
0.OT(자료구조-알고리즘)
도움이 되는 웹사이트
* 코드 흐름을 분석:
- 파이썬튜터: https://pythontutor.com/python-debugger.html#mode=edit
Online Python compiler and debugger - Python Tutor - Learn Python by visualizing code
Write code in Python 3.6 Python 2.7 [obsolete] ------ C (gcc 9.3, C17 + GNU) C++ (g++ 9.3, C++20 + GNU) Java 8 JavaScript ES6 Visualize Execution hide exited frames [default] show all frames (Python) inline primitives and try to nest objects inline primiti
pythontutor.com
* 자료구조를 시각화:
- VisuAlgo: https://visualgo.net/en
visualising data structures and algorithms through animation - VisuAlgo
VisuAlgo is generously offered at no cost to the global Computer Science community. If you appreciate VisuAlgo, we kindly request that you spread the word about its existence to fellow Computer Science students and instructors. You can share VisuAlgo throu
visualgo.net
1. 자료구조 (Data Structure)
데이터를 효율적으로 저장하고 조작하기 위한 방법으로, 컴퓨터 과학의 핵심 개념.
효율적인 데이터 처리와 문제 해결을 목적으로 함.
자료구조는 데이터를 조직화하고 저장하는 방법을 정의함. 추상적인 자료모음의 형태.
각 자료구조는 특정한 연산을 수행하기 위한 적절한 방법을 제공함.
예를 들어, 배열은 연속적인 메모리 공간에 데이터를 저장하고, 인덱스를 사용하여 효율적인 접근을 제공함.
연결 리스트는 노드들을 연결하여 데이터를 저장하며, 데이터의 삽입과 삭제가 용이함.
스택과 큐는 데이터의 삽입과 삭제가 제한된 방식으로 이루어지며, 그 특성에 따라 다양한 용도로 활용됨.
트리는 계층적인 구조를 가지며, 검색이나 정렬과 같은 작업에 유용하게 사용됨.
그래프는 노드와 간선으로 이루어진 네트워크 형태의 자료구조로, 실제 세계의 복잡한 상호 관계를 모델링함.
1-1. 추상적 자료형 (Abstract Data Type)
ADT는 데이터와 해당 데이터를 조작하는 연산들을 논리적으로 묶어놓은 개념.
데이터의 내부 구현 방법을 감추고 사용자에게 데이터와 연산들을 추상화된 인터페이스로 제공함
→ 데이터의 독립성과 보안성을 유지할 수 있음.
ADT는 데이터와 데이터를 조작하기 위한 연산들로 이루어져 있음.
예를 들어, 스택(Stack)은 데이터를 저장하고 꺼내는 연산을 지원하는 ADT임.
스택은 일반적으로 "push"와 "pop"이라는 연산으로 데이터를 삽입하거나 삭제하며,
이러한 연산들은 스택의 내부 구현에 대해 알 필요 없이 스택을 사용할 수 있게 해줌.
다른 예로는 큐(Queue)와 리스트(List) 등이 있음.
ADT는 사용자가 데이터와 연산에 대한 개념적인 이해만 갖고 있으면 됨.
(=어떻게 기술하여야 하는지는 특정할 필요 없음.)
내부 구현은 ADT를 구현하는 프로그래머가 담당하게 되고, 이렇게 ADT를 사용하면
데이터의 구체적인 구현 방법에 영향을 받지 않고도 데이터를 다룰 수 있으므로,
프로그램의 모듈화와 재사용성을 높일 수 있음.
사용자는 ADT가 제공하는 연산의 이름, 인자, 반환 값 등에 대한 내용을 알고 있어야 하기 때문에
일종의 '계약'과도 같음.
ADT를 구현하는 프로그래머는 이 계약사항을 만족하는 내부 구현을 제공해야 함.
이렇게 계약을 유지하면, ADT를 사용하는 코드는 ADT의 구현 세부사항에 의존하지 않고 작성될 수 있음.
따라서 추상적 자료형은 프로그래밍에서 데이터의 추상화와 모듈화를 가능하게 하며,
소프트웨어 개발의 유지 보수성과 확장성을 향상시키는데 중요한 개념임.
# 위의 내용을 토대로 Bag이라는 예시를 통해 class로 구현할경우
Bag(): 빈 가방을 새로 만들기
.insert(e): 가방 안에 e 넣기 # e: element의 약자.
.remove(e): 가방 안에서 e 꺼내기.
.contains(e): 가방에 e가 있는 지 검사(있으면 꺼내기)
.count(): 가방에 있는 항목 전체 갯수를 세기.
class Bag:
def __init__(self):
self.mybag = [ ] # '내 가방'이라는 비어있는 list생성. data 저장위치.
def insert(self, e):
self.mybag.append(e)
def remove(self, e):
self.mybag.remove(e)
def contains(self, e):
return e in self.mybag
def count(self):
return len(self.mybag)
# class의 객체화(인스턴스화) 작업
bag1 = Bag()
# 가방 속에 물건 넣기: 핸드폰, 지갑, 동전
물건 = ['핸드폰', '지갑', '동전']
for e in 물건:
bag1.insert(e)
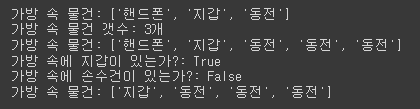
print(f'가방 속 물건: {bag1.mybag}')
# 가방 속의 물건 갯수 확인
print(f'가방 속 물건 갯수: {bag1.count()}개')
# 중복 삽입 -> 동전
bag1.insert('동전')
bag1.insert('동전')
print(f'가방 속 물건: {bag1.mybag}')
# 가방 속에 지갑이 있는지의 여부 확인
print(f'가방 속에 지갑이 있는가?: {bag1.contains("지갑")}')
print(f'가방 속에 손수건이 있는가?: {bag1.contains("손수건")}')
# 핸드폰 꺼내기
bag1.remove('핸드폰')
print(f'가방 속 물건: {bag1.mybag}')
1-2. 자료구조의 종류
복합적 구조 (Composite Structure):
복합적 구조는 다른 자료구조를 조합하여 구성된 구조를 의미함.
예시: 트리(Tree)는 복합적 구조로, 여러 개의 노드와 간선으로 이루어져 있음.
각 노드는 자체적으로 하위 트리를 가지고 있을 수 있음.
선형 구조 (Linear Structure):
선형 구조는 데이터 요소를 일렬로 나열한 형태의 구조를 의미함.
예시: 배열(Array)과 연결 리스트(Linked List)는 선형 구조임. 배열은 인덱스를 통해 데이터에 접근하며,
연결 리스트는 노드들이 링크로 연결되어 있음.
비선형 구조 (Non-linear Structure):
비선형 구조는 데이터 요소들 사이에 계층적이거나 네트워크 형태의 연결이 있는 구조를 의미함.
예시: 그래프(Graph)는 비선형 구조로, 노드와 간선으로 이루어져 있으며
노드들 간에 다양한 연결 관계가 있음.
사전 구조 (Hierarchical Structure):
사전 구조는 계층적인 구조로 데이터를 저장하는 형태를 의미함. 데이터는 계층적으로 그룹화되고 정렬됨.
예시: 트리(Tree)는 사전 구조에 해당함. 트리는 하나의 루트 노드에서 시작하여 다양한 하위 노드들로
나뉘어지는 계층 구조를 가지고 있음.
2. 알고리즘(Algorithm)
주어진 문제를 해결하기 위한 절차나 방법을 의미.
알고리즘은 입력(input)을 받아 출력(output)을 생성하는데, 이때 주어진 문제에 대해 올바른 출력을 생성하는 것뿐만 아니라 효율적으로 동작하는 것도 중요함.
알고리즘은 일련의 단계를 통해 실행되며, 각 단계는 주어진 작업을 수행함.
예를 들어, 정렬 알고리즘은 주어진 데이터를 일정한 기준에 따라 정렬하는 방법을 제시하며,
검색 알고리즘은 특정한 값을 찾는 방법을 제공함.
자료구조와 알고리즘은 서로 밀접하게 연관되어 있음.
알고리즘은 효율적인 자료구조를 활용하여 작업을 수행하며,
자료구조는 적절한 알고리즘을 지원하기 위해 설계됨.
2-1. 알고리즘의 효율성
알고리즘의 효율성은 주어진 문제를 해결하는 데에 소요되는 시간과 자원(메모리 등)의 양을 나타냄.
알고리즘의 실행 시간과 사용하는 자원의 양에 따라 결정됨.
더 효율적인 알고리즘은 더 빠르게 실행되고, 적은 자원을 사용하여 동일한 작업을 수행할 수 있음.
알고리즘의 효율성은 일반적으로 시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)를
사용하여 분석됨.
시간 복잡도(Time Complexity):
알고리즘의 실행 시간을 분석하고 예측하는 데 사용됨.
=특정 알고리즘이 어떤 문제를 해결하는데 걸리는 시간.
일반적으로 Big O 표기법을 사용하여 표현됨.
시간 복잡도는 입력 크기에 대한 함수로 표현되며, 입력 크기가 증가함에 따라 알고리즘의 실행 시간이 어떻게 증가하는지를 나타냄.
예시: O(1), O(log n), O(n), O(n^2) 등이 일반적인 시간 복잡도 표기임.
공간 복잡도(Space Complexity):
알고리즘의 실행에 필요한 메모리 공간의 양을 분석하고 예측하는 데 사용됨.
일반적으로 Big O 표기법을 사용하여 표현됨.
공간 복잡도는 알고리즘이 동작하는 동안 사용되는 추가 메모리의 양을 나타냄.
예시: O(1), O(n), O(n^2) 등이 일반적인 공간 복잡도 표기임.
알고리즘의 효율성은 컴퓨터 과학과 소프트웨어 개발에서 핵심적인 관점이며,
효율적인 알고리즘 선택은 프로그램의 성능과 사용자 경험에 직결됨.
2-2. 빅오 표기법 (Big O Notation)
알고리즘의 시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)를 표기하는 방법 중 하나로,
알고리즘의 성능을 분석하고 비교하기 위해 사용됨.
빅오표기법은 알고리즘의 실행 시간 또는 메모리 사용량이 입력 크기에 어떻게 비례하는지를 나타냄.
주어진 알고리즘의 실행 시간 또는 메모리 사용량이 입력 크기 n에 대해 "최악의 경우" 어떻게 증가하는지를 표기함. 여기서 "최악의 경우"는 입력이 가장 크거나 가장 불리한 경우를 의미함.
빅오표기법은 상수 계수, 낮은 차수의 항, 상수 항을 무시하고 알고리즘의 성능을 대략적으로 표현하는 방식.
대표적 표기법:
O(1) (상수 시간): 입력 크기에 상관없이 일정한 실행 시간 또는 공간을 갖는 알고리즘을 나타냄.
예를 들어, 배열에서 특정 인덱스의 요소를 찾는 경우 등이 O(1)의 시간 복잡도를 가짐.
O(log n) (로그 시간): 입력 크기에 대해 로그의 형태로 증가하는 알고리즘을 나타냄.
예를 들어, 이진 검색 알고리즘 등이 O(log n)의 시간 복잡도를 가짐.
O(n) (선형 시간): 입력 크기에 정비례하여 선형적으로 증가하는 알고리즘을 나타냄.
예를 들어, 배열에서 모든 요소를 한 번씩 확인하는 경우 등이 O(n)의 시간 복잡도를 가짐.
O(n^2) (이차 시간): 입력 크기의 제곱에 비례하여 증가하는 알고리즘을 나타냄.
예를 들어, 이중 반복문을 사용하여 모든 요소 쌍을 확인하는 경우 등이 O(n^2)의 시간 복잡도를 가짐.
빅오표기법은 알고리즘의 성능을 대략적으로 파악하기 위해 사용되며, 알고리즘들 간의 상대적인 성능 비교에 유용함. 더 작은 빅오표기법을 갖는 알고리즘은 일반적으로 더 효율적이라고 할 수 있음.
하지만 빅오표기법만으로는 알고리즘의 세부 동작이나 실제 실행 시간을 정확히 예측하는 것은 불가능하며, 실제 상황에 따라 다를 수 있음. 따라서 알고리즘 선택 시에는 다른 요소들도 고려해야 함.



