15. 데이터 로더
15-1. 손글씨 인식모델 만들기
# 필요한 라이브러리 및 모듈 불러오기
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets # torchvision에서 제공하는 다양한 데이터셋을 쉽게 다운로드하고 사용
import torchvision.transforms as transforms # 이미지에 대한 다양한 전처리 작업을 수행
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits # 교육간 이용할 손글씨 데이터셋
# GPU 장치 사용 예정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)

# 손글씨 데이터셋을 변수로 선언
digits = load_digits()
# x_data에는 이미지 데이터가, y_data에는 레이블 데이터가 있음.
x_data = digits['data']
y_data = digits['target']
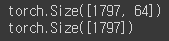
# 데이터셋에는 총 1797개의 이미지가 있으며, 각 이미지는 64개의 픽셀 값을 가지고 있음.
print(x_data.shape)
print(y_data.shape)

# matplotlib 라이브러리를 사용하여 숫자 이미지 데이터셋을 시각화
import matplotlib.pyplot as plt
# 2행 5열의 서브플롯 그리드를 생성하고, 전체 그림의 크기를 (14, 8)로 설정
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14,8))
for i, ax in enumerate(axes.flatten()): # axes 배열을 1차원으로 펼친 후 for문 순회
ax.imshow(x_data[i].reshape((8,8)), cmap='gray') # 이미지 입력
ax.set_title(y_data[i]) # 제목 입력
ax.axis('off') # 격자를 off

# 둘 다 실수형 탠서로 변환
x_data = torch.FloatTensor(x_data)
y_data = torch.LongTensor(y_data) # y_data는 인덱스 탠서여야 하기 때문에 Long(정수형)Tensor를 사용.
print(x_data.shape)
print(y_data.shape)
# 레이블 데이터를 원-핫 인코딩 형식으로 변환
y_one_hot = nn.functional.one_hot(y_data, num_classes=10).float() # 클래스의 개수를 10으로 설정
y_one_hot[:10] # 원핫인코딩 결과는 Tensor 형식으로 저장됨
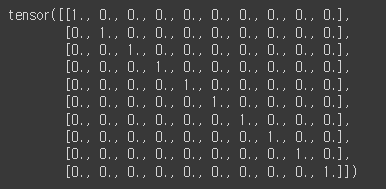
# train데이터와 test데이터의 분할
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_data, y_one_hot, test_size=0.2, random_state=10)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)

15-2. 데이터 로더
데이터 로더는 주로 모델 학습에 사용되는 train 데이터셋과 test 데이터셋을 로드하는 데에 활용됨.
데이터 로더는 데이터를 일정한 크기의 미니배치(mini-batch)로 분할하여 모델에 공급하고,
학습 반복(iteration)마다 다음 미니배치를 로드하여 학습 과정을 지속함.
요약하자면, 데이터 로더는 데이터에 전처리 작업을 한 후 활용할 수 있는 형식으로 데이터를 로드하는 기능을 제공하는 소프트웨어의 역할을 함.
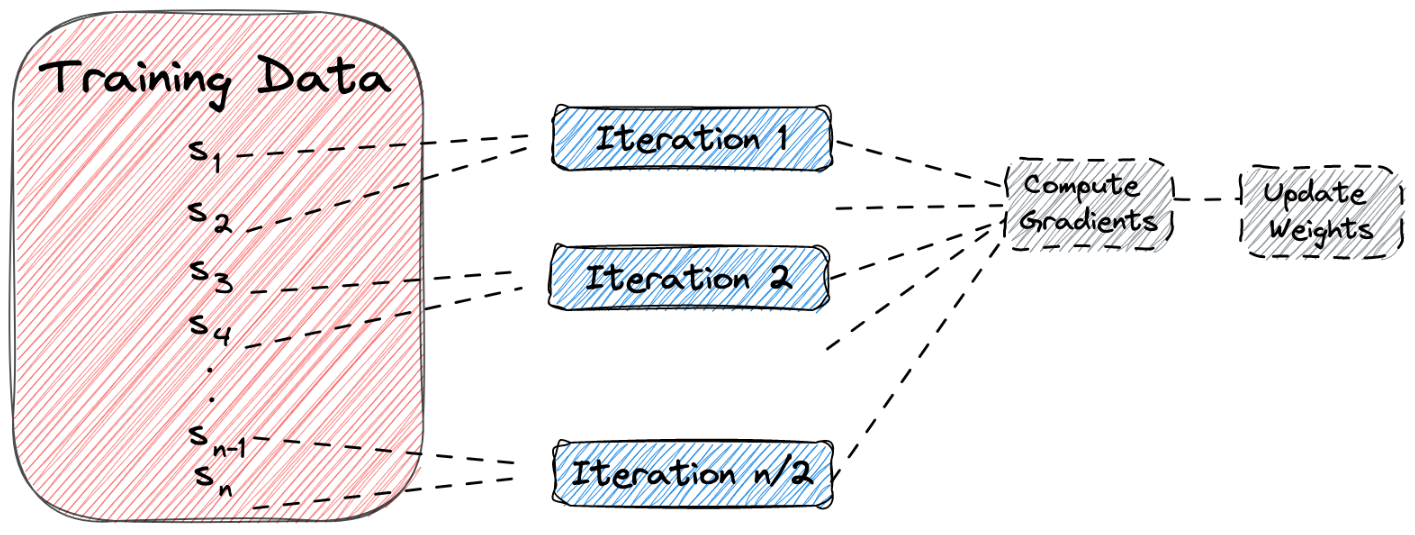
1) DataLoader 초기화:
DataLoader는 PyTorch의 데이터 로더 유틸리티
# 여기서는 x_train과 y_train 데이터를 묶어서 dataset으로 사용함.
loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train)),
batch_size = 64, # 한 번에 로드할 데이터의 배치 크기(여기서는 64개의 데이터)를 지정함.
shuffle = True
)
2) 데이터 로드:
# DataLoader를 iterator로 변환하여 첫 번째 미니배치를 가져옴.
imgs, labels = next(iter(loader)) # iter(): 더 이상 iterator가 없을 때 까지 순서대로 객체를 만들어주는 함수.
# next() 함수를 사용하여 이터레이터에서 다음 값을 추출함.
# 따라서 imgs는 이미지 데이터를, labels는 해당 이미지의 라벨을 나타내는 텐서를 가져옴.
3) 이미지 시각화:
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14,14)) # 8x8의 서브플롯을 생성
for ax, img, label in zip(axes.flatten(), imgs, labels): # 1차원 배열로 평면화
ax.imshow(img.reshape((8,8)), cmap='gray') # 1차원 이미지 데이터를 8x8 크기의 2차원 배열로 변환
ax.set_title(str(torch.argmax(label))) # 라벨 텐서에서 가장 큰 값을 가지는 인덱스를 추출
ax.axis('off') # 서브플롯의 축을 제거함. 이를 통해 격자 표시를 없앰.


<단순한 선형 신경망 모델을 정의하고 학습하는 과정>
1) 모델 정의:
model = nn.Sequential( # 순차적인 모델을 정의하는 클래스. 여기서는 하나의 선형 레이어를 가진 모델.
nn.Linear(64,10) # 입력 크기가 64이고 출력 크기가 10인 선형 레이어.
)
2) 옵티마이저 설정:
# Adam 최적화 알고리즘을 사용하는 옵티마이저를 정의.
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 모델의 학습 가능한 매개변수들을 반환.
# 학습률(learning rate)로, 옵티마이저가 매개변수를 업데이트할 때 사용되는 스케일링 요소.
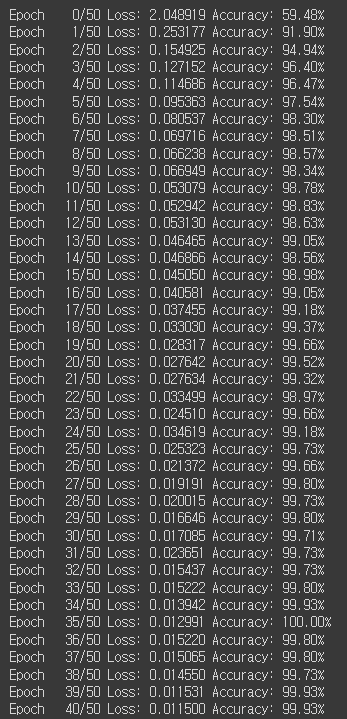
3) 학습 반복:
epochs = 50 # 전체 학습 반복 횟수
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in loader: # DataLoader에서 미니배치를 가져오는 루프
y_pred = model(x_batch) # 모델에 입력 데이터 x_batch를 전달하여 예측값 y_pred를 얻음.
# CrossEntropyLoss함수를 사용하여 예측값과 실제 라벨 y_batch 간의 손실을 계산
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
optimizer.zero_grad() # 옵티마이저의 변화도를 0으로 초기화.
loss.backward() # 손실에 대한 변화도(gradient)를 계산.
optimizer.step() # 옵티마이저를 사용하여 매개변수를 업데이트.
sum_losses = sum_losses + loss # 학습 반복마다 손실 값을 누적하여 기록.
<손실(loss)과 정확도(accuracy)를 계산하고 출력하는 과정>
1) 소프트맥스(Softmax) 함수와 예측값 인덱스 계산:
y_prob = nn.Softmax(1)(y_pred)
# 각 행(row)에서 가장 큰 값에 해당하는 인덱스를 추출함. 이는 예측값의 인덱스를 나타냄.
y_pred_index = torch.argmax(y_prob, axis=1)
# 실제 라벨(y_batch)에서 가장 큰 값에 해당하는 인덱스를 추출.
y_batch_index = torch.argmax(y_batch, axis=1)
2) 정확도 계산:
# 예측값 인덱스와 실제 라벨 인덱스가 일치하는지를 비교하여 각 샘플에 대한 예측 정확도를 구함.
# 이후 일치하는 예측값의 개수를 계산하여 정확도를 백분율로 계산함.
acc = (y_batch_index == y_pred_index).float().sum() / len(y_batch) * 100
3) 손실과 정확도 누적:
sum_accs = sum_accs + acc # sum_accs 변수에 각 미니배치에서 계산된 정확도를 누적.
4) 에포크 종료 후 결과 출력:
# 코드의 2번째 for문 바깥에 작성
avg_loss = sum_losses / len(loader) # 전체 에포크에서 계산된 손실의 평균값.
avg_acc = sum_accs / len(loader) # 전체 에포크에서 계산된 정확도의 평균값.
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
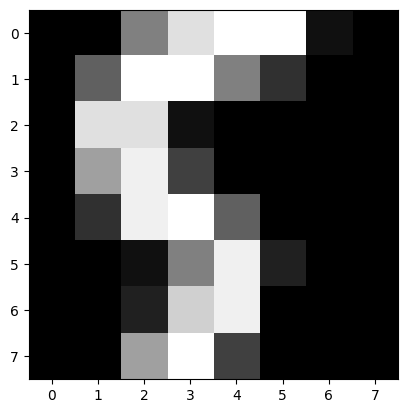
# test 데이터셋의 0번 index를 입력하여 시각화하여 출력했을 때의 경우
plt.imshow(x_test[0].reshape((8,8)),cmap='gray')
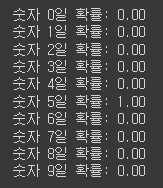
# 예측값 계산
y_pred = model(x_test)
y_pred[0]

# 예측값 y_pred에 소프트맥스(Softmax) 함수를 적용하여 클래스에 대한 확률 값을 계산하고,
#그 중 첫 번째 예측값의 확률 분포를 출력
y_prob = nn.Softmax(1)(y_pred)
y_prob[0]

for i in range(10):
print(f'숫자 {i}일 확률: {y_prob[0][i]:.2f}')
# 배치 단위 정확도 저장
y_pred_index = torch.argmax(y_prob, axis=1)
y_test_index = torch.argmax(y_test, axis=1) # 제일 높은 index 출력
accuracy = (y_test_index == y_pred_index).float().sum() / len(y_test) * 100
print(f'테스트 정확도는 {accuracy:.2f}% 입니다.')

16. 딥러닝(Deep Learning)
기계학습 기술의 종류 중 하나인 인공신경망의 방법론 중 하나임.
다층 구조의 은닉층으로 네트워크를 연결한 기법을 뜻하며 현대 인공지능 기술의 핵심이자
앞으로 더더욱 각광받게 될 기술.
16-1. 퍼셉트론(Perceptron)
이진 분류를 위해 개발된 인공신경망 모델임.
퍼셉트론은 입력 신호와 가중치의 선형 결합을 통해 계산된 값에 활성화 함수를 적용하여 출력을 생성함.
여러 개의 퍼셉트론을 결합하여 복잡한 패턴을 학습하고, 다양한 작업을 수행할 수 있는 인공신경망을
구성할 수 있다.
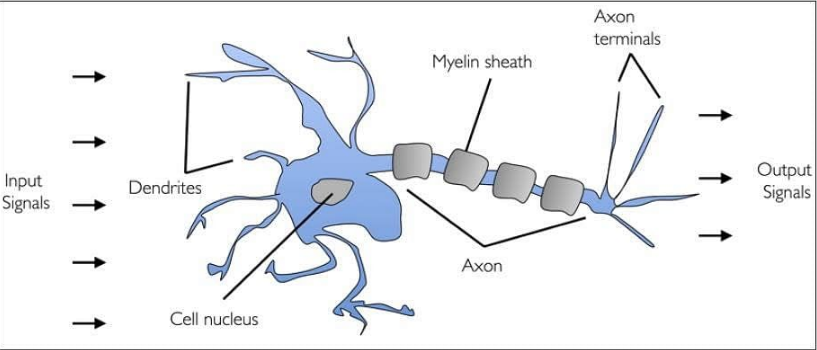
16-1-1. 생물학적 뉴런
인간의 뇌는 수십억개의 뉴런을 가지고 있음.
뉴런은 화학적, 전기적 신호를 처리하고 전달하는 연결된 뇌신경 세포를 의미함.
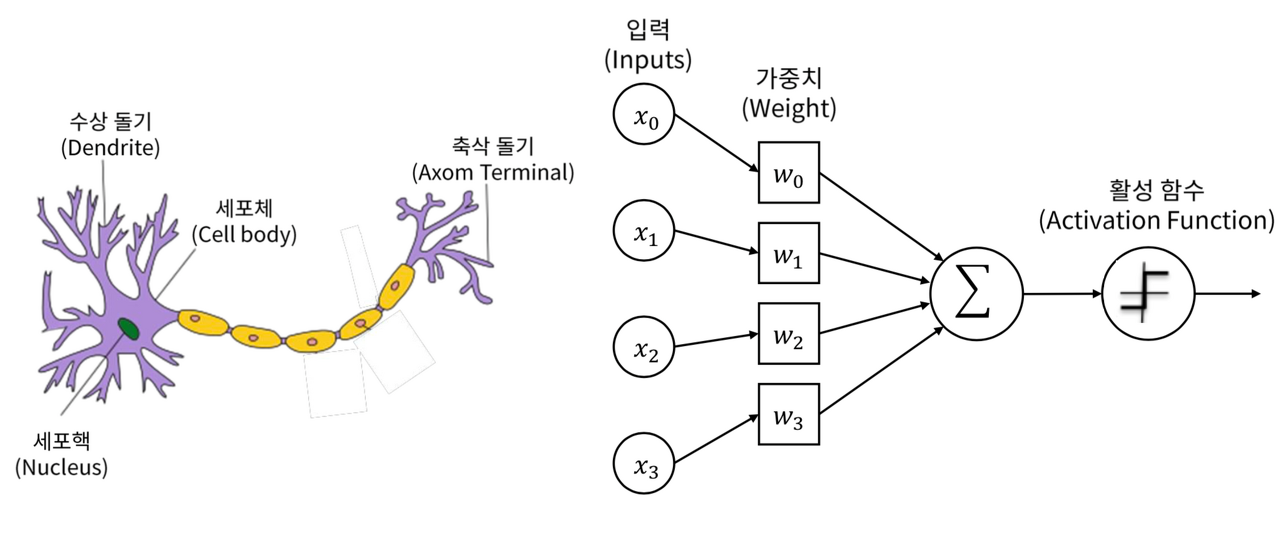
16-1-2. 인공 뉴런
인공뉴런은 인공신경망(artificial neural network) 모델의 기본 구성 요소임.
인공뉴런은 생물학적 뉴런에서 영감을 받아 만들어진 수학적 모델로, 정보 처리와 학습을 담당함.
인공뉴런은 입력 신호를 받아 가중치와 활성화 함수를 적용한 후 출력을 생성함.
입력은 다수의 특성(feature) 또는 이전 뉴런의 출력으로부터 전달되며, 가중치는 각 입력 신호의 중요도를
조절하는 역할을 함. 활성화 함수는 가중합을 입력으로 받아 출력을 결정하는 비선형 함수로,
주로 비선형성을 도입하여 모델의 표현력을 높임.
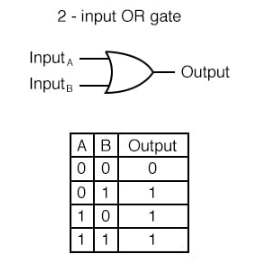
16-1-3. OR 게이트
OR 게이트는 퍼셉트론의 예시로, 입력값에 따라 출력을 결정하는 논리 연산을 수행하며
두 개의 이진 입력(0 또는 1)을 받아 하나의 출력을 생성함.
입력 값 중 하나라도 1이면 출력은 1이고, 입력 값이 모두 0인 경우에만 출력이 0임.
OR 게이트를 구현한 퍼셉트론은 입력과 가중치의 선형 결합을 계산한 후,
계산 결과에 임계값(threshold)을 적용하는 활성화 함수로서, 보통 계단 함수(Step function)를 사용함.
OR 게이트는 단층 퍼셉트론으로 구현할 수 있으며, 이를 통해 입력 값에 따라 다른 출력을 생성하는 간단한 논리 연산을 수행할 수 있음.
import torch
import torch.nn as nn
import torch.optim as optim
nn.Linear(2,1)은 입력 차원이 2이고 출력 차원이 1인 선형 레이어를 의미하며,
nn.Sigmoid()는 활성화 함수로 시그모이드 함수를 적용하는 레이어임.

X = torch.FloatTensor([[0,0],[0,1],[1,0],[1,1]])
y = torch.FloatTensor([[0],[1],[1],[1]])
model = nn.Sequential( # model: 단층 퍼셉트론 모델을 정의
nn.Linear(2,1),
nn.Sigmoid() # softmax 함수가 아니므로 sigmoid함수가 별도로 필요
)
print(model)

optimizer = optim.SGD(model.parameters(), lr=1)
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(X)
loss = nn.BCELoss()(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
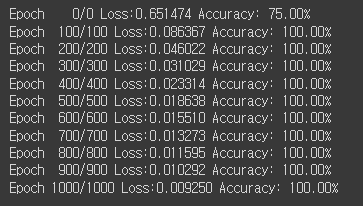
if epoch % 100 == 0:
y_bool = (y_pred >= 0.5).float()
accuracy = (y==y_bool).float().sum() / len(y) * 100
print(f'Epoch {epoch:4d}/{epoch} Loss:{loss:.6f} Accuracy: {accuracy:.2f}%')
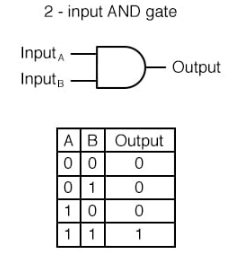
16-1-4. AND 게이트
AND 게이트는 퍼셉트론의 예시로, 입력값에 따라 출력을 결정하는 논리 연산을 수행하며
두 개의 이진 입력을 받아 하나의 출력을 생성함.
입력 값이 모두 1인 경우에만 출력이 1이고, 입력 값 중 하나라도 0이면 출력은 0임.
AND 게이트를 구현한 퍼셉트론은 OR 게이트와 마찬가지로 입력과 가중치의 선형 결합을 계산한 후,
계산 결과에 계단 함수를 적용하여 출력을 결정함.
AND 게이트는 단층 퍼셉트론으로 구현할 수 있으며, 이를 통해 입력 값에 따라 다른 출력을 생성하는 간단한 논리 연산을 수행할 수 있음.
X = torch.FloatTensor([[0,0],[0,1],[1,0],[1,1]])
y = torch.FloatTensor([[0],[0],[0],[1]])
model = nn.Sequential(
nn.Linear(2,1),
nn.Sigmoid() # softmax 함수가 아니므로 sigmoid함수를 별도로 넣어주어야 함
)
print(model)
optimizer = optim.SGD(model.parameters(), lr=1)
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(X)
loss = nn.BCELoss()(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
y_bool = (y_pred >= 0.5).float()
accuracy = (y==y_bool).float().sum() / len(y) * 100
print(f'Epoch {epoch:4d}/{epoch} Loss:{loss:.6f} Accuracy: {accuracy:.2f}%')

16-2. 역전파(BackPropagation)
손실 함수의 기울기를 이용하여 네트워크의 각 층에서 발생한 오차를 역방향으로 전파하여
각 가중치와 편향을 조정하는 과정.
# 다층 퍼셉트론 모델을 정의. nn.Sequential을 사용하여 각 레이어를 순차적으로 쌓아서 모델을 구성.
model = nn.Sequential(
nn.Linear(2,64), # 64개의 차원생성
nn.Sigmoid(), # sigmoid함수를 이용하여 비선형으로 만듦
nn.Linear(64, 32), # 32개로 차원축소
nn.Sigmoid(),
nn.Linear(32,16), # 16개로 차원축소
nn.Sigmoid(),
nn.Linear(16, 1), # 16개의 차원을 입력받아 1개의 차원을 출력
nn.Sigmoid() # 시그모이드 활성화 함수.
# 비선형성을 추가하여 다층 퍼셉트론이 비선형 관계를 모델링할 수 있도록 함.
)
print(model)

차원을 축소하는 이유: 계산 효율성: 더 낮은 차원의 데이터는 더 적은 계산 비용을 요구함. 특히 대규모 데이터셋의 경우, 차원 축소는 계산과 메모리 요구사항을 줄여줌으로써 모델의 학습과 예측 속도를 향상시킬 수 있음. 과적합 방지: 높은 차원의 데이터는 더 복잡한 모델을 필요로 함. 그러나 너무 많은 차원은 모델이 훈련 데이터에 과적합될 가능성을 증가시킬 수 있음. 차원 축소는 중요한 정보를 유지하면서 노이즈와 불필요한 변동성을 제거함으로써 과적합을 감소시킬 수 있음. 시각화와 해석 가능성: 데이터를 2차원 또는 3차원으로 축소하면 데이터를 시각적으로 표현하고 해석하기 쉬워짐. 이는 데이터의 구조와 패턴을 이해하고 모델의 결과를 시각적으로 확인하는 데 도움이 됨. 데이터 압축: 차원 축소는 데이터를 더 작은 공간에 표현함으로써 데이터 압축을 달성할 수 있음. 이는 데이터 저장 및 전송 비용을 절감할 수 있음. 차원 축소는 주어진 문제와 데이터에 따라 적절히 선택되어야 하며 적절한 차원 축소 기법을 사용하면 효율적인 모델링과 예측 성능 향상을 이끌어낼 수 있음. |
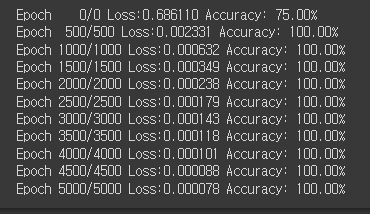
optimizer = optim.SGD(model.parameters(), lr=1)
epochs = 5000
for epoch in range(epochs + 1):
y_pred = model(X)
loss = nn.BCELoss()(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
y_bool = (y_pred >= 0.5).float()
accuracy = (y==y_bool).float().sum() / len(y) * 100
print(f'Epoch {epoch:4d}/{epoch} Loss:{loss:.6f} Accuracy: {accuracy:.2f}%')
17. 활성화 함수 (Activation Function)
인공 신경망에서 입력 신호의 가중치 합을 출력으로 변환하는 함수.
활성화 함수는 비선형성을 추가하여 신경망이 복잡한 함수를 모델링할 수도 있게 함.
또한, 활성화 함수는 신경망의 비선형성과 매개변수의 최적화를 가능하게 하며,
모델의 출력을 제한하는 역할도 수행할 수 있음.
사용 목적: 멀티레이어 퍼셉트론 생성

import numpy as np
import matplotlib.pyplot as plt
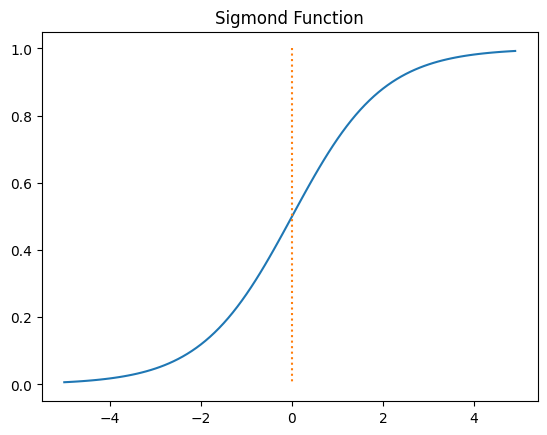
17-1. 시그모이드 함수 (Sigmoid Function)
입력을 0과 1 사이의 값으로 압축시키는 기본적인 활성화 함수.
주로 이진 분류 문제에서 출력 뉴런으로 사용됨.
x = np.arange(-5.0, 5.0, 0.1)
y = 1/(1+np.exp(-x))
plt.plot(x,y)
plt.plot([0,0], [1.0, 0.0], ":") # ":" 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
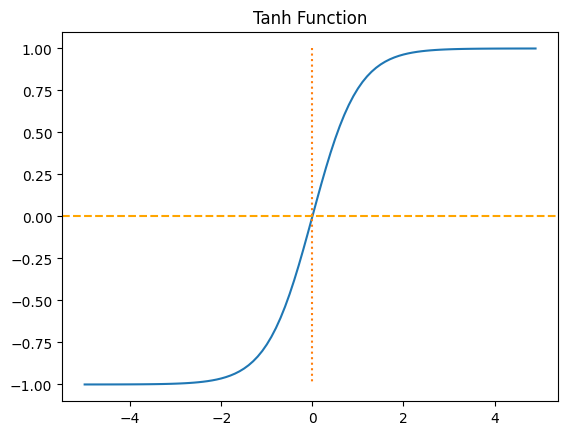
17-2. 하이퍼볼릭 탄젠트 함수 (Hyperbolic Tangent Function)
시그모이드 함수와 유사하게 입력을 -1과 1 사이의 값으로 압축시킴.
주로 다양한 문제에서 사용되며, 입력의 부호와 크기를 모두 유지하는 특성을 가지고 있음.
x = np.arange(-5.0, 5.0, 0.1)
y = np.tanh(x)
plt.plot(x,y)
plt.plot([0,0], [1.0, -1.0], ":")
plt.axhline(y=0, color='orange', linestyle='--')
plt.title('Tanh Function')
plt.show()
17-3. 렐루 함수 (Relu Function)
입력이 0보다 크면 입력을 그대로 출력하고, 0 이하인 경우는 0으로 출력함.
최근에 가장 많이 사용되는 활성화 함수로, 연산이 간단하고 효과적인 기울기 전파를 가능하게 함.
x = np.arange(-5.0, 5.0, 0.1)
y = np.maximum(0,x)
plt.plot(x,y)
plt.plot([0,0], [5.0, 0.0], ":")
plt.title('Relu Function')
plt.show()

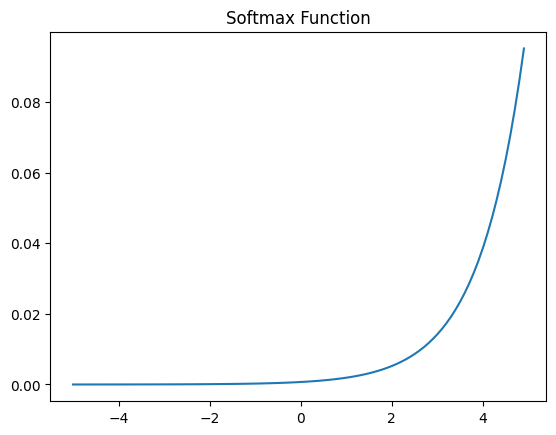
17-4. 소프트맥스 함수 (Softmax Function)
다중 클래스 분류 문제에서 사용되는 활성화 함수로, 출력 뉴런의 값을 확률로 해석할 수 있도록 정규화함.
출력의 합이 1이 되도록 변환하며, 각 클래스에 속할 확률을 제공함.
x = np.arange(-5.0, 5.0, 0.1)
y = np.exp(x) / np.sum(np.exp(x))
plt.plot(x,y)
plt.title('Softmax Function')
plt.show()