12. PyTorch
토치(Torch) 및 카페2(Caffe2)를 기반으로 한 딥러닝 라이브러리. 경쟁작으로 구글의 TensorFlow가 있음.
2017년 9월에 페이스북과 마이크로소프트가 협업하여 개발함.
NumPy의 배열을 Tensor로 가져올 수 있고, 이를 쉽게 GPU상에 올려 연산을 가능하게 함.
TensorFlow의 2.0버전 이후 자유로운 네트워크 수정의 난이도가 점점 높아진 이후
연구원들 사이에서는 PyTorch의 사용 비중이 높아지고 있는 추세.
* 공식 웹사이트: https://pytorch.org/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
* 참고 웹사이트(한국어): https://tutorials.pytorch.kr/
파이토치(PyTorch) 한국어 튜토리얼에 오신 것을 환영합니다!
파이토치(PyTorch) 한국어 튜토리얼에 오신 것을 환영합니다. 파이토치 한국 사용자 모임은 한국어를 사용하시는 많은 분들께 PyTorch를 소개하고 함께 배우며 성장하는 것을 목표로 하고 있습니다.
tutorials.pytorch.kr
# torch 모듈의 version 확인
import torch
print(torch.__version__)
torch: 파이썬 기반의 오픈 소스 머신러닝 라이브러리인 PyTorch의 핵심 모듈. PyTorch는 딥러닝 모델을 구축하고 학습시키기 위한 다양한 기능을 제공하는 인기 있는 프레임워크임. torch 모듈은 다차원 배열을 다루는 데 사용되며, 이러한 배열은 텐서(tensor)라고 불림. 텐서는 NumPy의 다차원 배열과 유사한 구조를 가지고 있으며, GPU를 사용하여 수치 연산을 가속화할 수 있는 기능을 제공함. torch 모듈은 텐서를 생성하고 조작하며, 텐서를 통한 다양한 수학 연산과 변환을 수행할 수 있음. 또한, torch 모듈은 신경망 모델을 구축하기 위한 다양한 클래스와 함수를 제공함. 이러한 기능을 사용하여 다층 퍼셉트론, 컨볼루션 신경망, 순환 신경망 등의 다양한 딥러닝 모델을 구축할 수 있음. 또한, torch 모듈은 신경망 모델의 학습과정을 관리하는데 필요한 최적화 알고리즘과 손실 함수도 포함하고 있음. |
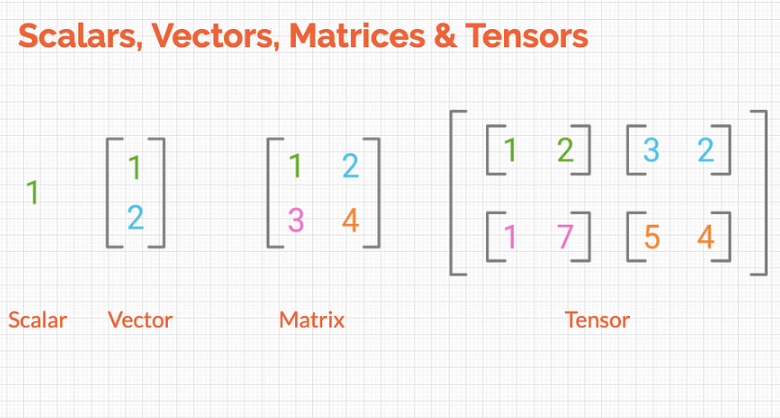
12-1. 스칼라(Scalar)
단일 숫자값으로 구성된 텐서(Tensor)
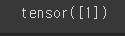
var1 = torch.tensor([1])
var1 # 1은 상수이므로 스칼라라고 불림.
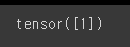
type(var1) # 타입: Tensor

# 두 스칼라의 사칙 연산
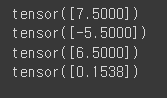
var2 = torch.tensor([6.5])
print(var1 + var2)
print(var1 - var2)
print(var1 * var2)
print(var1 / var2)
12-2. 벡터(Vector)
여러 개의 숫자값을 순서대로 나열한 것. 1차원 텐서(Tensor).
vector1 = torch.tensor([1,2,3])
vector1

# 두 벡터의 사칙연산
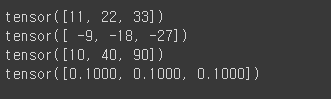
vector2 = torch.tensor([10,20,30])
print(vector1 + vector2)
print(vector1 - vector2)
print(vector1 * vector2)
print(vector1 / vector2)
12-3. 행렬(Matrix)
행과 열로 구성된 직사각형 형태의 배열. 2차원 텐서(Tensor).
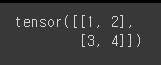
matrix1 = torch.tensor([[1,2],[3,4]])
print(matrix1)
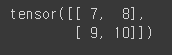
matrix2 = torch.tensor([[7,8],[9,10]])
print(matrix2)
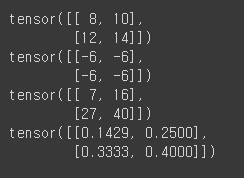
# 두 행렬의 사칙연산
print(matrix1 + matrix2)
print(matrix1 - matrix2)
print(matrix1 * matrix2)
print(matrix1 / matrix2)
12-4. 텐서(Tensor)
텐서는 수학적인 개념으로, 다차원 배열을 나타내는 데이터 구조임.
텐서는 데이터를 표현하는 데 사용되며, 다차원 배열은 스칼라, 벡터, 행렬 등의 다양한 차원을 가질 수 있음.
주로 수학, 과학, 공학 분야에서 사용되며, 데이터를 다루고 분석하기 위해 널리 활용됨.
예를 들어, 딥러닝에서는 이미지, 텍스트, 오디오 등 다양한 유형의 데이터를 텐서로 표현하여 처리하고
모델에 입력으로 제공한다.
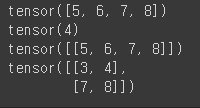
tensor1 = torch.tensor([[[1,2],[3,4]],[[5,6],[7,8]]])
print(tensor1)
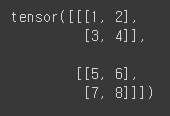
텐서의 차원은 대괄호의 개수로 결정됨. 따라서, tensor1은 3차원임.
tensor2 = torch.tensor([[[9,10],[11,12]],[[13,14],[15,16]]])
print(tensor2)
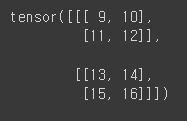
# 두 탠서의 사칙연산 1
print(tensor1 + tensor2)
print(tensor1 - tensor2)
print(tensor1 * tensor2)
print(tensor1 / tensor2)

# 두 탠서의 사칙연산 2
print(torch.add(tensor1, tensor2))
print(torch.subtract(tensor1, tensor2))
print(torch.multiply(tensor1, tensor2))
print(torch.divide(tensor1, tensor2))
print(torch.matmul(tensor1, tensor2)) # 행렬곱연산
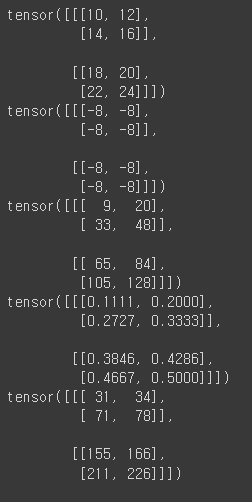
탠서는 자동으로 inplace기능이 부여되어있음
print(tensor1.add_(tensor2)) # tensor1에 tensor2를 add한 내용이 tensor1에 자동으로 재저장됨.
tensor1 # 모든 사칙연산자의 뒤에 언더바(_)를 붙여 사용할 수 있음.

# list를 탠서로 변환
data = [[1,2],[3,4]]
print(data)
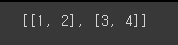
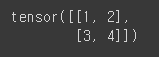
x_data = torch.tensor(data) # ndarray나 list를 torch.tensor()에 삽입하여 탠서로 변환이 가능
print(x_data)
# ndarray를 탠서로 변환
import numpy as np
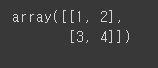
np_array = np.array(data)
np_array
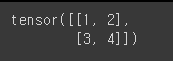
x_np_1 = torch.tensor(np_array)
print(x_np_1)
# 탠서 내 요소의 변경
x_np_1[0,0] = 100
print(x_np_1)
print(np_array)

# torch.as_tensor() 함수의 사용
x_np_2 = torch.as_tensor(np_array)
# torch.as_tensor(): ndarray와 동일한 메모리 주소를 가리키는 뷰를 만드는 함수.
print(x_np_2)
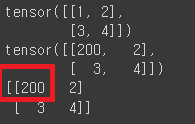
x_np_2[0,0] = 200
print(x_np_2)
print(np_array) # 기존 메모리 주소의 ndarray값도 변경하게 됨.
# 올바른 케이스는 아니라 잘 사용하지는 않는 함수.
# torch.from_numpy() 함수의 사용
x_np_3 = torch.from_numpy(np_array)
# torch.from_numpy(): NumPy 배열을 PyTorch Tensor로 변환하는 함수.
print(x_np_3)
x_np_2[0,0] = 400 # 기존 메모리 주소의 ndarray값도 변경하게 됨.
print(x_np_3)
print(np_array)
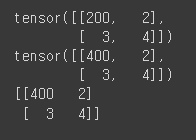
torch.as_tensor() 함수와 torch.from_numpy() 함수의 차이점: torch.as_tensor()는 Numpy array의 사본일 뿐이라, tensor의 값을 변경하더라도 Numpy 배열 자체의 값이 달라지지 않음. 하지만 torch.from_numpy()는 자동으로 input array의 dtype을 상속받고 tensor와 메모리 버퍼를 공유하기 때문에 tensor의 값이 변경되면 Numpy array값이 변경됨. |
# .numpy(): tensor를 다시 nparray로 변경해주는 함수
np_again = x_np_1.numpy()
print(np_again, type(np_again))

12-5. PyTorch 주요함수
# torch.ones(): 행렬을 1로 채움
a = torch.ones(2,3)
print(a)

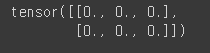
# torch.zeros(): 행렬을 0으로 채움
b = torch.zeros(2,3)
print(b)
# torch.full(): 행렬을 원하는 숫자로 채움
c = torch.full((2,3),10)
print(c)

# torch.empty(): 행렬을 무작위 숫자로 채움
d = torch.empty(2,3)
print(d)

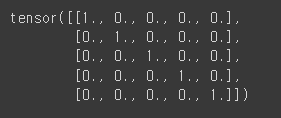
# torch.eye(): 행렬을 사선으로 1, 나머지는 0으로 채움
e = torch.eye(5)
print(e)
# torch.arange(): 배열을 출력
f = torch.arange(10)
print(f)

# torch.rand(): 행렬을 0부터 1사이의 무작위의 숫자로 채움
g = torch.rand(2,3)
print(g)

# torch.randn(): 행렬을 평균이 0이고 표준편차가 1인 숫자로 채움
h = torch.randn(2,3)
print(h)

i = torch.arange(16).reshape(2,2,4) # 2개의 매트릭스 + 2*4 행렬
print(i, i.shape)
j = i.transpose(1,2)
# transpose(): 차원의 index를 이용하여 reshape의 위치를 뒤바꿈.
# 예) reshape(a,b,c) -> transpose(1,2)는 index 1번과 2번인 b와 c를 뒤바꿈.
print(j,j.shape)

k = i.permute((2,0,1))
# permute(): 차원의 index를 이용하여 reshape의 위치를 뒤바꿈.
예) i인 2*2*4 → index 2,0,1에 따라 4,2,2로 변경 → 4개의 매트릭스 + 2*2 행렬
print(k, k.shape)
# 같은 내용이지만 transpose()보다 permute()를 더 많이 사용하는 추세임.

reshape() 함수와 permute() 함수의 차이점 비교

12-6. GPU 사용하기
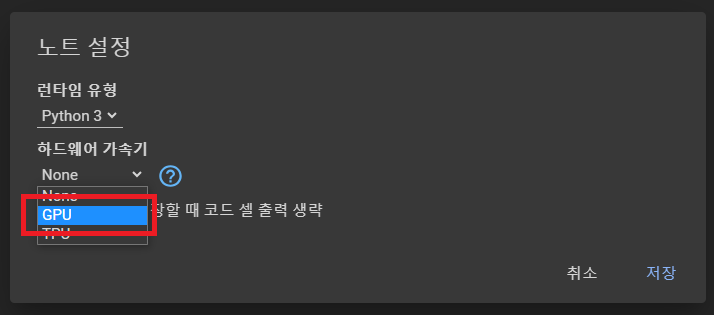
* 코랩에서 device 변경하는 방법
* 상단메뉴 → 런타임 → 런타임 유형 변경
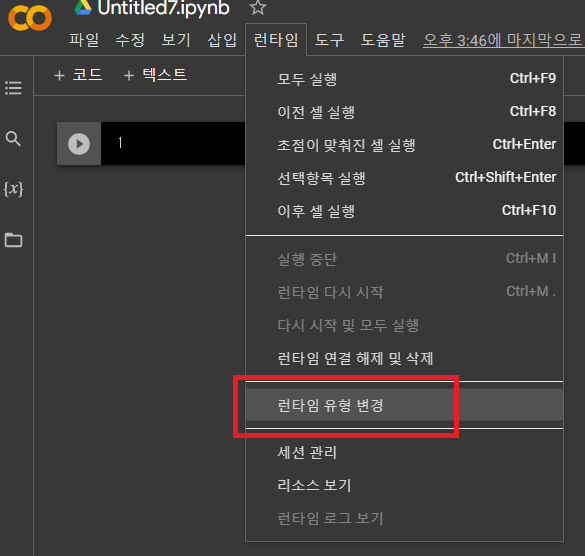
→ 하드웨어 가속기를 GPU로 변경 → 저장
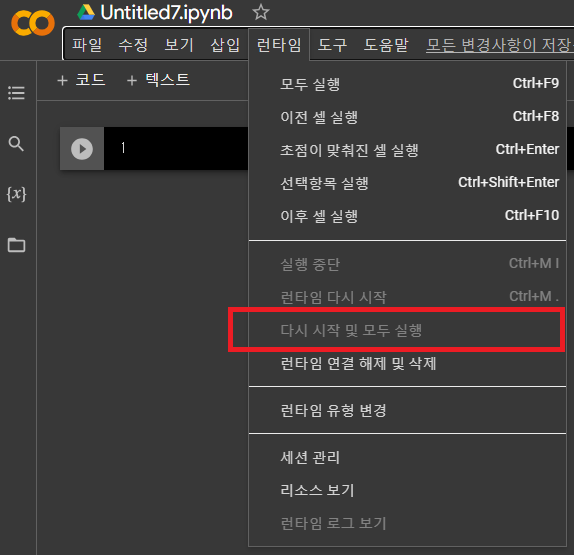
→ 다시 시작 및 모두 실행
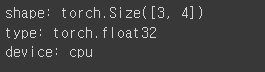
# 임의의 3*4 tensor를 생성 후 shape 출력.
# device가 CPU인 경우
tensor = torch.rand(3,4)
print(f'shape: {tensor.shape}')
print(f'type: {tensor.dtype}')
print(f'device: {tensor.device}')
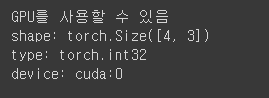
tensor = tensor.reshape(4,3)
tensor = tensor.int() # 요소의 형변환도 진행
if torch.cuda.is_available(): # torch.cuda(): torch의 GPU 확인 속성. is_available(): 확인 가능 여부 체크
print('GPU를 사용할 수 있음')
tensor = tensor.to('cuda') # tensor를 GPU로 보내서 재저장함.
print(f'shape: {tensor.shape}')
print(f'type: {tensor.dtype}')
print(f'device: {tensor.device}')
12-7. 인덱싱 / 슬라이싱
a = torch.arange(1, 13).reshape(3, 4)
print(a)

print(a[1])
print(a[0,-1])
print(a[1:-1])
print(a[:2, 2:])
13. PyTorch구현 - 선형회귀
13-1. 단순 선형회귀
종속 변수는 하나의 독립 변수에만 의존하는 경우를 다루는 회귀 분석.
# 필요한 모듈 및 라이브러리의 설치
import torch
import torch.nn as nn # pytorch로 딥러닝을 만들 수 있게 해주는 모듈
import torch.optim as optim # optimizer: 기울기, 절편을 학습하며 갱신할 수 있게 해주는 알고리즘
import matplotlib.pyplot as plt # 그래프로 찍어보기
입력 데이터 X_train에 대해 출력 데이터 y_train을 예측하는 모델을 학습하려는 경우
# 파이썬 코드를 재실행해도 같은 결과가 나올 수 있게 해주는 시드값을 임의로 설정.
# 난수발생 알고리즘의 초기값을 10으로 주었다는 의미.
torch.manual_seed(10)
X_train = torch.FloatTensor([[1],[2],[3]]) # 3 * 1 크기의 실수형 탠서를 생성하여 입력데이터로 함
y_train = torch.FloatTensor([[2],[4],[6]]) # 3 * 1 크기의 실수형 탠서를 생성하여 출력데이터로 함
print(X_train)
print(X_train.shape)
print(y_train)
print(y_train.shape)
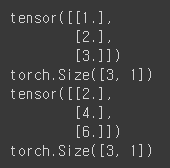
Size의 [3, 1]은 3개의 원소를 가지는 첫 번째 차원, 1개의 원소를 가지는 두 번째 차원이라는 의미.
# 위의 내용을 그래프로 시각화
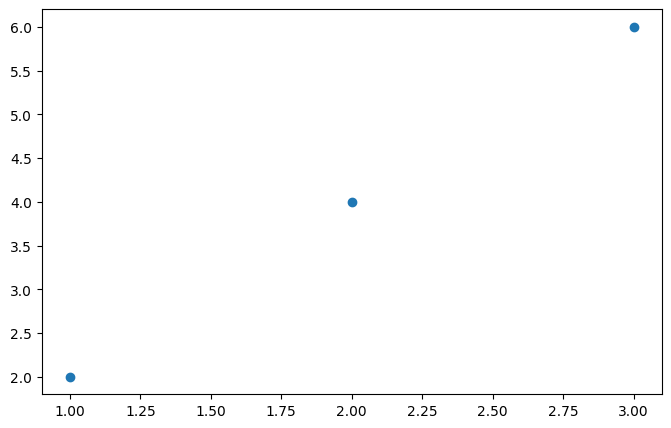
plt.figure(figsize=(8,5)) # 가로로 8인치, 세로로 5인치의 크기를 가진 그림을 생성.
plt.scatter(X_train, y_train) # 다. X_train을 x축 값으로, y_train을 y축 값으로 사용하여 데이터를 산점도로 표현
# 가설 설정
# H = Wx + b
model = nn.Linear(1,1)
# 선형회귀에 해당하는 임의의 입출력 모델 생성 (1개를 입력할 시 1개를 출력해주는 모델)
print(model)

# in_features: 입력값, out_features: 출력값
# bias=True: 선형 회귀 모델에 편향을 포함. 입력변수와 출력변수 관계를 더 정확하게 모델링.
선형 회귀에서 가설을 설정하는 이유는? 입력 변수와 출력 변수 사이의 관계를 모델링하기 위해서임. 가설은 입력 변수와 출력 변수 간의 함수적인 관계를 나타내며, 주어진 입력 값에 대해 예측된 출력 값을 계산하는 데 사용됨. 선형 회귀에서 가설은 일반적으로 선형 함수로 표현됨. 예를 들어, 단순 선형 회귀에서는 가설이 y = wx + b와 같은 형태로 표현될 수 있음. 여기서 w는 가중치(weight)를 나타내며, b는 절편(intercept)을 나타냄. 이 선형 함수는 입력 변수 x와 가중치 w의 곱에 절편 b를 더한 값을 예측된 출력 y로 계산함. |
# 모델의 파라미터 값을 확인하기 위한 예시
print(list(model.parameters()))

해당 출력값은 선형 회귀 모델의 파라미터를 나타내며, 모델의 가중치(weight)와 편향(bias)으로 구성됨.
첫 번째 출력: 가중치(weight)
tensor([[-0.3750]]): 1x1 크기의 텐서. 입력변수와 곱해지는 학습된 가중치를 의미.
이 가중치는 입력 변수와의 선형 조합에 대한 영향력을 조절함.
두 번째 출력: 편향(bias)
tensor([0.2300]): 1x1 크기의 텐서. 입력 변수에 독립적으로 영향을 미치며, 모델의 출력에 보정 값을 제공하는 편향을 나타내는 상수.
각 파라미터는 requires_grad=True로 표시되어 있음.
이는 해당 파라미터가 모델의 학습 과정에서 역전파(backpropagation)되어 업데이트되어야 함을 의미함.
즉, 이 파라미터들은 역방향으로 오차를 전파시키며 모델의 손실 함수를 최소화하는 방향으로 학습됨.
학습을 위해서는 비용함수의 작성이 필요.
비용함수(Cost Function, Loss Function) 기계 학습에서 사용되는 함수로, 모델의 예측 값과 실제 값 사이의 차이를 측정하는 데 사용됨. 모델이 얼마나 정확하게 예측하는지를 평가. |
y_pred = model(X_train) # 입력값인 X_train이 3개이므로 출력값도 3개가 산출됨.
print(y_pred) # 가중치, 편향에 따라 출력된 예측값. 실제값인 y_train에 비해 큰 차이를 보임.
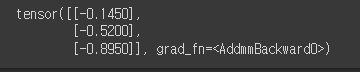
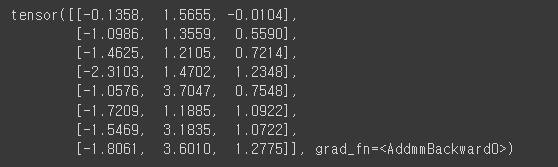
텐서는 3개의 샘플에 대한 예측된 출력 값을 포함하고 있음.
AddmmBackward0은 역전파(backpropagation) 과정에서 그래디언트를 계산하기 위해 사용되는 함수.
역전파 수행을 위해 오차값인 MSE(평균제곱오차)를 찾아야 함
# MSE를 구함 (1번 방법)
((y_pred - y_train) ** 2).mean()

# MSE를 구함 (2번 방법)
loss = nn.MSELoss()(y_pred, y_train) # MSELoss(): MSE를 구하는 함수
print(loss)
# 데이터(x): [[1],[2],[3]]
# W: [-0.0838](기울기)
# B: [-0.0343](y절편)
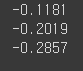
# 예측값(y): [[-0.1181],[-0.2019],[-0.2858]]
# Wx+B 모델을 이용하여 수치를 모두 대입 후 확인해본 결과값.
print(-0.0838*1+-0.0343)
print(-0.0838*2+-0.0343)
print(-0.0838*3+-0.0343)
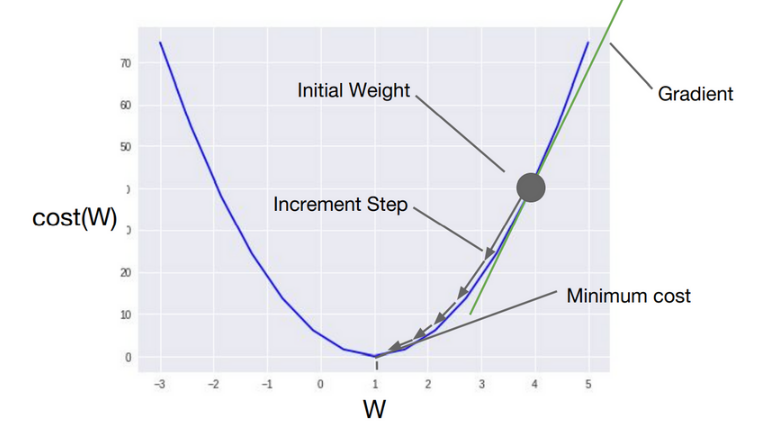
13-2. 경사하강법(Gradient Descent)
경사하강법(Gradient Descent)은 기계 학습과 최적화에서 사용되는 최적화 알고리즘.
주어진 함수의 최솟값을 찾기 위해 사용되며, 특히, 함수가 미분 가능한 경우에 효과적으로 적용됨.
경사하강법은 함수의 기울기(경사)를 이용하여 최솟값에 점진적으로 다가가는 방식으로 동작함.
다음과 같은 단계로 수행:
1) 초기화: 최적화하고자 하는 함수의 파라미터를 초기값으로 설정.
2) 경사 계산: 초기값에서 함수의 기울기(경사)를 계산함.
이는 함수의 편도함수 또는 그래디언트(Gradient)를 사용하여 구할 수 있음.
3) 갱신: 계산된 경사를 이용하여 파라미터를 갱신함.
갱신하는 방법은 학습률(learning rate)이라는 하이퍼파라미터를 사용하여 결정됨.
학습률은 경사하강법의 수렴 속도를 조절하는 역할을 함.
4) 종료 조건 확인: 종료 조건을 확인하여 알고리즘을 종료할지 여부를 결정함.
종료 조건은 일정한 반복 횟수를 설정하거나, 파라미터 갱신이 미세하게 작아지는 등의 기준으로 설정함.
5) 반복: 2~4단계를 반복하여 파라미터를 업데이트하고 최솟값에 점진적으로 다가감.
함수의 곡면을 따라 최솟값으로 이동하기 때문에 볼록한(convex) 함수에서는 보장된 수렴성을 가지며,
전역 최소값을 찾을 수 있음.
그러나 비볼록한(non-convex) 함수에서는 초기값과 학습률에 따라 지역 최소값에 수렴할 수 있음.
경사하강법은 기계 학습에서 매개변수(가중치)를 조정하여 모델을 훈련하는 데 주로 사용됨.
예를 들어, 선형 회귀나 로지스틱 회귀와 같은 모델에서 손실 함수를 최소화하기 위해 경사하강법을 사용하여
최적의 가중치를 찾을 수 있음.
=Optimizer 알고리즘 (비용함수의 값을 최소로하는 W와 B를 찾는 알고리즘)
=최적화 알고리즘
Optimizer 알고리즘을 통해 W와 b를 찾아내는 과정을 학습이라 함.
경사하강법은 가장 기본적인 Optimizer 알고리즘이다.
SGD(): 확률적 경사 하강법(Stochastic Gradient Descent)을 구현한 클래스
학습률(Learning rate): 한번 움직이는 거리(increment step). SGD 스텝의 크기를 결정.
여기서는 lr = 0.01로 줌.
확률적 경사하강법을 이용하여 최적의 파라미터를 찾는 방법
model.parameters() # 최적화할 가중치를 포함하는 파라미터(iterable) 객체
optimizer = optim.SGD(model.parameters(), lr=0.01) # 임의로 데이터를 선택해서 출력해주는 알고리즘.
loss = nn.MSELoss()(y_pred, y_train)
# gradient의 초기화작업 (3줄이 동시에 움직이는 경우 多)
optimizer.zero_grad() # 함수 기울기와 절편의 변수 초기화.
loss.backward() #새롭게 비용함수의 미분값을 통해 얻어낸 기울기와 절편을 입력. (역전파 발생.)
optimizer.step() # 기울기와 절편을 업데이트
print(list(model.parameters()))

# 반복학습(training)이 필요함.
→ 반복훈련을 하며 잘못된 W(기울기)와 b(y절편)을 수정하여 오차를 계속 줄여나가는 것이 최종 목표.
# 1000번을 반복학습하는 내용의 코드
# epochs: 반복훈련횟수
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(X_train)
loss = nn.MSELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
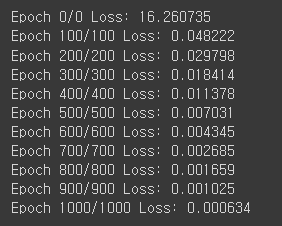
# 100 구간에 따라 어떻게 변화하고있는지 log를 취할 예정
if epoch % 100 == 0:
print(f'Epoch {epoch}/{epoch} Loss: {loss:.6f}')
print(list(model.parameters()))
# 1.9962 * x + 0.0086

X_test = torch.FloatTensor([[10], [12.1234]]) # X_test는 테스트용 입력 데이터로, 입력 데이터를 텐서로 변환하고
# [[10], [12.1234]]를 통해 2개의 샘플에 대한 입력 값을 표현.
y_pred = model(X_test)
print(y_pred)

예측된 출력 값으로 구성된 텐서로, 2개의 샘플에 대한 예측된 출력 값을 포함함.
13-3. 다중 선형회귀
여러 개의 독립 변수를 사용하여 종속 변수를 예측하는 선형 관계를 모델링.
X_train = torch.FloatTensor([[73,80,75],
[93,88,93],
[89,91,90],
[96,98,100],
[73,66,70]])
y_train = torch.FloatTensor([[152],[185],[180],[196],[142]])
print(X_train)
print(X_train.shape)
print(y_train)
print(y_train.shape)
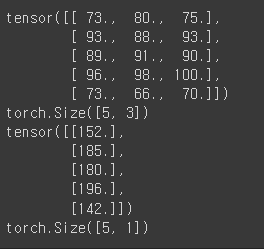
torch.Size([5,3])는 첫번째 차원의 크기가 5, 두번째 차원의 크기가 3임을 의미함.
# H = W1x1 + W2x2 + W3x3 + b
model = nn.Linear(3,1)
print(model) # 3개가 입력되어 1개가 출력된다는 의미.

print(list(model.parameters()))

optimizer = optim.SGD(model.parameters(), lr=0.00001)
# 학습
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(X_train)
loss = nn.MSELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 100 구간에 따라 어떻게 변화하고있는지 log를 취할 예정
if epoch % 100 == 0:
print(f'Epoch {epoch}/{epoch} Loss: {loss:.6f}')
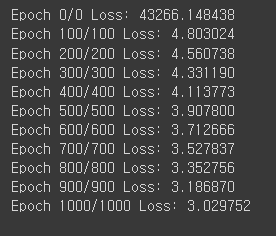
# 최종 파라미터 출력
print(list(model.parameters()))

# 예측
x_test = torch.FloatTensor([[82,92,82]])
y_pred = model(x_test)
print(y_pred)

13-4. temps 데이터셋
import pandas as pd
df_temps = pd.read_csv('/content/drive/MyDrive/K-DT/머신러닝과 딥러닝/temps.csv', encoding='euc-kr')
# 위의 경로는 본인이 파일을 다운받은 경로를 입력
df_temps
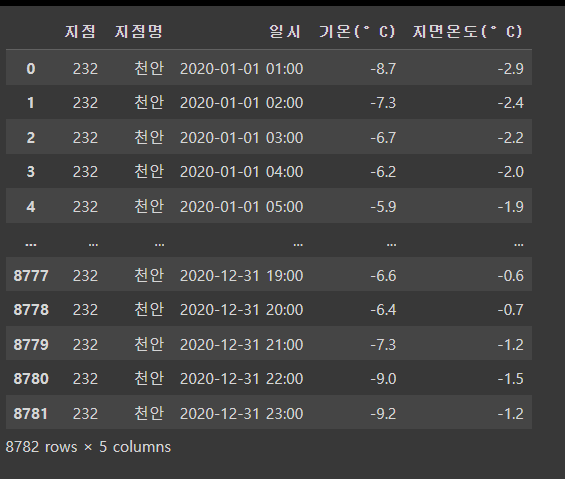
# 데이터의 결측치 찾기
df_temps.isnull().sum()
# 데이터의 결측치 삭제
df_temps = df_temps.dropna()
X_data = df_temps[['기온(°C)']]
y_data = df_temps[['지면온도(°C)']]
X_train = torch.FloatTensor(X_data.values)
y_train = torch.FloatTensor(y_data.values)
print(X_train.shape)
print(y_train.shape)
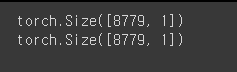
# 위의 내용을 그래프로 작성
plt.figure(figsize=(8,5))
plt.scatter(X_train, y_train)
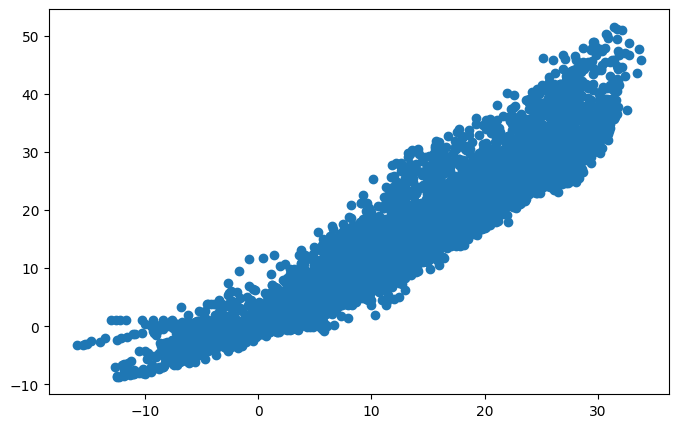
model = nn.Linear(1,1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
print(list(model.parameters()))

# 학습
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(X_train)
loss = nn.MSELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 100 구간에 따라 어떻게 변화하고있는지 log를 취할 예정
if epoch % 100 == 0:
print(f'Epoch {epoch}/{epoch} Loss: {loss:.6f}')
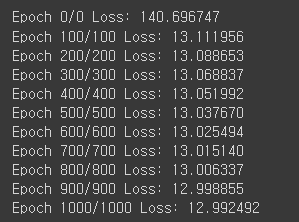
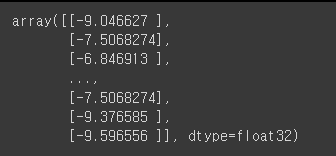
print(list(model.parameters()))
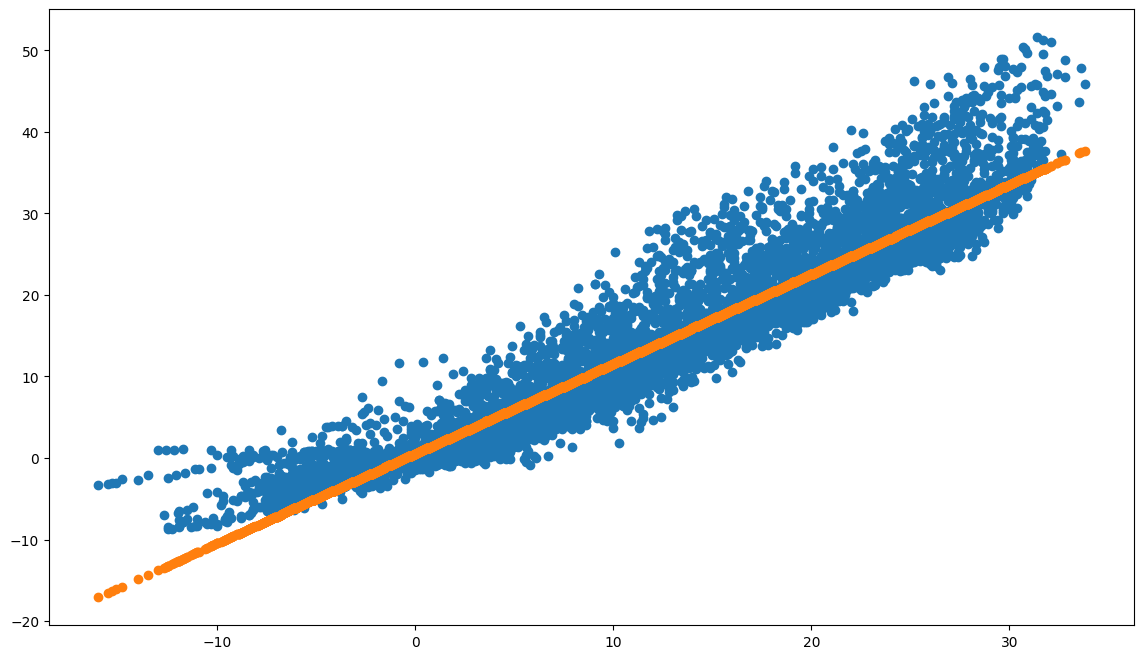
# 1.0999 x + 0.5221

plt.figure(figsize=(14,8))
plt.scatter(X_train, y_train)
plt.scatter(X_train, y_pred)
14. PyTorch구현 - 논리회귀
14-1. 단항 논리회귀(Univariate Logistic Regression)
머신러닝에서 사용되는 분류 알고리즘 중 하나로, 입력 변수(특성)가 하나인 경우에 적용됨.
논리회귀는 주어진 입력 변수의 선형 조합을 사용하여 이진 분류를 수행하는 모델.
단항 논리회귀는 입력 변수가 하나인 경우에 해당하는 변형된 형태로, 주로 연속적인 입력 변수에 대해 적용.입력 변수를 기반으로 예측하고자 하는 이진 결과를 예측하기 위한 시그모이드 함수를 사용함.
간단한 예시로, 주어진 학생의 공부 시간(x)과 해당 학생이 시험에 합격 여부(y) 사이의 관계를 보자면,
단항 논리회귀를 사용하면 공부 시간을 입력으로 사용하여 합격 여부를 예측할 수 있음.
이때, 단항 논리회귀는 입력 변수(공부 시간)와 합격 여부 사이의 선형 관계를 모델링하고,
시그모이드 함수를 통해 예측 확률을 계산함.
정리하자면 단항 논리회귀는 매우 간단한 모델이지만, 이진 분류 문제에 유용하게 사용될 수 있음.
입력 변수가 하나인 경우에 유용하게 적용되며, 특성과 결과 사이의 선형 관계를 모델링하고 예측하는데 사용
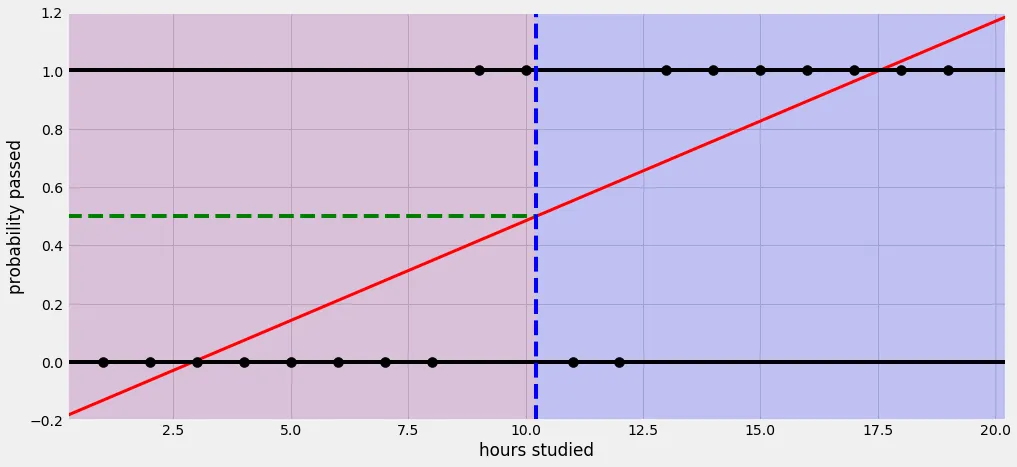
직선 하나(선형 회귀)를 사용해서 예측한다면 제대로 예측할 수 없음.
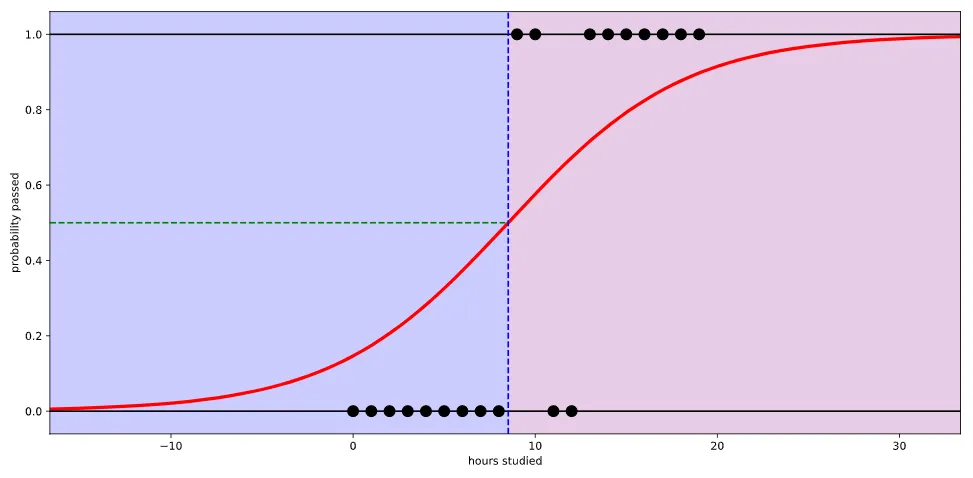
Sigmoid 함수(Logistic 함수)를 사용하여 정확도를 높일 수 있음.
시그모이드(sigmoid) 함수: 입력값을 0과 1 사이의 값으로 변환하는 비선형 활성화 함수. 주로 이진 분류 문제에서 출력층의 활성화 함수로 사용. 시그모이드 함수는 로지스틱(logistic) 함수로도 알려져 있음. 0에서 1사이의 연속된 값을 출력으로 하기 때문에 보통 0.5를 기준으로 구분함. 예를 들어, 시그모이드 함수의 출력값이 0.7이라면 해당 입력에 대한 클래스 1에 속할 확률이 70%라고 해석할 수 있음. 시그모이드 함수는 파이썬의 NumPy, TensorFlow, PyTorch 등 다양한 라이브러리에서 제공되며, 이진 분류 모델에서 주로 사용됨. |
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(10)

# 11시간 이전에는 0을 출력(시험 불합격), 11시간 이후에는 1을 출력(시험 합격)
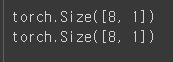
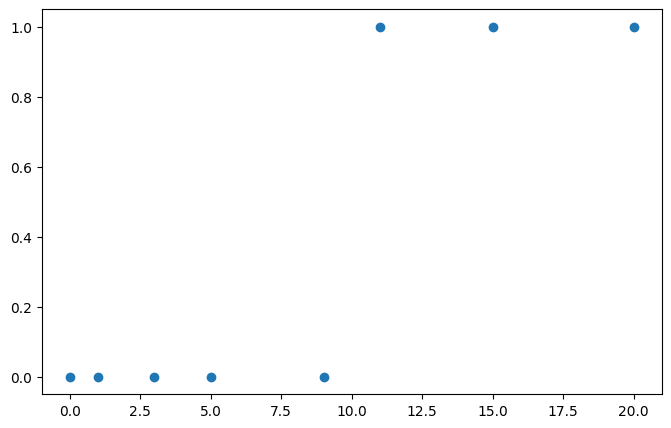
x_train = torch.FloatTensor([[0], [1], [3], [5], [9], [11], [15], [20]])
y_train = torch.FloatTensor([[0], [0], [0], [0], [0], [1], [1], [1]])
print(x_train.shape)
print(y_train.shape)
# 산점도로 시각화
plt.figure(figsize=(8,5))
plt.scatter(x_train, y_train)
# 가설
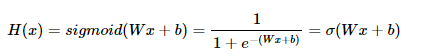
model = nn.Sequential(
nn.Linear(1,1),
nn.Sigmoid()
)
print(model)

layer 순서를 지정
0번: 입출력이 1개씩 정의된 일반적인 직선방정식(linear layer) 모델
1번: Sigmoid 연산(곡선) 수행 예정
# 파라미터 출력
print(list(model.parameters()))

# 비용함수
논리회귀에서는 nn.BCELoss() 함수를 사용하여 Loss를 계산 (BCE: Binary Cross Entropy)

y_pred = model(x_train)
y_pred # 학습이 아직 되지 않은 상태이므로 지금은 크게 의미 없음
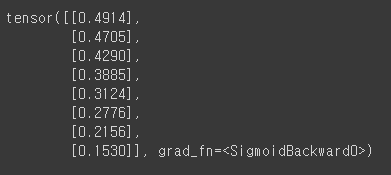
loss = nn.BCELoss()(y_pred, y_train)
loss # 학습이 아직 되지 않은 상태이므로 지금은 크게 의미 없음
optimizer = optim.SGD(model.parameters(), lr=0.01)
optimizer # 학습이 아직 되지 않은 상태이므로 지금은 크게 의미 없음
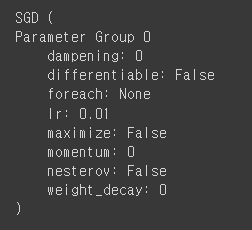
# 1000번 학습
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.BCELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch {epoch}/{epoch} Loss: {loss:.6f}')
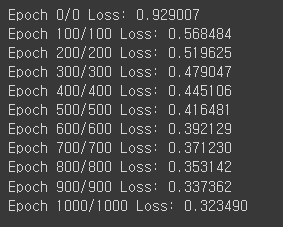
# 파라미터 출력
print(list(model.parameters()))

# 테스트
x_test = torch.FloatTensor([[2.5], [15.5]])
y_pred = model(x_test)
print(y_pred) # 2.5를 입력하여 0.2361 출력 / 15.5를 입력하여 0.8371 출력

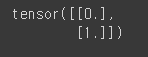
# 임계치 설정
# 0.5보다 크거나 같으면 1, 0.5보다 작으면 0
y_bool = (y_pred >= 0.5).float() # 결과는 T/F가 없으므로, 0과 1로 내보내주어야 한다.
print(y_bool) # 2.5는 0이 출력 → 불합격 / 15.5는 1이 출력 → 합격
14-2. 다항 논리회귀
x_train = [[1,2,1,1],
[2,1,3,2],
[3,1,3,4],
[4,1,5,5],
[1,7,5,5],
[1,2,5,6],
[1,6,6,6],
[1,7,7,7]]
y_train = [0,0,0,1,1,1,2,2]
x_train = torch.FloatTensor(x_train)
y_train = torch.LongTensor(y_train)
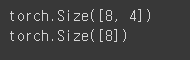
print(x_train.shape)
print(y_train.shape)
model = nn.Sequential(
nn.Linear(4,3)
)
print(model)

y_pred = model(x_train)
print(y_pred)
다항 논리 회귀에서는 BCELoss() 대신 CrossEntropyLoss를 사용함.
소프트맥스 함수가 포함
소프트맥스(softmax) 함수: 입력값을 확률 값으로 변환하는 함수. 주로 다중 클래스 분류 문제에서 출력층의 활성화 함수로 사용. 소프트맥스 함수는 각 클래스에 대한 확률을 계산하는 데 사용되며, 이들 확률의 합은 1이 됨. |
optimizer = optim.SGD(model.parameters(), lr=0.1)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
print(loss) # 오차값 출력

# 1000번 학습
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
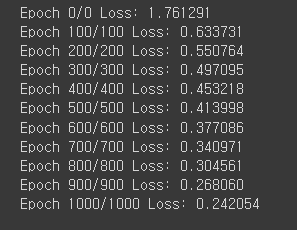
if epoch % 100 == 0:
print(f'Epoch {epoch}/{epoch} Loss: {loss:.6f}')
x_test = torch.FloatTensor([[1,2,5,6]])
y_pred = model(x_test)
print(y_pred) # 4개 입력 후 3개 출력

# 예측값과 확률 구하기
y_prob = nn.Softmax(1)(y_pred)
y_prob

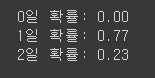
print(f'0일 확률: {y_prob[0][0]:.2f}')
print(f'1일 확률: {y_prob[0][1]:.2f}')
print(f'2일 확률: {y_prob[0][2]:.2f}')
torch.argmax(y_prob, axis=1) # torch.argmax(): 해당 텐서에서 가장 큰 값의 인덱스를 찾음.
# axis=1은 두 번째 차원(행 방향)에서 가장 큰 값의 인덱스를 찾겠다는 의미.
14-3. wine 데이터셋
wine 데이터셋: 이탈리아의 같은 지역에서 재배된 세가지 다른 품종으로 만든 와인을 화학적으로 분석한 데이터셋. |
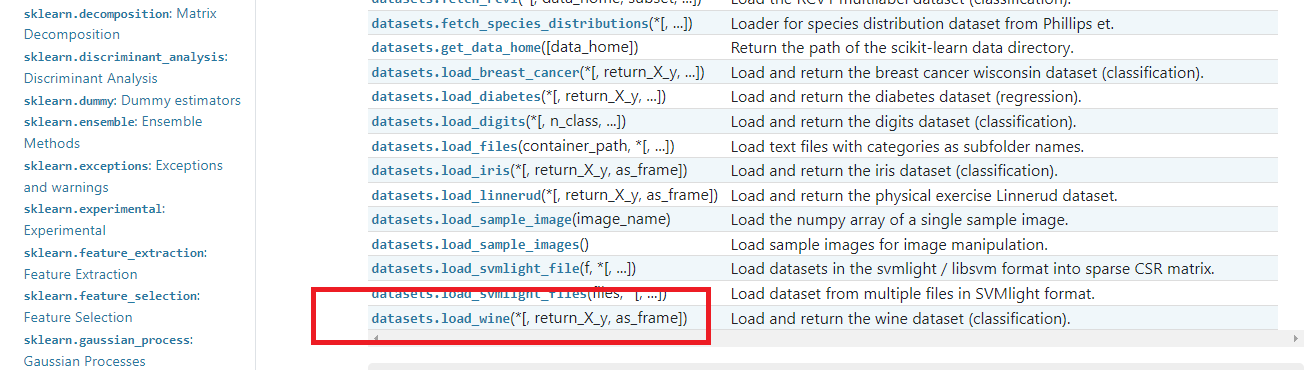
13개의 성분을 분석하여 어떤 와인인지 확인하려는 경우
(단, 트레이닝 데이터를 80%, 테스트 데이터를 20%. 테스트 데이터의 0번 인덱스 및 테스트 정확도 출력.)
# 와인 데이터셋을 로드하고, 입력 데이터와 일부를 출력하여 데이터셋의 구조와 내용을 확인하기 위한 예시.
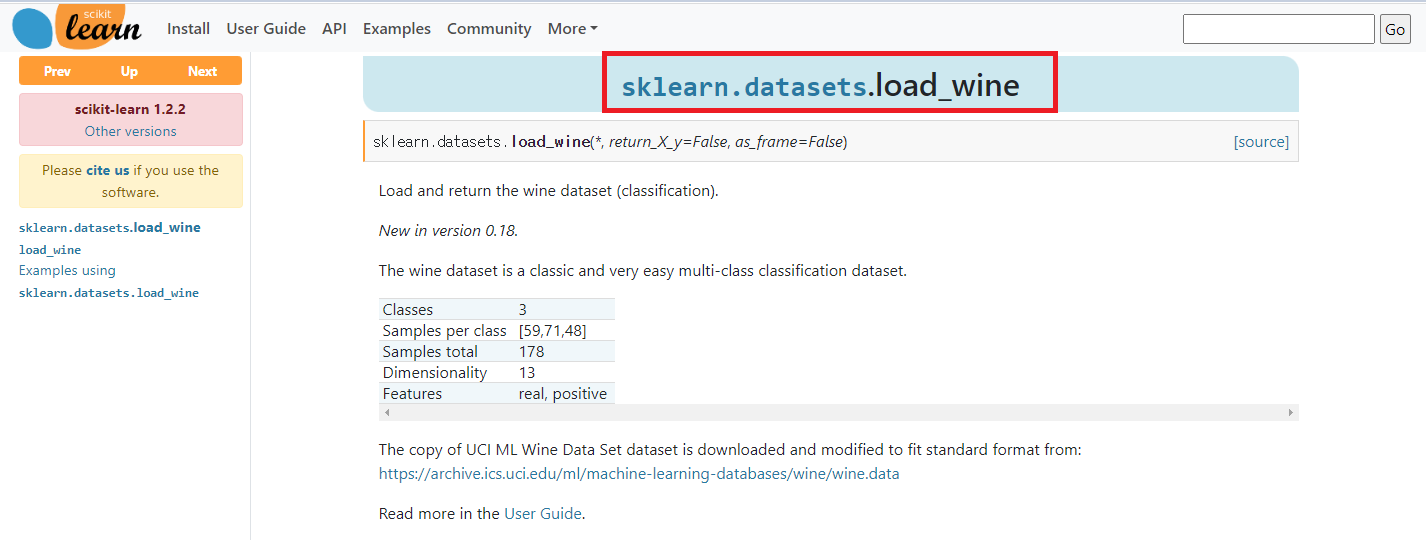
from sklearn.datasets import load_wine
x_data, y_data = load_wine(return_X_y=True, as_frame=True)
# return_X_y=True: 입력 데이터와 출력 데이터를 반환하도록 지정한 매개변수
# as_frame=True: 데이터를 pandas의 DataFrame 형식으로 반환하도록 지정한 매개변수
# DataFrame의 첫 부분을 출력
x_data.head()

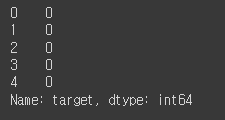
# 품종
y_data.head()
x_data = torch.FloatTensor(x_data.values) # 실수형(Float) 데이터를 다루는 PyTorch의 텐서를 생성
y_data = torch.LongTensor(y_data.values) # 정수형(Long) 데이터를 다루는 PyTorch의 텐서를 생성
# values: dataframe에서 data만 가져온다는 의미
print(x_data.shape)
print(y_data.shape)
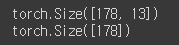
입력 데이터는 178개의 와인 샘플이며, 각 샘플은 13개의 화학적 특성 값을 가지고 있음.
출력 데이터는 178개의 와인 샘플에 대한 클래스 레이블 값을 나타냄.
# train_test_split 함수를 사용하여 입력 데이터와 출력 데이터를 훈련 세트와 테스트 세트로 분할하는 예시
from sklearn.model_selection import train_test_split
# 출력 데이터인 y_data를 원-핫 인코딩으로 변환
# 다중 클래스 분류 문제에서 정답 레이블을 원-핫 인코딩으로 표현하는 일반적인 전처리 과정
y_one_hot = nn.functional.one_hot(y_data, num_classes=3).float()
x_train, x_test, y_train, y_test = train_test_split(x_data, y_one_hot, test_size=0.2, random_state=10)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)

model = nn.Sequential(
nn.Linear(13, 3)
)
optimizer = optim.Adam(model.parameters(), lr=0.01) # SGD자리에 Adam을 바꾸면 성능이 훨씬 개선
# Adam은 SGD보다 성능이 향상될 수 있는 옵티마이저 중 하나이기 때문
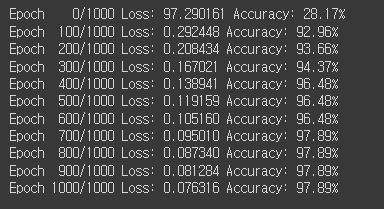
epochs = 1000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
y_train_index = torch.argmax(y_train, axis=1)
accuracy = (y_train_index == y_pred_index).float().sum() / len(y_train) * 100
print(f'Epoch { epoch:4d}/{epochs} Loss: {loss:.6f} Accuracy: {accuracy:.2f}%')
14-4. 경사하강법의 종류
14-4-1. 배치 경사 하강법
가장 기본적인 경사 하강법(Vanilla Gradient Descent).
데이터셋 전체를 고려하여 손실함수를 계산함.
한번의 Epoch에 모든 파라미터 업데이트를 단 한번만 수행함.
Batch의 개수와 Iteration은 1이고 Batch size는 전체 데이터의 개수를 의미.
파라미터 업데이트 시 한번에 전체 테이터셋을 고려하기 때문에
모델 학습 시 많은 시간과 메모리가 필요하다는 단점이 있음.
14-4-2. 확률적 경사 하강법
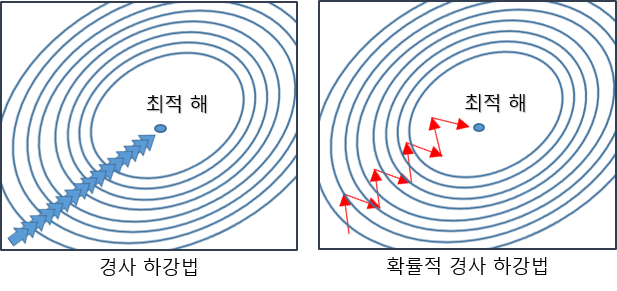
배치 경사 하강법의 많은 시간과 메모리가 필요하다는 단점을 개선하기 위해 제안된 기법.
Batch size를 1로 설정하여 파라미터를 업데이트하기 때문에
배치 경사 하강법보다 훨씬 빠르고 적은 메모리로 학습이 진행됨.
파라미터 값의 업데이트 폭이 불안정하기 때문에 정확도가 낮은 경우가 생길 수 있음.
14-4-3. 미니 배치 경사 하강법
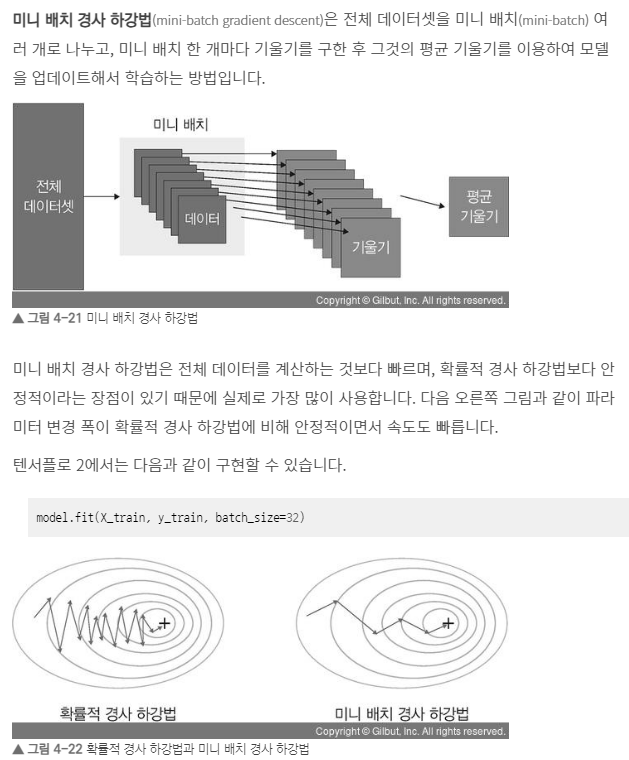
Batch size가 1도 아니고, 전체 데이터 개수도 아닌 경우에 사용.
배치 경사 하강법보다 모델 학습 속도가 빠르고, 확률적 경사 하강법보다 안정적인 장점이 있음.
딥러닝분야에서 가장 많이 활용되는 경사 하강법.
일반적으로 Batch Size를 32, 64, 128과 같이 2의 n제곱에 해당하는 값으로 사용하는 것이 보편적임.
14-5. 경사하강법의 여러 기술
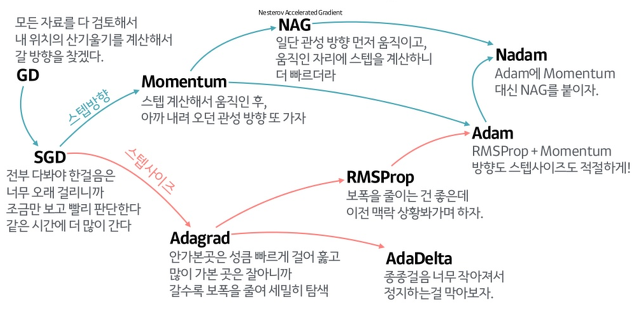
14-5-1. 확률적 경사 하강법(SGD; Stochastic Gradient Descent)
가장 기본적인 경사 하강법의 한 종류.
주어진 데이터셋에서 무작위로 선택한 데이터 샘플을 사용하여
각 학습 단계에서 모델의 가중치를 업데이트하는 방식으로 동작.
14-5-2. 모멘텀(Momentum)
경사하강법에 관성을 부여하여, 이전 업데이트의 방향을 고려하여 현재 업데이트 방향을 조정하는 방법.
이전 업데이트에서의 기울기를 기억하고, 현재 기울기와 합산하여 업데이트 방향을 결정함.
이를 통해 기울기의 변동이 심한 경우에도 보다 안정적으로 최적화 과정을 진행할 수 있음.
접선의 기울기에 한 시점 전의 접선의 기울기 값을 일정한 비율만큼 반영.
예) 언덕에서 공이 내려올 때 중간의 작은 웅덩이에 빠지더라도 관성의 힘으로 넘어서는 효과를 줄 수 있음.
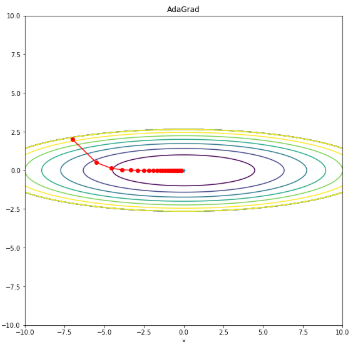
14-5-3. 아다그라드(Adagrad)
각각의 파라미터에 대해 학습률을 조정하는 방식으로 최적화를 수행함.
아다그라드는 파라미터별로 학습률을 조정하기 위해 역사적인 기울기 제곱의 누적값을 사용함.
이전 업데이트에서 많이 변화한 파라미터는 작은 학습률로 업데이트되고,
변화가 적은 파라미터는 큰 학습률로 업데이트됨.
이를 통해 많이 변화한 파라미터에는 보다 조심스럽게 접근하고, 안정적인 업데이트를 할 수 있음.
모든 매개변수에 동일한 학습률을 적용하는 것은 비효율적이라는 생각에서 고안된 학습 방법으로,
처음에는 크게 학습하다 조금씩 작게 학습시킴.
14-5-4. 아담(Adam)
아담은 '모멘텀'과 '아다그라드'를 결합한 최적화 알고리즘.
아담은 각 파라미터별로 적응적인 학습률을 제공하면서도,
이전 기울기의 지수 가중 이동 평균(Exponential Moving Average)을 사용하여 모멘텀과 유사한 효과를 부여. 이를 통해 파라미터의 업데이트를 더욱 조정 가능하며, 빠르고 안정적인 최적화를 수행할 수 있음.
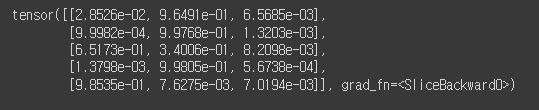
y_pred = model(x_test)
y_pred[:5]

# nn.Softmax를 사용하여 예측된 출력값인 y_pred에 소프트맥스(softmax) 함수를 적용하고,
# 적용된 소프트맥스 함수의 결과에서 처음 5개의 값을 출력하는 예시
# Softmax 함수는 입력 벡터의 각 요소를 0과 1 사이의 확률 값으로 변환하는 함수
# 매개변수 1은 소프트맥스 함수를 두 번째 차원(행 방향)에 적용
y_prob = nn.Softmax(1)(y_pred)
y_prob[:5] # y_prob 텐서에서 처음 5개의 값을 출력
# 0번 인덱스의 품종만 찾기
print(f'0번 품종일 확률: {y_prob[0][0]:.2f}')
print(f'1번 품종일 확률: {y_prob[0][1]:.2f}')
print(f'2번 품종일 확률: {y_prob[0][2]:.2f}')

# 정확도
y_pred_index = torch.argmax(y_prob, axis=1)
y_test_index = torch.argmax(y_test, axis=1)
accuracy = (y_test_index == y_pred_index).float().sum() / len(y_test) * 100
# (y_test_index == y_pred_index)는 예측된 레이블과 실제 레이블이 동일한지를 비교한 불리언(Boolean) 텐서를 생성
print(f'테스트 정확도는 {accuracy:.2f}% 입니다.')

한짤요약