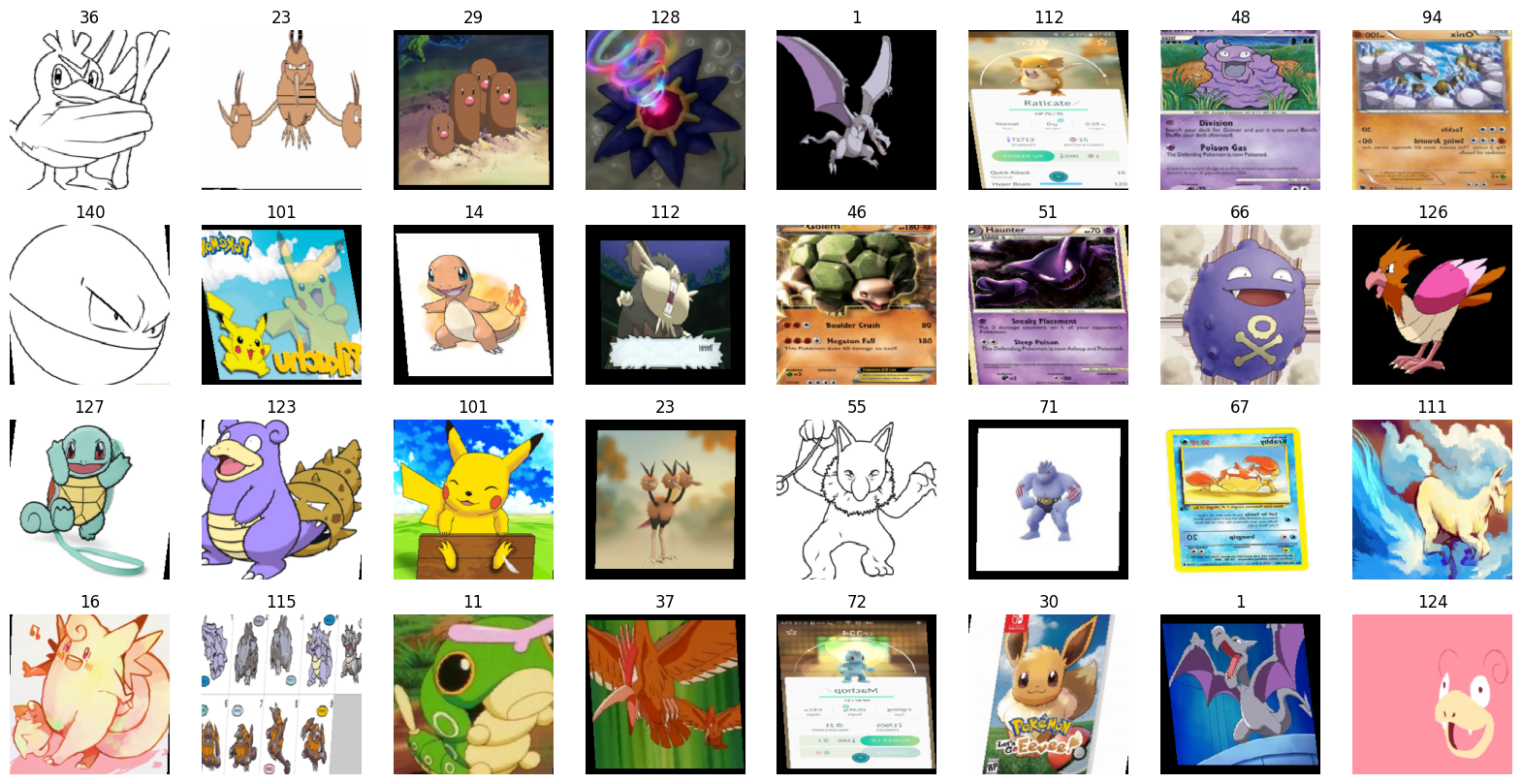
클래스 이름 확인하기 전체 선택시: image_datasets['train'].classes 단일 선택시: image_datasets['train'].classes[81] |
20-8. 모델 사용 및 수정
여기서 사전학습된 모델은 'EfficientNetB4'를 사용할 예정.
포켓몬 분류는 '다항분류'이므로, 모델 및 학습이 단항분류와 다르게 진행됨을 숙지해야 함.
단항 분류 (Binary Classification): 단항 분류는 두 개의 클래스 레이블 중 하나로 분류하는 작업. 이는 예/아니오, 양성/음성, 정상/이상 등과 같은 이진적인 결정을 내리는 문제에 적용됨. 예) 이메일 분류: 이메일을 스팸/스팸이 아님으로 분류. 신용카드 사기 탐지: 거래를 사기/사기가 아님으로 분류. 암 진단: 환자를 암/암이 아님으로 분류. 감성 분석: 텍스트 리뷰를 긍정적/부정적으로 분류. 다항 분류 (Multiclass Classification): 다항 분류는 세 개 이상의 클래스 레이블 중 하나로 분류하는 작업. 다항 분류는 주어진 입력을 여러 클래스 중 하나에 할당하는 문제에 적용됨. 예) 손글씨 숫자 인식: 숫자 0부터 9까지의 숫자로 분류. 포켓몬 분류: 해당 페이지의 예시와 같이 다양한 포켓몬으로 분류. 옷 종류 분류: 티셔츠, 바지, 원피스, 신발 등 다양한 옷의 종류로 분류. 자동차 분류: 세단, SUV, 트럭, 스포츠카 등 다양한 자동차 유형으로 분류. |
# 모델의 사용
model = models.efficientnet_b4(weights='IMAGENET1K_V1').to(device)
print(model)
# model을 print했을 때, 맨 아래부분을 확인하여 해당부분의 이름을 확인. (예제는 Classifier)

# 파라미터를 수정하지 않도록 설정.
for param in model.parameters():
param.requires_grad = False # weight와 bias: 역전파에 의한 업데이트를 하지 않겠음
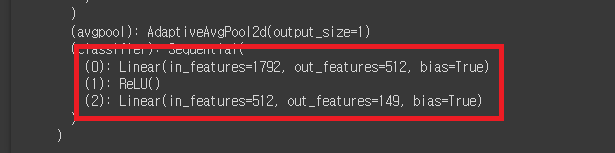
# 모델의 수정
model.classifier = nn.Sequential(
nn.Linear(1792, 512), # 512는 모델 중간 레이어의 출력 차원을 의미. 출력차원은 임의로 설정 가능
nn.ReLU(), # 모델의 비선형성을 추가하는 것은 일반적인 신경망 모델의 관행
nn.Linear(512, 149) # 최종 출력값은 149로 설정. # 최종적으로 149종의 포켓몬 중에서 분류를 진행
).to(device)
print(model)
# model을 print했을 때, 맨 아래부분을 확인하여 입력값, 출력값을 확인.
20-9. 학습
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 배치단위 loss 저장
sum_losses = sum_losses + loss.item()
# 배치단위 정확도 저장
y_prob = nn.Softmax(1)(y_pred) # Softmax(1): Softmax 함수가 두 번째 차원(axis)에 대해 작동
y_pred_index = torch.argmax(y_prob, axis=1) # argmax(): 가장 큰 확률을 가지는 클래스의 인덱스를 추출
# axis=1: 두 번째 차원에서 최댓값을 찾음
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100 # 백분율
# 정확도(acc): 실제레이블(y_batch)과 예측결과(y_pred_index)를 비교하여 예측된 데이터 포인트의
비율을 계산. 레이블과 예측 결과를 비교한 결과는 Boolean형태의 텐서
sum_accs = sum_accs + acc.item()
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}:Epoch{epoch+1:4d}/{epochs}, Loss:{avg_loss:.4f}, Accuracy:{avg_acc:.2f}%')

20-10. 학습된 모델의 저장
# 모델 저장
torch.save(model.state_dict(), 'model.h5')
# 빈 모델 생성 후 수정
model = models.efficientnet_b4().to(device)
model.classifier = nn.Sequential(
nn.Linear(1792, 512),
nn.ReLU(),
nn.Linear(512, 149)
).to(device)
# 빈 모델에 저장된 모델 불러오기
model.load_state_dict(torch.load('model.h5'))
model.eval()
20-11. 테스트
from PIL import Image
# validation의 이미지 오픈
img1 = Image.open('/content/validation/Bulbasaur/0.jpg')
img2 = Image.open('/content/validation/Squirtle/0.jpg')
fig, axes = plt.subplots(1,2,figsize=(12,6))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()
예시로 선정한 Bulbasaur와 Squirtle의 이미지

img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
# 위에서 resize한 224*224와 tensor형태로 validation을 설정한 부분
print(img1_input.shape)
print(img2_input.shape)
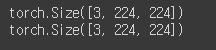
test_batch = torch.stack([img1_input, img2_input]) # stack(): 붙여주는 함수
test_batch = test_batch.to(device)
test_batch.shape # img 2개가 붙어 [2,3,224,224]로 변경됨.

# 예측
y_pred = model(test_batch)
y_pred

y_prob = nn.Softmax(1)(y_pred)
y_prob

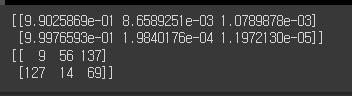
probs, indices = torch.topk(y_prob, k=3, axis=-1) # (2,3,224,224)에서 axis=-1은 224
# k=3은 가장 높은것에서부터 3개만 꼽는다는 의미. # probs=확률값, indices=인덱스값
probs = probs.cpu().data.numpy()
indices = indices.cpu().data.numpy()
print(probs)
print(indices)
# 화면 띄우기
fig, axes = plt.subplots(1,2,figsize=(12,6))
axes[0].set_title('{:.2f}% {},{:.2f}% {},{:.2f}% {}'.format(
probs[0,0]*100, image_datasets['validation'].classes[indices[0,0]], # 1번일 확률
probs[0,1]*100, image_datasets['validation'].classes[indices[0,1]], # 2번일 확률
probs[0,2]*100, image_datasets['validation'].classes[indices[0,2]] # 3번일 확률
))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title('{:.2f}% {},{:.2f}% {},{:.2f}% {}'.format(
probs[1,0]*100, image_datasets['validation'].classes[indices[1,0]], # 1번일 확률
probs[1,1]*100, image_datasets['validation'].classes[indices[1,1]], # 2번일 확률
probs[1,2]*100, image_datasets['validation'].classes[indices[1,2]] # 3번일 확률
))
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()
# 정상적으로 99.03%의 Bulbasaur과 99.98%의 Squirtle을 찾은 모습




