11-1. cluster
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
make_blobs(): 사이킷런(Scikit-learn) 라이브러리에서 제공하는 데이터셋 생성 함수 중 하나로, 지정된 개수의 클러스터를 생성하고, 각 클러스터 내의 데이터 포인트를 생성함. n_samples: 생성할 데이터의 총 개수 centers: 생성할 클러스터의 개수이자 각 클러스터의 중심 개수. |
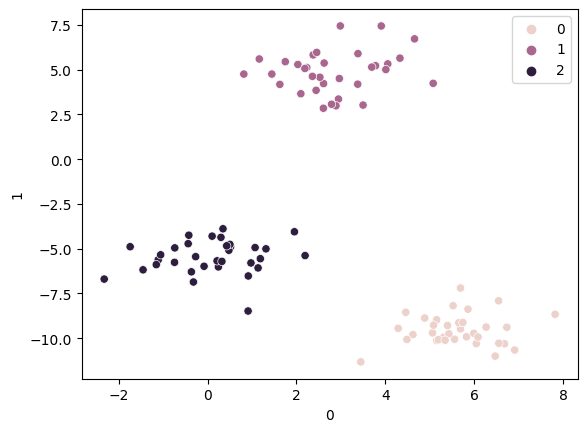
X, y = make_blobs(n_samples=100, centers=3, random_state=10)
X # 총 100개의 row가 2차원 배열로 출력
# dataFrame으로 변경
X = pd.DataFrame(X)
X
y

# scatterplot으로 출력
sns.scatterplot(x=X[0], y=X[1], hue=y)
# KMeans를 import
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3) # 3개의 클러스터를 생성하도록 설정
km.fit(X) # 학습
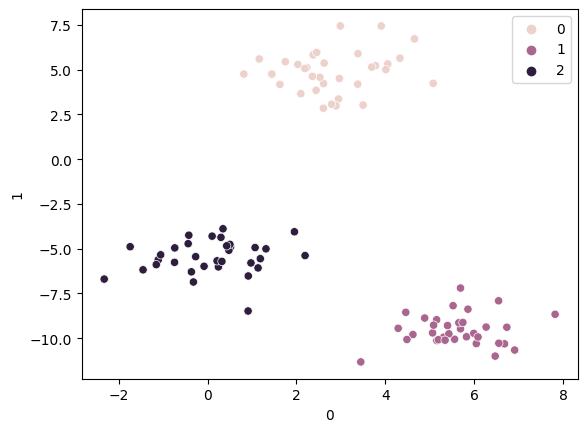
pred=km.predict(X) # 예측
sns.scatterplot(x=X[0], y=X[1], hue=pred)
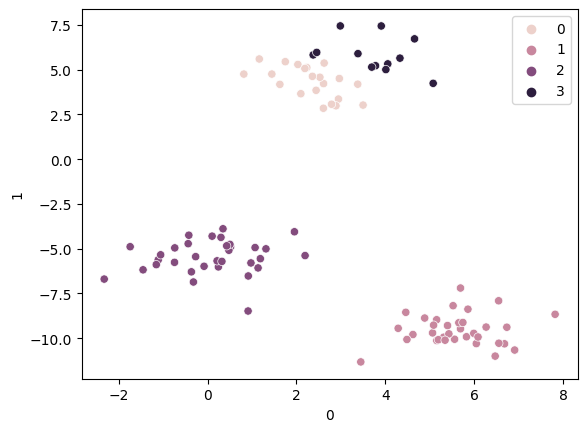
# n_cluster=4로 변경
km = KMeans(n_clusters=4)
km.fit(X)
pred=km.predict(X)
sns.scatterplot(x=X[0], y=X[1], hue=pred)
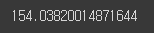
# 비지도학습 kmeans의 평가값 출력
# 하나의 클러스터 안의 중심점으로부터 각각의 데이터 거리를 모두 합한 값
km.inertia_
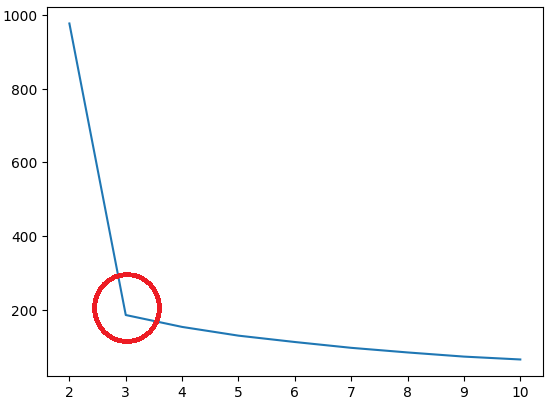
inertia_list = [ ]
for i in range(2,11): # 2개 이상 10개까지의 그룹을 확인하고자 함
km = KMeans(n_clusters=i)
km.fit(X)
inertia_list.append(km.inertia_)
sns.lineplot(x=range(2,11), y=inertia_list)
# 급격하게 꺾이는 부분이 최적의 k값
11-2. marketing 데이터셋
# 마케팅 데이터셋 불러오기
mkt_df = pd.read_csv('/content/drive/MyDrive/K-DT/머신러닝과 딥러닝/marketing.csv')
mkt_df

# columns 40개로 확대
pd.set_option('display.max_columns', 40)
mkt_df.head()

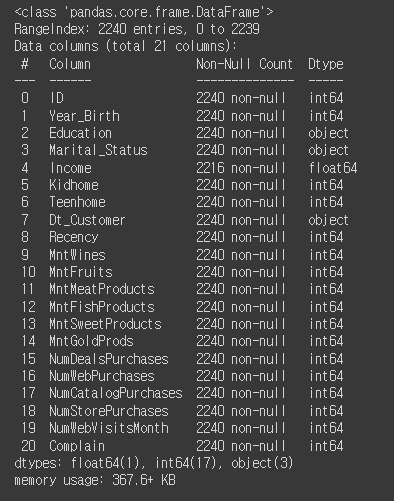
# data 살펴보기
mkt_df.info()
# 필요없는 필드값인 'ID' 필드값을 삭제
mkt_df.drop('ID', axis=1, inplace=True)
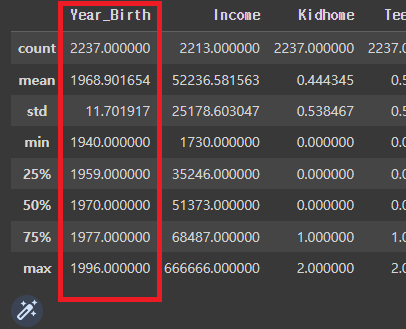
mkt_df.describe()

# 'Year_Birth'를 오름차순 정렬
mkt_df.sort_values('Year_Birth')
# 1899, 1899, 1900은 이상치일 가능성이 높으므로, 삭제가 필요.
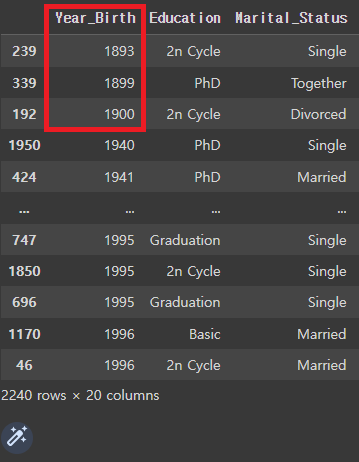
mkt_df = mkt_df[mkt_df['Year_Birth']>1900]
mkt_df.describe()
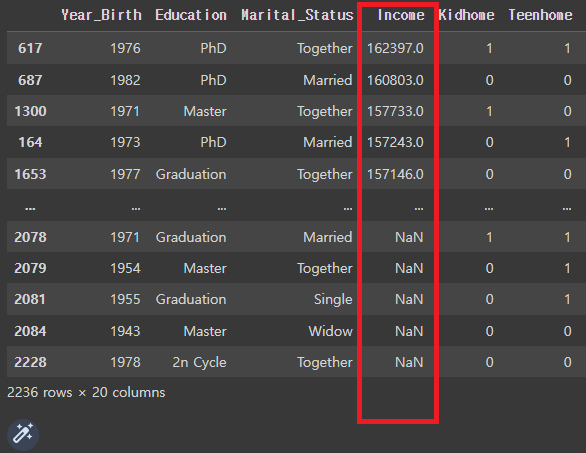
# 'Income'를 내림차순 정렬
mkt_df.sort_values('Income', ascending=False)
# 666666.0은 이상치일 가능성이 높으므로 삭제가 필요.
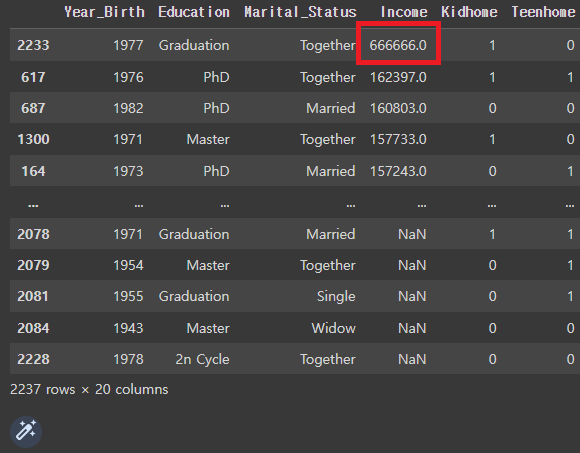
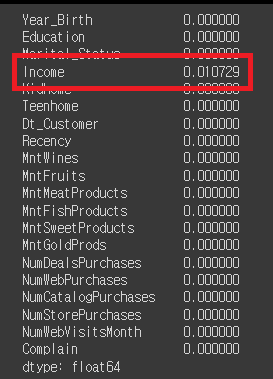
# 'Income'에 존재하는 NaN의 비율을 파악
mkt_df.isna().mean()
# 1%밖에 안되기 때문에 모든 NaN을 삭제해도 영향이 없을것이라 예상 → 삭제
mkt_df = mkt_df[mkt_df['Income']<200000] # 만약 이렇게 실행할 시, NaN이 저장되지않고 삭제되어버림.
# NaN을 남기고 666666을 삭제하려는 경우, 아래의 코드를 이용.
mkt_df=mkt_df[mkt_df['Income'] !=666666]
# 변경 확인
mkt_df.sort_values('Income', ascending=False)
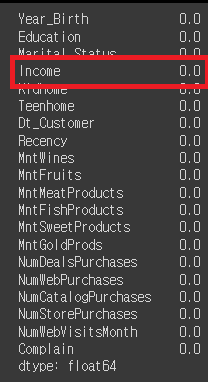
# 'Income'에서 NaN을 삭제
mkt_df = mkt_df.dropna()
# 변경 확인
mkt_df.isna().mean()
mkt_df.info()
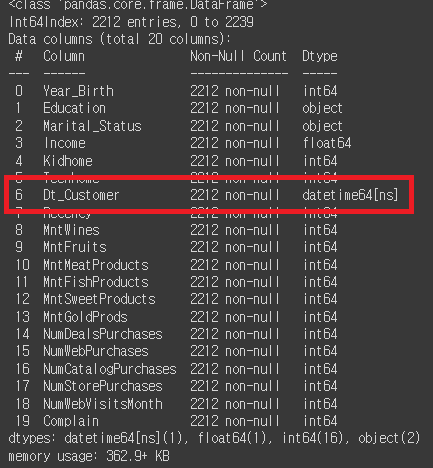
# Dt_Customer는 '가입일'이기 때문에 object타입에서 datetime타입으로의 변경이 필요.
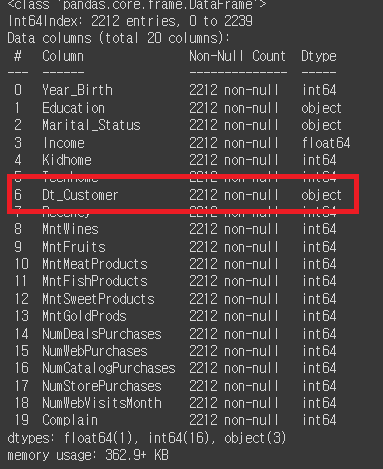
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'])
# 변경 확인
mkt_df.info()
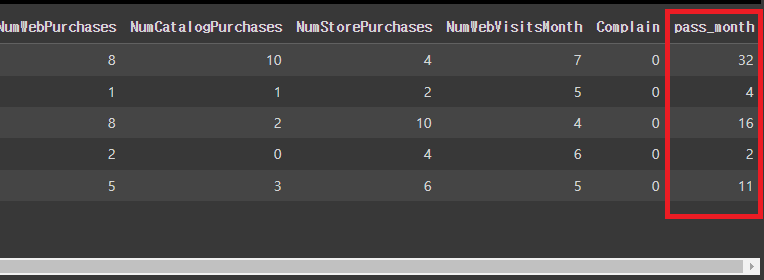
# '총 가입 개월'을 의미하는 파생변수 'pass_month'의 생성이 필요.
# 마지막으로 가입된 사람을 기준으로 가입날짜(월) 구하기
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].max().year*12 + (mkt_df['Dt_Customer']).max().month) - (mkt_df['Dt_Customer'].dt.year*12 + mkt_df['Dt_Customer'].dt.month)
mkt_df.head()
# 필요없어진 가입날짜 'Dt_Customer'를 삭제
mkt_df.drop('Dt_Customer', axis=1, inplace=True)
# 변경 확인
mkt_df.head()

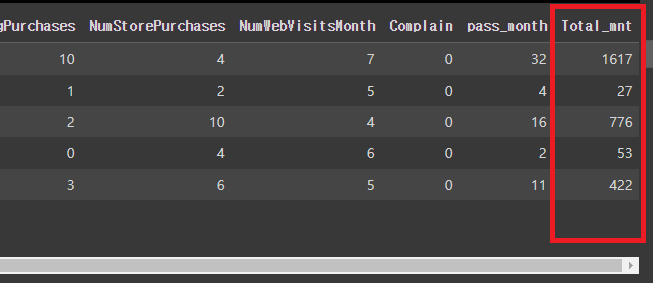
# 파생변수 'Total_mnt'를 새로 생성
(Total_mnt = MntWines+MntFruits+MntMeatProducts+MntFishProducts+MntSweetProducts)
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
mkt_df.head()
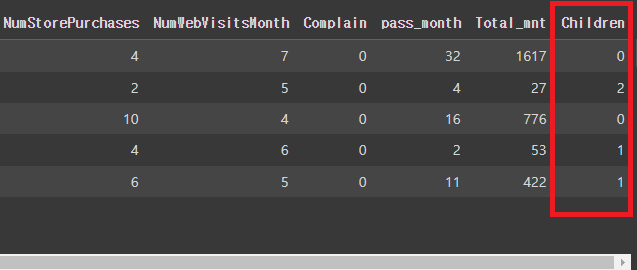
# 파생변수 'Children'을 새로 생성
(Children = Kidhome+Teenhome)
mkt_df['Children'] = mkt_df[['Kidhome', 'Teenhome']].sum(axis=1)
mkt_df.head()
# 필요없어진 필드값 'Kidhome', 'Teenhome'의 삭제 필요
mkt_df.drop(['Kidhome', 'Teenhome'], axis=1, inplace=True)
mkt_df.info()

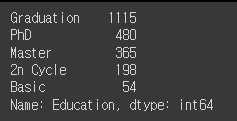
# 'Education'의 value_counts 확인
mkt_df['Education'].value_counts()
# 이상 없으므로 변경없음
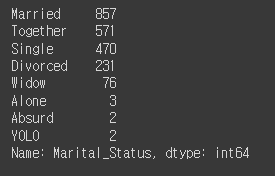
# Marital_Status의 value_counts 확인
mkt_df['Marital_Status'].value_counts()
# values의 값이 많기 때문에, values를 병합하는 작업이 필요
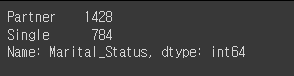
# 'Marital_Status'의 values를 병합하는 작업 (Partner와 Single로 나눌 예정)
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({'Married':'Partner', 'Together':'Partner', 'Single':'Single', 'Divorced':'Single', 'Widow':'Single','Alone':'Single', 'Absurd':'Single', 'YOLO':'Single'})
mkt_df['Marital_Status'].value_counts()
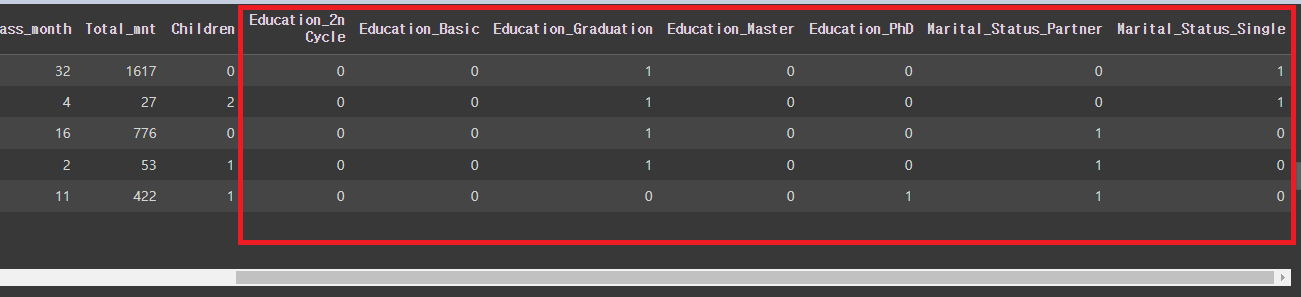
# 원핫인코딩
mkt_df = pd.get_dummies(mkt_df, columns=['Education', 'Marital_Status'])
mkt_df.head()
11-3. 데이터 스케일링(data scaling)
데이터 스케일링은 데이터 모델링 이전에 데이터의 값 범위를 조정하는 작업을 의미함.
데이터의 스케일은 각 변수 또는 특성이 가지는 값의 범위를 말함.
예를 들어, 한 변수의 값 범위가 0부터 1000이고 다른 변수의 값 범위가 0부터 1인 경우,
변수 간의 스케일 차이가 크게 나타남.
데이터 스케일링 사용목적:
변수 간 스케일 차이 해소: 일부 머신러닝 알고리즘은 변수 간의 스케일 차이에 민감하게 반응함.
예를 들어, 거리 기반 알고리즘인 K-NN(K-Nearest Neighbors)은 변수 간의 스케일 차이가 클 경우
예측에 부정적인 영향을 줄 수 있음.
따라서 변수들의 스케일을 조정하여 알고리즘의 성능을 향상시킬 수 있음.
이상치에 대한 영향 완화: 이상치는 값의 범위에서 크게 벗어난 값으로, 데이터의 분포를 왜곡시킬 수 있음.
이상치가 있는 경우, 변수의 스케일을 조정하지 않으면 이상치가 모델 학습에 불균형한 영향을 미칠 수 있음.
데이터 스케일링은 이상치의 영향을 완화하여 모델의 안정성을 높일 수 있음.
데이터 스케일링 방법:
표준화(Standardization): 변수의 평균을 0으로, 표준편차를 1로 변환.
주로 Z-score라고도 불리며, (각 데이터 - 평균) / 표준편차의 공식을 사용.
정규화(Normalization): 변수의 값을 일정한 범위로 변환.
주로 0과 1 사이의 범위로 조정하며, (각 데이터 - 최솟값) / (최댓값 - 최솟값)의 공식을 사용.
데이터 스케일링을 통해 변수들의 스케일을 조정하면, 변수 간의 상대적인 중요도를 더 정확하게
파악하고, 머신러닝 모델의 성능을 향상시킬 수 있음.
11-3-1. 스케일링의 종류
StandardScaler:
StandardScaler는 데이터를 표준화하는데 사용되는 스케일링 방법.
평균이 0이 되고 표준편차가 1이 되도록 데이터를 변환함.
각 데이터 포인트에서 평균을 뺀 후 표준편차로 나누어 스케일링을 수행함.
이상치에 덜 민감하며, 대부분의 경우 데이터를 표준화하는데 널리 사용됨.
MinMaxScaler:
MinMaxScaler는 데이터를 정규화하는데 사용되는 스케일링 방법.
데이터의 최솟값을 0, 최댓값을 1로 변환함.
각 데이터 포인트에서 최솟값을 뺀 후 (최댓값 - 최솟값)으로 나누어 스케일링을 수행함.
데이터의 분포를 보존하면서 스케일링을 수행하므로, 변수의 값을 0과 1 사이로 조정할 때 유용함.
RobustScaler:
RobustScaler는 데이터를 중앙값과 사분위 범위를 이용하여 스케일링하는 방법.
중앙값(median)을 0으로, IQR(Interquartile Range)을 1로 변환함.
IQR은 데이터의 25번째 백분위수와 75번째 백분위수의 차이로, 데이터의 중앙 50% 범위를 나타냄.
이상치에 강건한 방법으로, 데이터의 분포에 영향을 받지 않고 스케일링할 수 있음.
11-3-2. 스케일링의 적용
StandardScaler의 적용:
ss=StandardScaler() # StandardScaler로 스케일링. 평균값과 표준편차를 이용해서 변환.
ss.fit_transform(mkt_df)
# DataFrame으로 변형
pd.DataFrame(ss.fit_transform(mkt_df))
# DataFrame의 저장이 필요한 경우
ss_df = pd.DataFrame(ss.fit_transform(mkt_df), columns=mkt_df.columns)
ss_df
RobustScaler의 적용:
rs = RobustScaler()
rs_df = pd.DataFrame(rs.fit_transform(mkt_df), columns=mkt_df.columns)
rs_df
MinMaxScaler의 적용:
mm = MinMaxScaler()
mm_df = pd.DataFrame(mm.fit_transform(mkt_df), columns=mkt_df.columns)
mm_df
11-4. KMeans
KMeans 알고리즘은 데이터를 K개의 군집(Cluster)으로 나누는 방법을 제공함.
동작 원리
1) 초기화: 군집의 개수 K를 정하고, 무작위로 K개의 중심점을 선택함.
중심점은 데이터의 특성 공간에서 위치한 점으로, 군집의 중심을 대표함.
(초기화가 잘못 설정되는 경우: 중심점의 점간의 거리가 Global optimum인 최소값을 찾는 것이 아니라
중심점이 Local optimum에 수렴하여 잘못된 분류가 이루어지게 됨.)
2) 할당: 각 데이터 포인트를 가장 가까운 중심점에 할당.
이를 통해 데이터 포인트들이 군집에 속하게 됨.
3) 업데이트: 할당된 데이터 포인트를 기반으로 새로운 중심점을 계산.
이는 할당된 데이터 포인트들의 평균 위치로 중심점을 이동시킴.
할당과 업데이트 단계를 반복 수행함. 이 과정은 중심점의 변화가 더 이상 없을 때까지 계속됨.
KMeans 알고리즘은 데이터 포인트와 중심점 간의 거리를 최소화하는 방식으로 군집을 형성.
이를 통해 비슷한 특성을 가진 데이터들이 같은 군집으로 묶이게 됨.
군집화 결과를 바탕으로 데이터의 패턴을 파악하고, 비슷한 특성을 가진 데이터를 그룹으로 분류하여
의미 있는 정보를 도출할 수 있음.
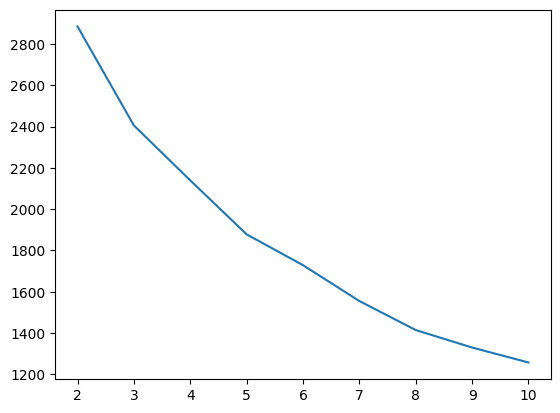
# mm_df로 스케일링 된 것을 학습시킬 예정
inertia_list = [ ]
for i in range(2,11): # 2개 이상 10개까지의 그룹을 확인하고자 함
km = KMeans(n_clusters=i, random_state=10)
km.fit(mm_df)
inertia_list.append(km.inertia_)
inertia_list

# lineplot을 그림.
sns.lineplot(x=range(2,11), y=inertia_list)
# 최적의 k값: 그래프에서 dramatic한 부분은 확인할 수 없음.
11-5. 실루엣 스코어
군집 분석 결과의 품질을 평가하기 위한 지표.
군집 분석은 데이터를 비슷한 특성을 가진 그룹으로 나누는 기법으로,
실루엣 스코어는 이러한 군집 분석 결과의 일관성과 유의성을 측정하는 데 사용.
실루엣 스코어는 각 데이터 포인트가 자신이 속한 군집과 다른 군집과의 거리를 고려하여 계산.
이 거리는 해당 데이터 포인트와 동일한 군집에 속한 다른 데이터 포인트들 간의 평균 거리와,
해당 데이터 포인트와 가장 가까운 다른 군집에 속한 데이터 포인트들 간의 평균 거리를 비교하여 계산.
실루엣 스코어는 -1부터 1까지의 값을 가지며, 각 데이터 포인트의 실루엣 계수는 해당 데이터 포인트의
군집 내부의 거리와 다른 군집 간의 거리를 비교한 결과로 해석할 수 있음.
실루엣 스코어가 1에 가까울수록 데이터 포인트는 자신의 군집에 잘 속해 있으며,
0에 가까울수록 데이터 포인트가 군집 경계에 위치해 있음을 나타냄.
음수 값인 경우는 해당 데이터 포인트가 잘못된 군집에 속해 있는 것을 나타냄.
다른 군집 분석 알고리즘 또는 군집 수를 비교하여 가장 적합한 군집 분석 결과를 선택할 수 있음.
높은 실루엣 스코어는 일관된 군집을 나타내며, 군집 분석의 품질을 높일 수 있는 중요한 평가 지표.
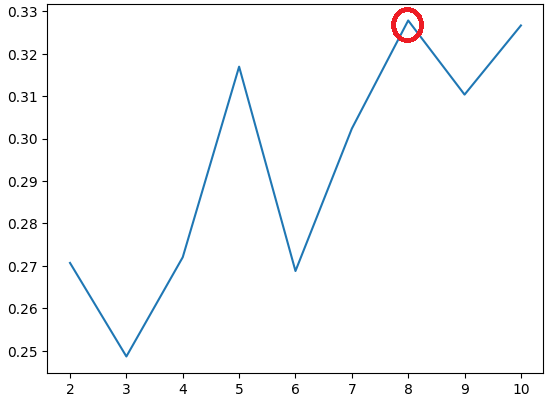
# silhouette_score를 import
from sklearn.metrics import silhouette_score
score = [ ] # 각 군집 수에 대한 실루엣 스코어 값을 저장
for i in range(2,11): # 2개 이상 10개까지의 군집을 확인
km = KMeans(n_clusters=i, random_state=10) # KMeans라는 군집 분석 알고리즘을 생성
km.fit(mm_df) # KMeans 알고리즘을 사용하여 mm_df 데이터에 대해 군집화를 수행
pred = km.predict(mm_df) # 군집화된 결과를 바탕으로 데이터 포인트의 군집 소속을 예측
score.append(silhouette_score(mm_df, pred))
# silhouette_score 함수를 사용하여 예측된 군집 소속에 대한 실루엣 스코어를 계산하고,
이를 score 리스트에 추가함.
# score값을 확인. 높을수록 좋음
score

# lineplot을 그림.
sns.lineplot(x=range(2,11), y=score)
# 8번 군집의 score가 가장 높은 것을 알 수 있음.
km = KMeans(n_clusters=8, random_state=10)
km.fit(mm_df)
pred = km.predict(mm_df)
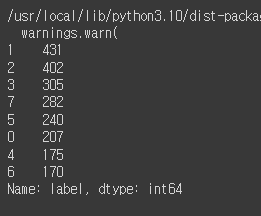
mkt_df['label']=pred
# label'이라는 새로운 열을 생성하고, 해당 열에 군집 소속을 할당함.
이를 통해 각 데이터 포인트가 어떤 군집에 속하는지 나타낼 수 있음.
mkt_df['label'].value_counts()