
19. 전이학습
19-1. 에일리언vs프레데터 데이터셋
"에일리언 대 프레데터 (Alien vs. Predator)" 데이터셋: 컴퓨터 비전 분야에서 사용되는 이미지 분류 문제에 대한 Kaggle의 데이터셋으로, 이 데이터셋은 에일리언(Alien)과 프레데터(Predator)라는 두 가지 클래스로 구성된 이미지를 포함하고 있음. 다양한 크기와 배경에서 촬영된 에일리언과 프레데터로 분류된 500장의 훈련 이미지 + 200장의 테스트 이미지가 있으며, 이 데이터셋은 컴퓨터 비전 모델을 학습시켜 에일리언과 프레데터를 정확하게 분류하는 분류기를 구축하는 데 사용됨. |
공식 웹사이트: https://www.kaggle.com/datasets/pmigdal/alien-vs-predator-images
Alien vs. Predator images
Small image classification - for transfer learning
www.kaggle.com
Kaggle에서 해당 데이터셋을 정상적으로 이용하기 위해서는 다운로드 이전에 토큰발행 과정이 필요함.
1. 케글 로그인
2. 계정의 Settings 클릭
3. API항목의 Create New Tokens 클릭
4. json파일 다운로드 후 오픈
→ json파일 내 username과 key가 위치한 dictionary를 이용.
import os
# kaggle의 username을 입력
os.environ['KAGGLE_USERNAME'] = 'yunjaecho1'
# kaggle의 key를 입력 (token값)
os.environ['KAGGLE_KEY'] = '8f9e71f399390930859cd156dafb12c1'
# 이후, 데이터셋 다운로드 시 정식적인 이용에 대한 접근을 알림.
# 위의 입력한 부분은 본인이 다운로드 받은 json파일의 것을 입력해야 함.
# 데이터셋의 다운로드
!kaggle datasets download -d pmigdal/alien-vs-predator-images
# 압축해제
!unzip -q alien-vs-predator-images.zip
# 실행 시 파일목록에 다운로드 된 것을 확인할 수 있음.
# 위의 -d 이후 부분은 본인이 사용할 데이터셋 주소의 뒷부분을 입력해야 함.
# 필요한 모듈의 import
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
# gpu 사용
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)19-2. 이미지 증강 (Image Augmentation)
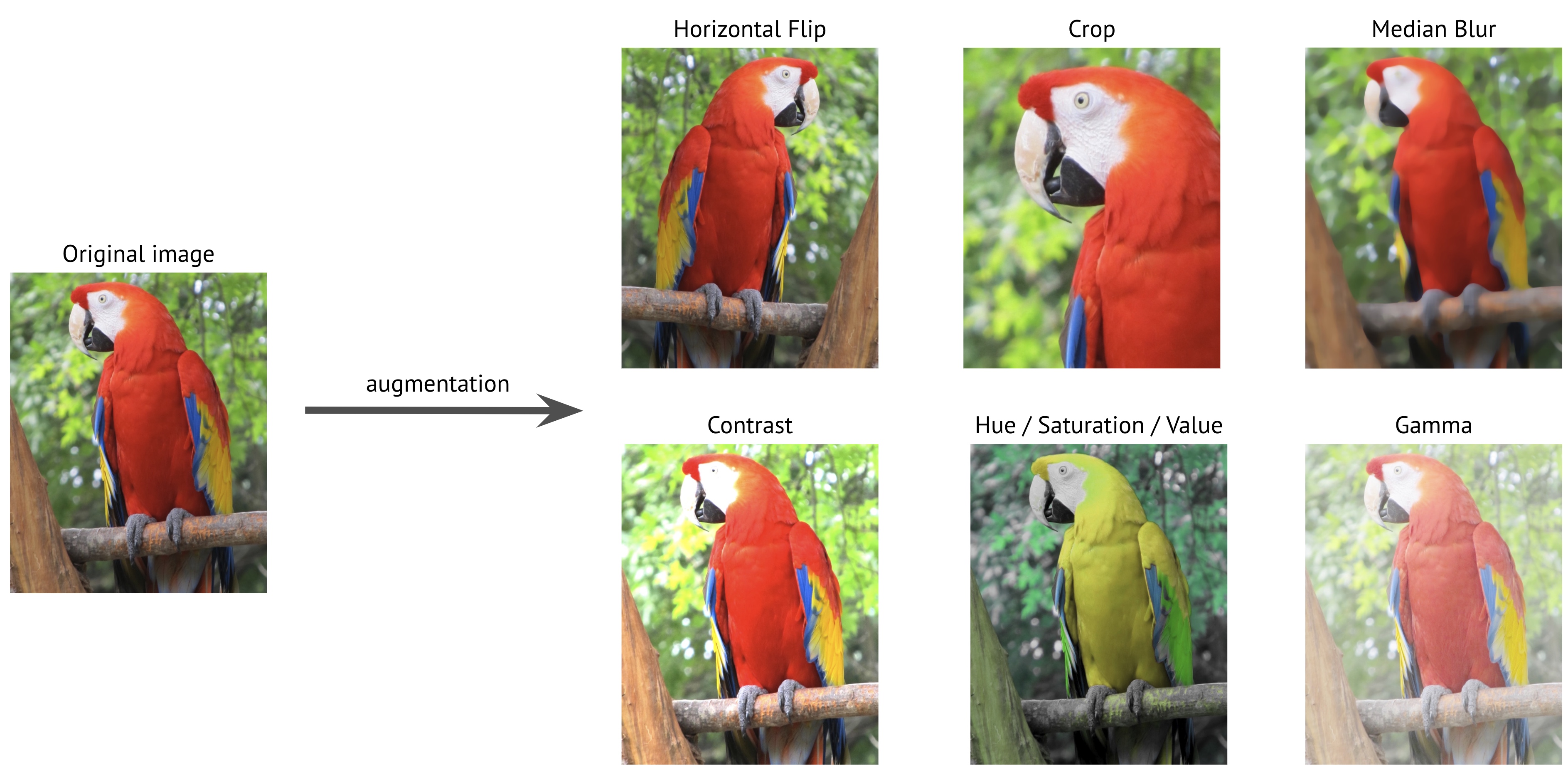
컴퓨터 비전 및 이미지 처리 작업에서 기존의 이미지 데이터를 변형하여 데이터셋을 확장하는 일련의 기법.
→ 모델의 일반화 능력을 향상시키고 과적합을 줄일 수 있음.
한마디로, 주어진 이미지에 대해 다양한 변환을 적용하여 '새로운 이미지를 생성하는 것'임.
이러한 변환에는 회전, 크기조정, 이동, 반전, 밝기/채도/색조 조정 등이 포함됨.
사용 효과:
1) 데이터 다양성 확보:
이미지 데이터셋의 다양성을 증가시켜 모델이 다양한 조건에서 더 강건하게 작동할 수 있도록 도움.
2) 과적합 방지:
모델이 보다 일반적인 특징을 학습하게 되어 훈련 데이터에 과적합되는 것을 방지함.
3) 데이터 부족 상황에서의 성능 향상:
소량의 실제 데이터에서 데이터의 양을 증가시킬 수 있으며, 이는 모델의 성능을 향상시킬 수 있음.
이미지 증강은 컴퓨터 비전 작업, 객체 감지(Object Detection), 이미지 분류(Image Classification),
이미지 분할(Image Segmentation) 등 다양한 작업에 적용될 수 있음.
이미지 증강 관련 pytorch 공식문서: https://pytorch.org/vision/master/transforms.html
Transforming and augmenting images — Torchvision main documentation
Shortcuts
pytorch.org
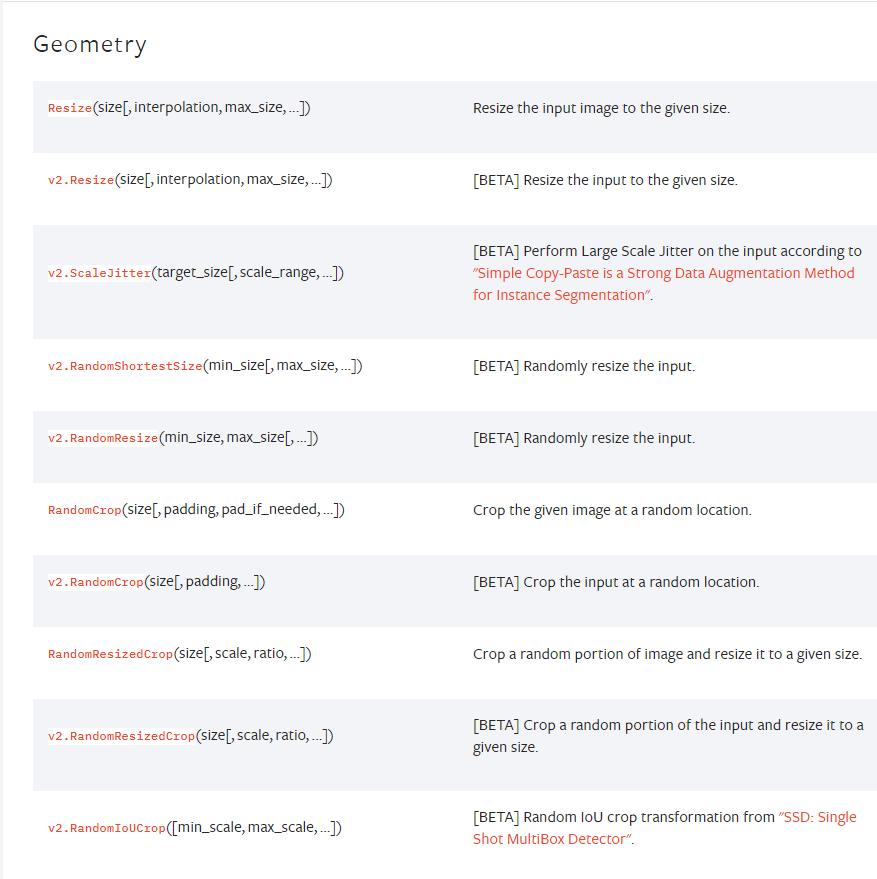
▲ 위 내용과 같이 주된 증강의 방법은 Resize(사이즈 변환)이다.
# torchvision.transforms 모듈을 사용하여 이미지 증강을 구현하는 예시
data_transforms = {
# 학습군. 다양한 조작이 필요 # 대괄호 사용: 복수의 data 사용 예정
'train': transforms.Compose([ # Compose(): 복수의 함수를 일시에 적용가능.
transforms.Resize((224, 224)), # Resize(): 사이즈 변경
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)), # shear: 10가지를 선택 # scale:0.8~1.2의 범위
transforms.RandomHorizontalFlip(), # RandomHorizontalFlip(): 좌우반전
transforms.ToTensor() # ToTensor(): 이미지를 tensor형으로 변환
]),
# 비교군. 학습군과 size와 tensor형을 동일하게 맞춤
'validation': transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor()
])
}
이미지를 Tensor형태로 변환하는 이유: PyTorch 모델은 일반적으로 Tensor를 입력으로 받기 때문에 이러한 변환 과정이 필요 |
# target을 floatTensor로 변경하는 함수 생성
def target_transforms(target):
return torch.FloatTensor([target])
PyTorch에서 floatTensor를 주로 사용하는 이유: floatTensor는 부동소수점 데이터를 저장하기 위해 주로 사용되는데, 딥러닝 모델의 가중치(weight)나 입력 데이터가 일반적으로 floatTensor로 표현되기 때문. |
# 데이터 폴더에서 이미지 데이터셋을 생성하고, DataLoader를 사용하여 데이터를 미니배치 단위로 로드하는 예시
image_datasets = {
# ImageFoler(): 이미지 데이터 폴더에서 데이터셋을 생성
'train': datasets.ImageFolder('data/train', data_transforms['train'], target_transform=target_transforms),
'validation': datasets.ImageFolder('data/validation', data_transforms['validation'], target_transform=target_transforms)
}
dataloaders = {
'train': DataLoader( # 데이터셋을 미니배치 단위로 로드
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}
# image_datasets의 'train'과 'validation'에 포함된 데이터의 개수를 출력
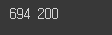
# 학습 데이터와 검증 데이터의 크기를 확인
print(len(image_datasets['train']), len(image_datasets['validation']))
# 미니배치의 이미지와 레이블이 있는 서브플롯 그리드가 생성되며, 각 이미지는 해당 레이블과 함께 시각화
imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4, 8, figsize=(20,10)) # 4행 8열
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.permute(1,2,0)) # permute(): index로 순서를 변경하는 함수.
# permute(1,2,0): 첫 번째 차원이 가로, 두 번째 차원이 세로, 세 번째 차원이 채널을 나타내도록 변경
ax.set_title(label.item())
ax.axis('off')

19-3. 전이학습(Transfer Learning)
'미리 학습을 시켜둔 것을 가져다 쓰는 것'
기계 학습의 한 분야로, 한 도메인에서 학습한 지식을 다른 도메인에 적용하는 방법.
이는 기존에 학습한 모델을 새로운 작업에 재사용하여 학습을 더 빠르고 효율적으로 진행할 수 있게 해줌.
하나의 작업을 위해 훈련된 모델을 유사 작업 수행모델의 시작점으로 활용하는 딥러닝 접근법.
신경망은 처음부터 새로 학습하는 것 보다 전이학습을 통해 업데이트하고 재학습하는 편이 더 빠르고 간편함.
전이학습은 여러 응용 분야 중에서도 특히 검색, 검출, 영상인식, 음성인식 등의 분야에서 많이 사용됨.

고려점:
1) 모델의 크기
전이학습은 사전에 학습된 모델의 크기를 고려해야 함.
큰 모델은 더 많은 파라미터와 계산 리소스를 필요로 하며, 작은 모델보다 더 복잡한 패턴을 학습할 수 있음.
그러나 큰 모델은 저장 공간과 메모리 요구량이 많아질 수 있음.
따라서 사용 가능한 컴퓨팅 리소스와 제약사항에 따라 적절한 모델 크기를 선택해야 함.
2) 정확도
전이학습은 사전에 학습된 모델의 지식을 새로운 작업에 전달하여 성능을 향상시키는 것을 목표로 하나
일부 작업에서는 전이학습이 유용하지 않을 수도 있기 때문에 전이학습이 성능 향상을 보장하는 것은 아님.
정확도는 전이학습을 적용할 때 고려해야 할 중요한 측정 지표임.
사전에 학습된 모델이 유사한 작업에서 높은 정확도를 달성한 경우에는 전이학습이 유용할 가능성이 높음.
3) 예측 속도
전이학습을 사용할 때 예측 속도 역시 고려해야 하는 요소임.
일부 사전에 학습된 모델은 매우 크고 복잡하여 예측 속도가 느릴 수 있음.
실시간 응용 프로그램이나 시간 제약이 있는 작업의 경우, 예측 속도가 중요한 요소가 될 수 있으므로
모델의 예측 속도를 고려해야 함.

▲ 모델의 종류
(교육 간 사용할 모델: ResNet-50)
19-4. ResNet50 모델
pytorch에서 제공하는 사전학습 모델 리스트: https://pytorch.org/vision/stable/models.html
Models and pre-trained weights — Torchvision 0.15 documentation
Shortcuts
pytorch.org
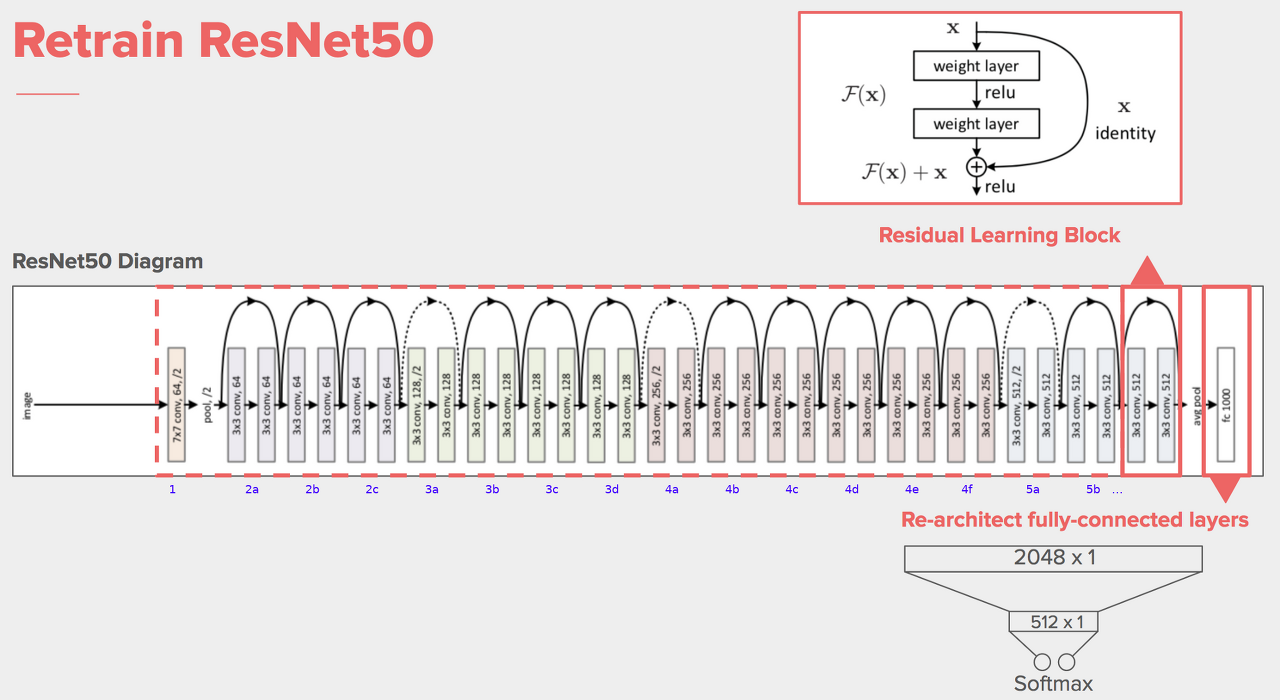
19-4-1. 이미지넷(ImageNet)
컴퓨터 비전 분야에서 널리 사용되는 대규모 이미지 데이터셋.
이 데이터셋은 1,000개 이상의 카테고리에 속하는 약 1,400만 장의 이미지로 구성되어 있음.
각 이미지는 사람들이 레이블을 지정한 약 1,000개의 다양한 객체 및 사물을 포함하고 있음.

# resnet50 모델 사용 # 가중치로 IMAGENET1K_V1을 미리 학습한 후 GPU로 보내겠다는 의미.
model = models.resnet50(weights='IMAGENET1K_V1').to(device)
# model = models.resnet50(pretrained=True).to(device)
print(model)
# (pretrained=True): train을 미리 하겠다.(전이학습을 하겠다)는 의미로 동일하게 사용되므로 숙지. False는 반대를 의미.
19-4-2. Freeze Layers
Freeze Layers란, 딥러닝 모델에서 일부 층(layer)의 가중치를 동결하는 것을 의미함.
동결된 층의 가중치는 학습 과정에서 업데이트되지 않으며, 해당 층의 파라미터는 고정됨.
일반적으로, 사전에 학습된 모델을 가져와서 새로운 작업에 적용할 때 Freeze Layers를 사용함.
예를 들어, 전이학습(Transfer Learning)을 수행하는 경우,
모델의 일부 층은 사전에 다른 데이터셋에서 학습된 특징을 캡처하는 역할을 함.
이러한 층은 이미지넷(ImageNet)과 같은 대규모 데이터셋에서 학습된 경우가 많음.
따라서 이러한 층의 가중치를 동결하여 새로운 작업에서 추가적인 학습을 방지하고,
이전에 학습한 특징 추출 능력을 유지함.
Freeze Layers는 학습 가능한 파라미터의 수를 줄이고, 모델의 학습 속도를 빠르게 하며, 과적합을 방지함.
그러나 Freeze Layers를 적절히 선택해야 하며, 동결된 층의 특징이 새로운 작업과 일치하는지 확인해야 함.
for param in model.parameters():
param.requires_grad = False # 가져온 파라미터를 업데이트 하지 않음.
# PyTorch를 사용하여 모델의 fully connected layer를 변경하는 부분.
# 모델의 마지막 부분에 있는 fully connected layer를 수정하여 원하는 구조로 변경.
model.fc = nn.Sequential(
nn.Linear(2048, 128), # 입력 크기가 2048이고 출력 크기가 128인 fully connected layer를 정의
# ReLU(Rectified Linear Unit) 활성화 함수를 적용하는 레이어.
# ReLU는 입력값이 0보다 작을 경우 0으로 출력하고, 0보다 큰 경우 입력값을 그대로 출력.
# 이를 통해 비선형성을 도입하고 신경망의 표현력을 향상함.
nn.ReLU(),
nn.Linear(128,1), # 두 번째 레이어로, 입력 크기가 128이고 출력 크기가 1인 fully connected layer를 정의.
# Sigmoid 활성화 함수를 적용하는 레이어.
# Sigmoid 함수는 입력값을 0과 1 사이의 값으로 압축하여 이진 분류 문제에서 확률값을 제공함.
# 출력값을 0과 1 사이로 제한하여 이진 분류 결과를 나타냄.
nn.Sigmoid()
).to(device)
print(model)
# 학습 # fc부분만 학습하므로 속도가 빠름.
# 주어진 에폭 수(epochs)만큼 반복하면서 훈련과 검증 과정을 수행.
# Adam 옵티마이저를 생성하여 모델의 FC Layer에 대한 파라미터들을 최적화함.
# 학습률(learning rate)은 0.001로 설정.
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
# 전체 데이터셋을 몇 번 반복하여 훈련할지를 나타내는 변수를 설정.
epochs = 10 # 여기서는 10번의 에폭으로 설정됨.
for epoch in range(epochs): # 주어진 에폭 수만큼 반복.
for phase in ['train', 'validation']: # phase 변수는 'train'(훈련)과 'validation'(검증)값을 가짐.
if phase == 'train':
model.train() # 훈련 단계일 때는 모델을 훈련 상태로 설정. (model.train())
else:
model.eval() # 검증 단계일 때는 모델을 평가 상태로 설정. (model.eval())
# 메모리에서 학습된 데이터의 삭제 과정
sum_losses = 0 # 손실(loss)의 합을 초기화.
sum_accs = 0 # 정확도(accuracy)의 합을 초기화.
for x_batch, y_batch in dataloaders[phase]: # 해당 단계(phase)의 데이터로더에서 미니 배치를 가져옴.
x_batch = x_batch.to(device) # 입력 데이터를 GPU로 이동.
y_batch = y_batch.to(device) # 타겟 레이블을 GPU로 이동.
y_pred = model(x_batch) # 모델에 입력 데이터를 전달하여 예측값을 계산.
# 이진 분류 작업에서 사용되는 BCELoss(binary cross-entropy loss)로 손실값을 계산.
loss = nn.BCELoss()(y_pred, y_batch)
if phase == 'train': # 훈련 단계인 경우,
optimizer.zero_grad() # 기울기를 초기화.
loss.backward() # 역전파를 통해 기울기를 계산.
optimizer.step() # 옵티마이저를 사용하여 가중치를 업데이트.
sum_losses = sum_losses + loss.item() # 손실의 합을 누적.
y_bool = (y_pred>=0.5).float() # 예측값을 임계값 0.5를 기준으로 0과 1로 이진화.
acc = (y_batch ==y_bool).float().sum() / len(y_batch) * 100 # 정확도를 계산.
sum_accs = sum_accs + acc.item() # 정확도의 합을 누적.
avg_loss = sum_losses / len(dataloaders[phase]) # 손실의 평균을 계산.
avg_acc = sum_accs / len(dataloaders[phase]) # 정확도의 평균을 계산.
# 현재 단계(phase)에서의 에폭, 손실, 정확도를 출력.
print(f'{phase:10s}:Epoch{epoch+1:4d}/{epochs}, Loss:{avg_loss:.4f}, Accuracy:{avg_acc:.2f}%')
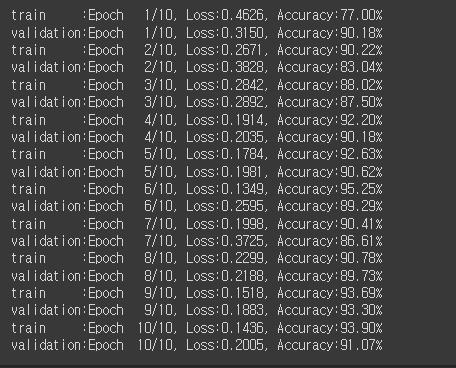
# 학습된 모델의 배포 목적의 저장.
torch.save(model.state_dict(), 'model.h5') # model.h5에서 model은 임의의 제목.
# 저장된 파일을 로드.
# ResNet-50 아키텍처의 아직 가중치(weight)가 초기화되지 않은 상태인 빈 모델이 생성됨.
model = models.resnet50().to(device)
'빈 껍데기 모델'을 가져오는 이유: 1) 사전 학습된 가중치를 사용할 수 있도록 하기 위해 선행작업으로 초기화된 가중치를 가져와야 함. 2) 모델의 아키텍처와 레이어 구조를 미리 정의하여 편리하게 사용할 수 있음. 3) 모델의 파라미터 개수, 입력 및 출력 크기 등을 확인할 수 있음. |
# 로드 시 수정작업 (위와 동일)
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(),
nn.Linear(128,1),
nn.Sigmoid()
).to(device)
# 재학습 # 빈 모델이므로 정확도가 낮음.
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.BCELoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss.item()
y_bool = (y_pred>=0.5).float()
acc = (y_batch ==y_bool).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc.item()
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}:Epoch{epoch+1:4d}/{epochs}, Loss:{avg_loss:.4f}, Accuracy:{avg_acc:.2f}%')
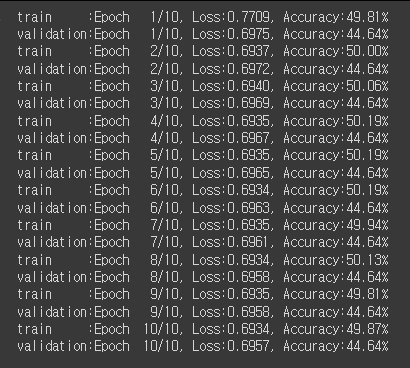
# 빈 모델에 가중치가 설정된 본 모델 로드
model.load_state_dict(torch.load('model.h5'))
model.eval()
# 재학습 # 빈 모델에 비해 정확도가 높아진 것을 확인할 수 있음.
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.BCELoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss.item()
y_bool = (y_pred>=0.5).float()
acc = (y_batch ==y_bool).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc.item()
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}:Epoch{epoch+1:4d}/{epochs}, Loss:{avg_loss:.4f}, Accuracy:{avg_acc:.2f}%')
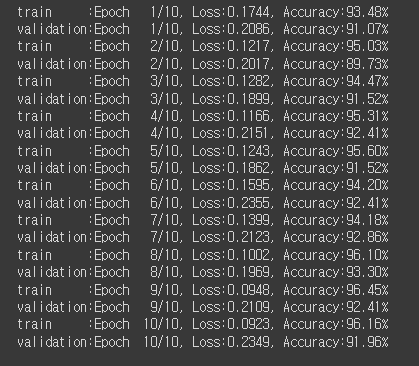
# 테스트
# 모델을 사용하여 주어진 두 개의 이미지에 대한 예측을 수행하고, 예측 결과와 정확도를 출력 기능을 구현.
from PIL import Image
# validation의 이미지 오픈
img1 = Image.open('data/validation/alien/32.jpg')
img2 = Image.open('data/validation/predator/45.jpg')
fig, axes = plt.subplots(1,2,figsize=(12,6))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()

img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
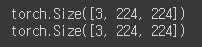
# 위에서 resize한 224*224와 tensor형태로 validation을 설정한 부분
print(img1_input.shape)
print(img2_input.shape)
test_batch = torch.stack([img1_input, img2_input]) # stack(): 붙여주는 함수
test_batch = test_batch.to(device)
test_batch.shape # img 2개가 붙어 [2,3,224,224]로 변경됨.

# 예측
y_pred = model(test_batch)
y_pred

# 이미지 표시
fig, axes = plt.subplots(1,2,figsize=(12,6))
axes[0].set_title(f'{(1-y_pred[0,0])*100:.2f}% Alien, {y_pred[0,0]*100:.2f}% Predator')
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title(f'{(1-y_pred[1,0])*100:.2f}% Alien, {y_pred[1,0]*100:.2f}% Predator')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()




