
5. 원형 연결리스트(Circular LinkedList)
원형 연결 리스트는 연결 리스트의 한 종류로 마지막 노드가 첫 번째 노드를 가리키며,
첫 번째 노드의 이전 노드는 마지막 노드를 가리킴.
이러한 구조로 인해 리스트의 끝과 시작이 연결되어 있는 원형 모양을 이루게 됨.
원형 연결 리스트의 장점:
1) 순환 구조: 리스트의 마지막 노드가 첫 번째 노드를 가리키므로, 순환적으로 데이터에 접근할 수 있음.
이를 통해 순차적인 반복 작업을 수행할 때 유용함.
2) 리스트 순회: 원형 연결 리스트는 리스트의 끝과 시작이 연결되어 있으므로,
리스트를 순회하는 데 있어서 종료 조건을 명시할 필요가 없음.
순회 작업을 할 때 끝에 도달하면 다시 첫 번째 노드로 돌아갈 수 있음.
3) 데이터 삽입/삭제: 새로운 노드를 삽입하거나 기존의 노드를 삭제할 때,
주어진 위치에 상관없이 상수 시간에 가능하여 삽입이나 삭제 작업에 대한 효율성이 높아짐.
그러나 원형 연결 리스트는 일반적인 연결 리스트보다 구현이 조금 복잡할 수 있음.
삽입, 삭제, 검색 작업 시 노드의 연결 상태를 잘 관리해야 하며,
순회 작업 시 무한 루프에 빠지지 않도록 주의해야 함.
또한, 원형 연결 리스트의 크기를 동적으로 변경하기 어려울 수 있음.
원형 연결 리스트는 주로 특정 상황에서 활용되며,
예를 들어 라운드 로빈 스케줄링, 알고리즘 문제 해결 등에 유용하게 사용될 수 있음.
5-1. 이터레이터(Iterator)
이터레이터(Iterator)는 컬렉션 내부의 요소들에 순차적으로 접근할 수 있는 객체.
이터레이터는 컬렉션의 내부 구조에 대한 세부 정보를 노출시키지 않으면서
요소들을 반복적으로 처리할 수 있는 방법을 제공함.
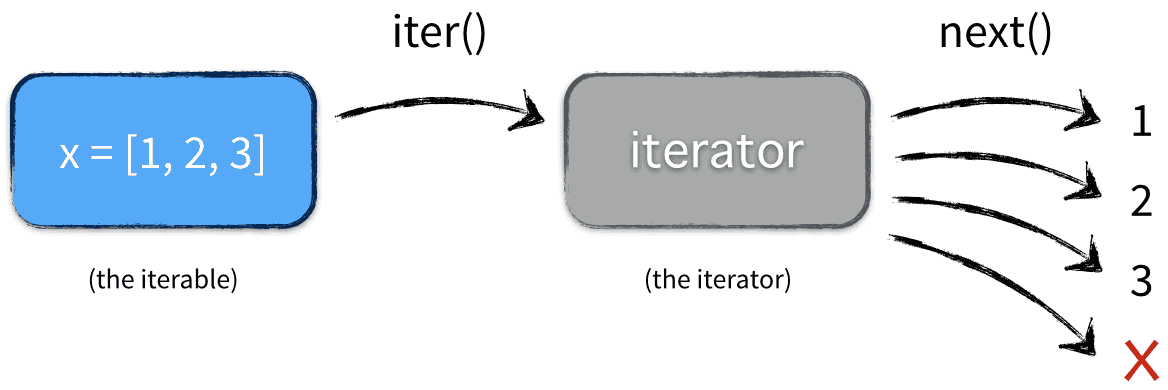
주로 다음과 같은 두 가지 메서드를 제공:
next(): 이 메서드는 다음 요소를 반환함.
만약 컬렉션의 끝에 도달한 경우, 즉 모든 요소를 순회한 경우에는 예외(보통 StopIteration)를 발생시킴.
iter(): 이 메서드는 이터레이터 객체 자신을 반환함.
이를 통해 이터레이터를 직접 반복 가능한 객체(Iterable)로 만들 수 있음.
이터레이터가 반복 가능한 객체로 변환되면 for 루프와 같은 반복 구문에서 사용할 수 있음.
이터레이터는 파이썬과 같은 많은 프로그래밍 언어에서 사용되며,
컬렉션의 크기나 내부 구조에 상관없이 일관된 방식으로 요소에 접근할 수 있게 해줌.
이를 통해 메모리를 효율적으로 사용하고, 대용량 데이터셋에 대한 반복 작업을 가능하게 함.
파이썬에서는 많은 내장 컬렉션(예: 리스트, 튜플, 집합, 딕셔너리)과 함께 이터레이터를 지원하며,
iter() 함수와 next() 함수를 사용하여 이터레이터 객체를 생성하고 다음 요소에 접근할 수 있음.
또한, 컴프리헨션, 제너레이터 등의 기능을 활용하여 사용자 정의 이터레이터를 생성할 수도 있음.
종류:
리스트 이터레이터(List Iterator): 리스트(List)의 요소를 반복적으로 처리하기 위한 이터레이터.
list 객체의 iter() 메서드를 호출하여 생성할 수 있음.
튜플 이터레이터(Tuple Iterator): 튜플(Tuple)의 요소를 반복적으로 처리하기 위한 이터레이터.
tuple 객체의 iter() 메서드를 호출하여 생성할 수 있음.
집합 이터레이터(Set Iterator): 집합(Set)의 요소를 반복적으로 처리하기 위한 이터레이터.
set 객체의 iter() 메서드를 호출하여 생성할 수 있음.
딕셔너리 이터레이터(Dictionary Iterator): 딕셔너리(Dictionary)의 키(key) 또는 값(value)을 반복적으로 처리하기 위한 이터레이터. dict 객체의 keys(), values(), items() 메서드를 호출하여 생성할 수 있음.
문자열 이터레이터(String Iterator): 문자열(String)의 각 문자를 반복적으로 처리하기 위한 이터레이터.
str 객체의 iter() 메서드를 호출하여 생성할 수 있음.
사용자정의 이터레이터(Custom Iterator): 커스텀 데이터 구조나 객체에서 요소를 반복적으로 처리하기 위해 사용자가 직접 정의한 이터레이터.
사용자 정의 클래스 내에서 __iter__()와 __next__() 메서드를 구현하여 생성할 수 있음.
iterator를 통해 개선된 형태:
.extend(): 이전에는 += 연산자를 사용하여 다른 리스트를 현재 리스트에 추가하는 방식으로 구현하였으나,
이터레이터를 활용하면 .extend() 메서드를 사용하여 좀 더 간결하고 효율적인 코드를 작성할 수 있음.
.extend() 메서드는 다른 이터러블(iterable) 객체의 모든 요소를 현재 리스트에 추가함.
# 이전 방식
my_list = [1, 2, 3]
other_list = [4, 5, 6]
my_list += other_list
# 개선된 방식
my_list = [1, 2, 3]
other_list = [4, 5, 6]
my_list.extend(other_list)
.copy() 메서드: 이전에는 .copy() 메서드를 사용하여 리스트를 복사하는 방식으로 구현할 수 있었으나,
.copy() 메서드를 호출하는 대신 슬라이싱(Slicing)을 통해 좀 더 간결하고 빠른 코드를 작성할 수 있음.
슬라이싱을 사용하여 리스트 전체를 복사할 수 있음.
# 이전 방식
my_list = [1, 2, 3]
new_list = my_list.copy()
# 개선된 방식
my_list = [1, 2, 3]
new_list = my_list[:]
.reverse() 메서드: 이전에는 .reverse() 메서드를 사용하여 리스트의 요소 순서를 뒤집는 방식으로 구현하였으나, 이터레이터를 활용하면 리스트를 슬라이싱하여 좀 더 간결하게 코드를 작성할 수 있음.
리스트를 [::-1]과 같이 슬라이싱하면 요소의 순서가 뒤집힌 새로운 리스트를 반환함.
# 이전 방식
my_list = [1, 2, 3]
my_list.reverse()
# 개선된 방식
my_list = [1, 2, 3]
my_list = my_list[::-1]
# 다양한 데이터 구조를 활용하여 이터레이터(Iterator)를 생성하고 사용하는 예시.
lit1 = [1,2,3,4,5]
# lit1이라는 리스트를 생성하고 [1, 2, 3, 4, 5]로 초기화
print(lit1, type(lit1))
# lit1 리스트와 해당 객체의 타입을 출력.
# 결과는 [1, 2, 3, 4, 5] <class 'list'>와 같이 리스트와 리스트 객체의 타입을 나타냄.
print(dir(lit1))
# lit1 리스트 객체가 가지고 있는 속성과 메서드들을 출력함.
결과는 해당 리스트 객체의 모든 속성과 메서드를 나열한 리스트를 나타냄.
litr = iter(lit1) # lit1 리스트를 이터레이터로 변환하기 위해 iter() 함수를 사용하여 litr 변수에 할당함.
print(litr, type(litr)) # litr 이터레이터와 해당 객체의 타입을 출력함.
print(litr.__next__()) # 1이 출력.
print(litr.__next__()) # 2가 출력.
print(litr.__next__()) # 3이 출력.
print(litr.__next__()) # 4가 출력.
print(litr.__next__()) # 5가 출력.
print(litr.__next__()) # 더 이상 반복할 요소가 없기 때문에 __next__() 메서드 호출시 StopIteration 예외 발생.
liter = lit1.__iter__() # lit1 리스트의 __iter__() 메서드를 호출하여 이터레이터 객체 liter를 생성.
print(liter, type(liter)) # 이터레이터와 해당 객체의 타입을 출력
print(liter.__next__()) # 1이 출력.
print(liter.__next__()) # 2가 출력.
dct = {'a': 'apple', 'b': 'banana'} # dct라는 딕셔너리를 생성하고 {'a': 'apple', 'b': 'banana'}로 초기화.
print(dir(dct))
st = {1,2,3} # st라는 세트(Set)를 생성하고 {1, 2, 3}으로 초기화.
print(dir(st))
5-2. 구현
class ListNode:
def __init__(self, new_item, next_node):
self.item = new_item
self.next = next_node
class CircularLinkedList:
def __init__(self):
self.tail = ListNode('dummy', None)
self.tail.next = self.tail
self.num_items = 0
def insert(self, i:int, new_item):
if i >= 0 and i <= self.num_items:
prev = self.get_node(i - 1)
new_node = ListNode(new_item, prev.next)
prev.next = new_node
if i == self.num_items:
self.tail = new_node
self.num_items += 1
else:
print(f'{i}는 범위 안의 인덱스가 아닙니다.')
# 특정 노드의 위치 찾기 : 인덱스가 없어서 직접 찾아야함.
def get_node(self, i:int):
curr = self.tail.next # 더미헤드
for index in range(i+1):
curr = curr.next
return curr
def append(self, new_item):
new_node = ListNode(new_item, self.tail.next)
self.tail.next = new_node
self.tail = new_node
self.num_items += 1
def pop(self, *args):
if self.is_empty():
return None
if len(args) != 0:
i = args[0]
# pop 기본값 -1 설정
if len(args) == 0 or i == -1:
i = self.num_items - 1
if i >= 0 and i < self.num_items:
prev = self.get_node(i-1)
ret = prev.next.item # curr.item
prev.next = prev.next.next
self.num_items -= 1
return ret
else:
return None
def remove(self, x):
(prev, curr) = self.find_node(x)
if curr != None:
prev.next = curr.next
if curr == self.tail:
self.tail = prev
self.num_items -= 1
return x
else:
return None
def find_node(self, x):
# head : 반복문이 종료될 조건 -> curr가 더미헤드를 가리킬 때
# head = prev = self.tail.next
head = self.tail.next
prev = self.tail.next
curr = prev.next # 0번 노드
while curr != head:
if curr.item == x:
return (prev, curr)
else:
prev = curr
curr = curr.next
return (None, None)
def get(self, i: int):
if self.is_empty():
return None
if i >= 0 and i < self.num_items:
return self.get_node(i).new_item
elif i < 0:
return self.get_node(self.num_items + i).item
else:
return None



