
7. 로지스틱 회귀(Logistic Regression)

통계학과 머신 러닝에서 사용되는 분류 알고리즘.
이 알고리즘은 입력 변수와 출력 변수 사이의 관계를 모델링하고,
주어진 입력 값에 대해 출력 값을 예측하는 데 사용됨.
로지스틱 회귀는 이름은 회귀(regression)를 포함하나, 이진 분류(binary classification)에 주로 사용됨.
이는 입력 변수를 기반으로 주어진 데이터 포인트가 두 개의 클래스 중 하나에 속하는지 예측하는 것을 의미.
로지스틱 회귀의 핵심 아이디어는
선형 회귀와 로지스틱 함수인 시그모이드 함수(sigmoid function)를 조합하는 것임.
로지스틱 회귀는 입력 변수의 선형 조합을 계산한 후, 이 값을 시그모이드 함수에 적용하여 0과 1 사이의
확률 값으로 변환함.
일반적으로, 0.5 이상의 확률 값을 가진 데이터 포인트는 한 클래스에 속하고,
0.5 미만의 확률 값을 가진 데이터 포인트는 다른 클래스에 속한다고 예측함.
경사 하강법(gradient descent) 등의 최적화 알고리즘을 사용하여 모델의 파라미터를 학습함.
이러한 학습을 통해 로지스틱 회귀 모델은 주어진 입력 변수에 대한 적절한 예측을 수행할 수 있음.
로지스틱 회귀는 다양한 분야에서 사용되며,
예를 들어 의학 분야에서 암 여부 예측, 신용카드 사기 탐지 등에 적용될 수 있음.
7-1. HR 데이터셋
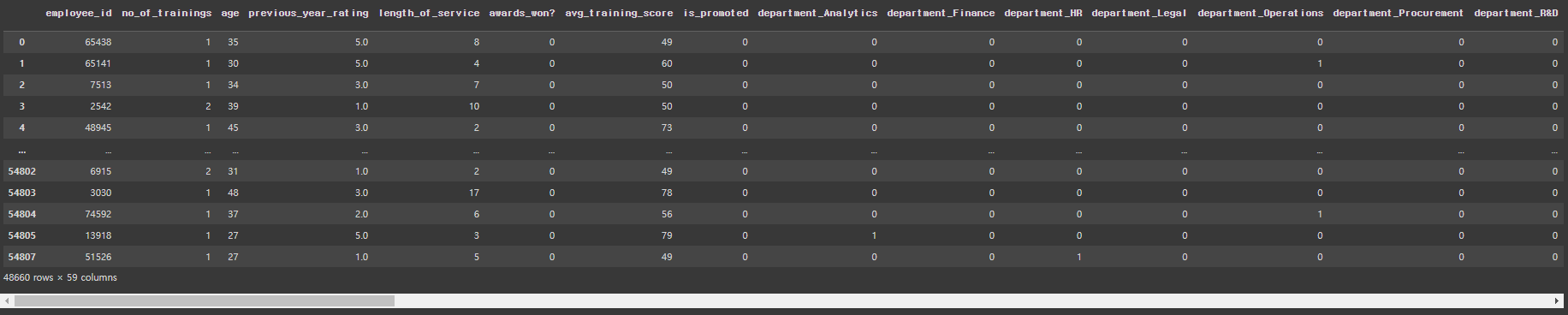
HR 데이터셋 관련 내용 * employee_id : 임의의 직원아이디 * department : 부서 * region : 지역 * education : 학력 * gender : 성별 * recruitment_channel : 채용경로 * no_of_trainings : 교육횟수 * age : 나이 * previous_year_rating : 이전년도 고과점수 * length_of_service : 근속년수 * awards_won : 수상경력 * avg_training_score : 평균고과점수 * is_promoted : 승진여부 |
# 필요한 라이브러리를 import
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 예시로 사용할 데이터 파일을 불러옴
hr_df = pd.read_csv('/content/drive/MyDrive/K-DT/머신러닝과딥러닝/hr.csv')
▲ 위의 볼드체는 본인이 파일을 다운받은 경로를 입력
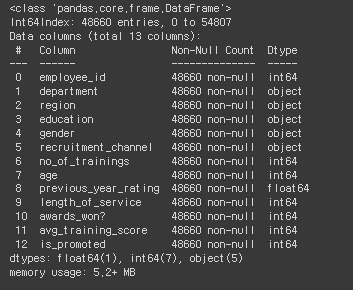
hr_df.head()

hr_df.info()

hr_df.describe()

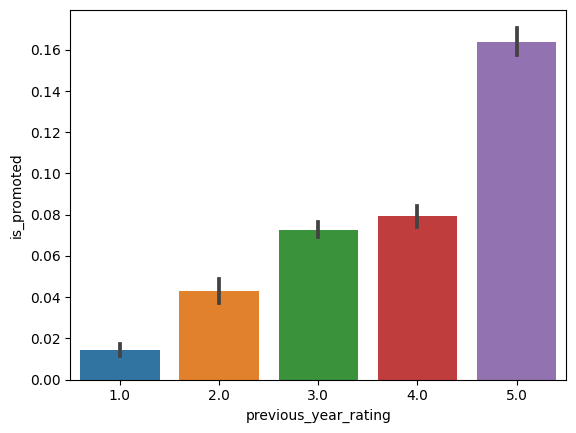
# barplot을 통해 전년도 고과점수와 승진여부의 상관관계 파악
sns.barplot(x='previous_year_rating', y='is_promoted', data=hr_df)
# 위의 내용을 lineplot으로 그려보기
sns.lineplot(x='previous_year_rating', y='is_promoted', data=hr_df)

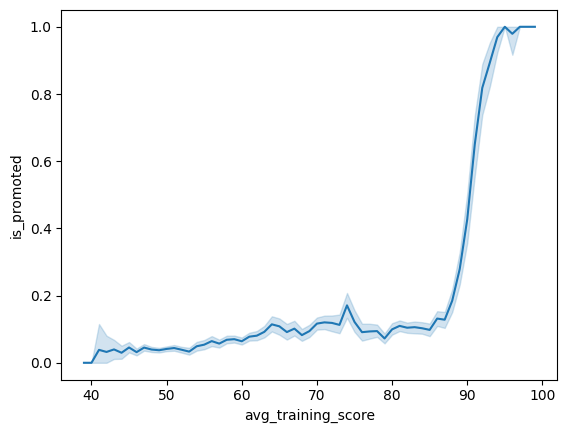
# lineplot을 통해 교육횟수와 승진여부의 상관관계 파악
sns.lineplot(x='avg_training_score', y='is_promoted', data=hr_df)
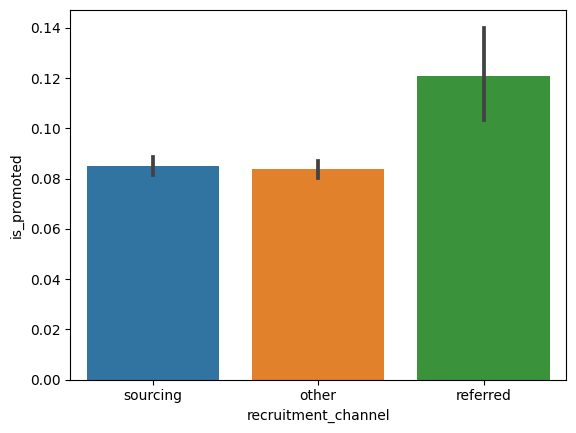
# barplot을 통해 채용경로와 승진여부의 상관관계 파악
sns.barplot(x='recruitment_channel', y='is_promoted', data=hr_df)
# 검은색 캔들바: 오차율
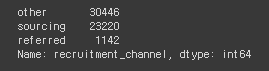
# recruitment_channel의 데이터 종류와 수
hr_df['recruitment_channel'].value_counts()
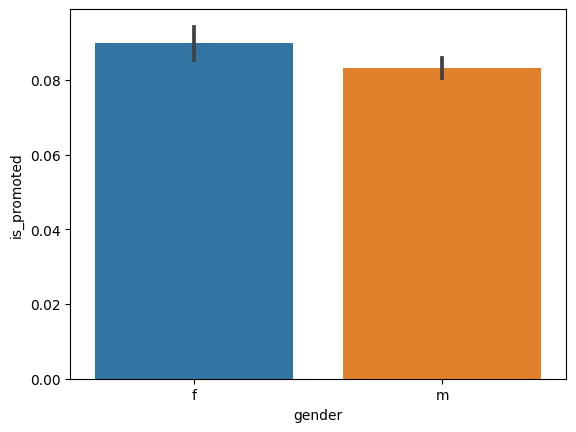
# 성별과 승진여부간의 상관관계 파악
sns.barplot(x='gender', y='is_promoted', data=hr_df)
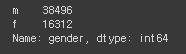
# gender의 데이터 종류와 수
hr_df['gender'].value_counts()
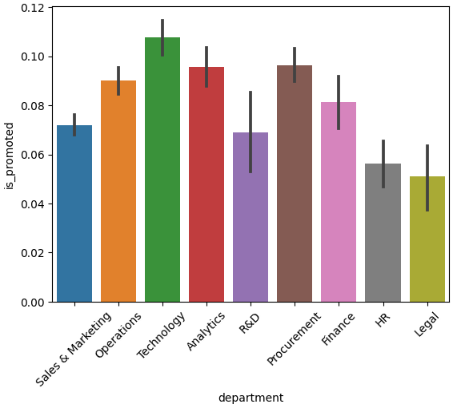
# 부서와 승진여부간의 상관관계 파악
sns.barplot(x='department', y='is_promoted', data=hr_df)
plt.xticks(rotation=45) # x축의 라벨값을 45도 회전하여 겹치지 않도록 함
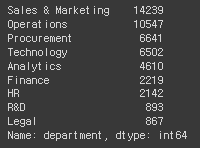
# department의 데이터 종류와 수
hr_df['department'].value_counts()
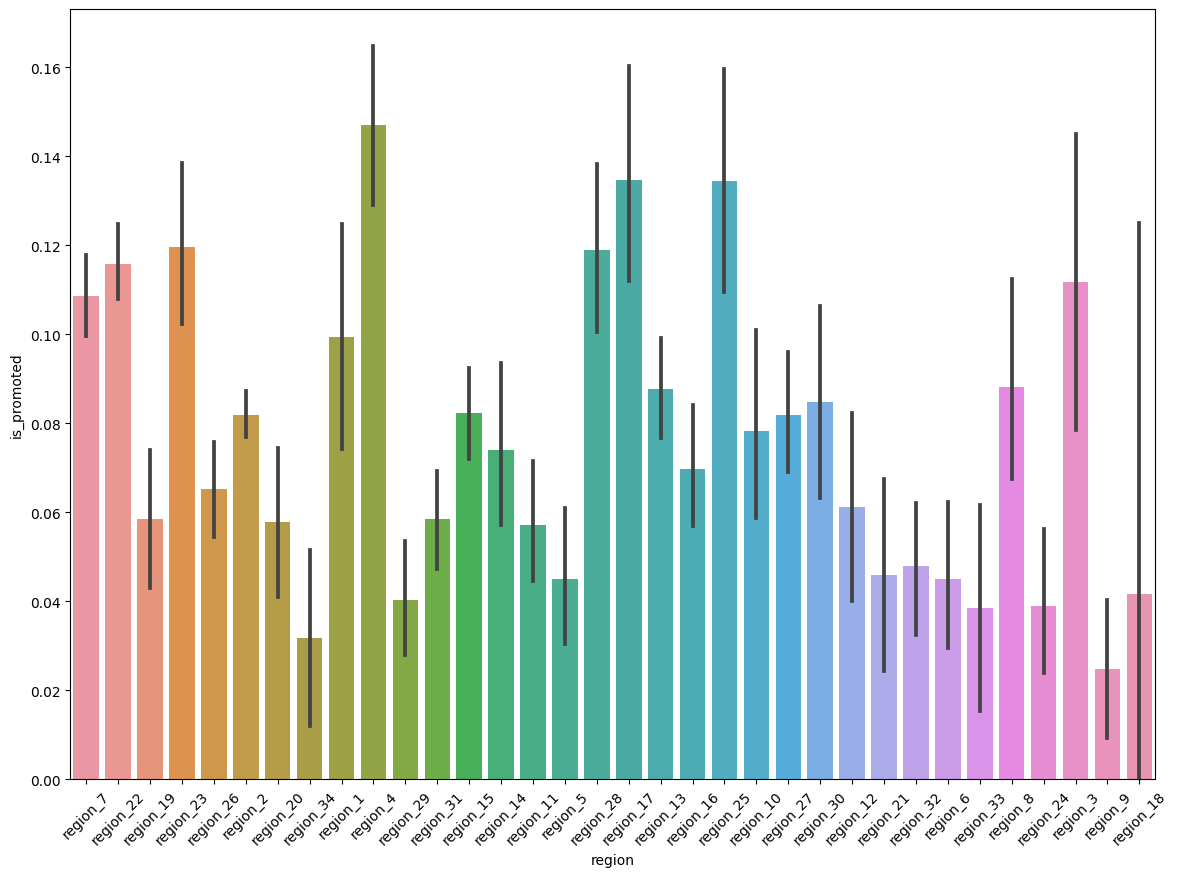
# 지역과 승진여부간의 상관관계 파악
plt.figure(figsize=(14,10))
sns.barplot(x='region', y='is_promoted', data=hr_df)
plt.xticks(rotation=45)
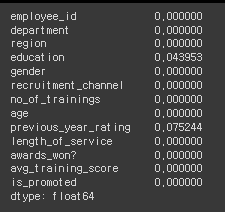
# null값의 존재여부 확인
hr_df.isna().mean()
# education, previous_year_rating에서 null값이 존재함
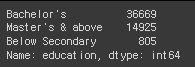
# education의 데이터 종류와 수
hr_df['education'].value_counts()
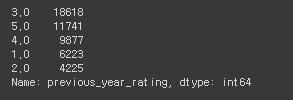
# previous_year_rating의 데이터 종류와 수
hr_df['previous_year_rating'].value_counts()
# null값을 모두 삭제
hr_df = hr_df.dropna()
hr_df.info()
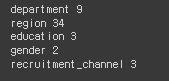
# object처리
# object 타입의 원핫인코딩 시 columns 수가 많아지는지의 여부를 체크
→ 많아지면 성능이 떨어질 가능성이 있으므로 미리 체크해 두는 것을 추천.
for i in ['department', 'region', 'education', 'gender', 'recruitment_channel']:
print(i, hr_df[i].nunique())
# 성능에 문제가 될 정도의 수치가 아니기 때문에 그대로 원핫인코딩을 진행할 예정.
# 원핫인코딩 실행
hr_df = pd.get_dummies(hr_df, columns=['department', 'region', 'education', 'gender', 'recruitment_channel'])
hr_df.head(3)

# columns을 59개에서 60개로 늘려주기
pd.set_option('display.max_columns', 60)
hr_df.head(3)

# 데이터 나누기에 필요한 train_test_split 불러오기
from sklearn.model_selection import train_test_split
# 데이터 나누기
X_train, X_test, y_train, y_test = train_test_split(hr_df.drop('is_promoted', axis=1), hr_df['is_promoted'], test_size=0.2, random_state=10)
7-2. 로지스틱 회귀(Logistic Regression)
둘 중의 하나를 결정하는 문제(이진 분류)를 풀기 위한 대표적 알고리즘.
로지스틱 회귀에 대한 사이킥런에서의 사용방법 및 문서 웹사이트.
sklearn.linear_model.LogisticRegression
Examples using sklearn.linear_model.LogisticRegression: Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.1 Release Highlights for scikit-learn 1.0 Release Highlights fo...
scikit-learn.org
* 3개 이상의 클래스에 대한 판별을 하는 경우:
OvR(On-versus-Rest), OvO(One-versus-One) 전략으로 판별.
OvR(One-vs-Rest): 클래스의 개수만큼의 이진 분류 문제를 생성하여 각 클래스를 다른 모든 클래스와 구분하도록 하는 방법. 예를 들어, 클래스 A, B, C가 있을 때, OvR은 A와 나머지 B, C를 구분하는 이진 분류 문제, B와 나머지 A, C를 구분하는 이진 분류 문제, C와 나머지 A, B를 구분하는 이진 분류 문제를 만들어 해결함. 이렇게 생성된 이진 분류 문제들을 모두 풀어서 가장 높은 확률을 가지는 클래스를 최종적으로 예측함. OvO(One-vs-One): 클래스의 개수에서 두 개의 클래스씩 짝을 지어 이진 분류 문제를 생성하는 방법. 예를 들어, 클래스 A, B, C가 있을 때, OvO는 A와 B를 구분하는 이진 분류 문제, A와 C를 구분하는 이진 분류 문제, B와 C를 구분하는 이진 분류 문제를 만들어 해결함. 이진 분류 문제들을 풀어 가장 많이 이긴 클래스를 최종적으로 예측함. 대부분 OvR 전략을 선호하지만, 데이터가 한쪽에 많이 치우친 경우 OvO를 사용함. |
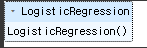
# 로지스틱 회귀를 import
from sklearn.linear_model import LogisticRegression
# LogisticRegression을 lr로 변수 설정
lr = LogisticRegression()
# 학습
lr.fit(X_train, y_train)
# 예측
pred = lr.predict(X_test)
# accuracy score를 import
from sklearn.metrics import accuracy_score, confusion_matrix
accuracy_score: scikit-learn 라이브러리에서 제공되는 함수로, 분류 모델의 성능을 평가하는 데 사용. 이 함수는 예측된 분류 레이블과 실제 레이블 사이의 일치도를 계산하여 모델의 정확도를 측정. 계산된 값은 0부터 1까지의 범위로, 1에 가까울수록 예측의 정확도가 높다는 것을 나타냄. |
# accuracy_score를 통해 학습된 예측의 정답률이 91%임을 확인.
accuracy_score(y_test, pred)

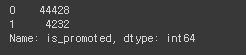
# is_promoted의 데이터 종류와 수
hr_df['is_promoted'].value_counts()
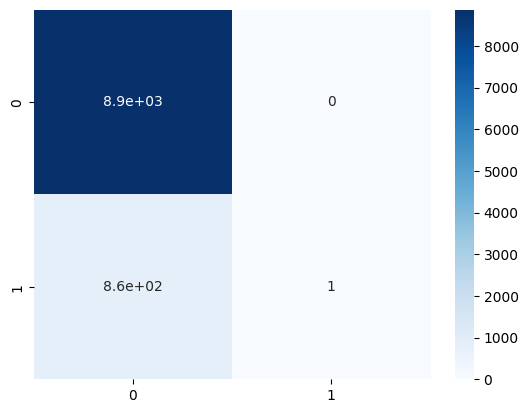
7-3. 혼돈행렬(Confusion Matrix)

accuracy score와 유사하게 분류 모델의 성능을 평가하기 위해 사용되는 표.
이 행렬은 실제 클래스와 예측된 클래스 사이의 관계를 나타냄.
* 정밀도와 재현율(민감도)을 활용하는 평가용 지수.
| TN (8869) | FP(0) |
| FN (862) | TP(1) |
* T: True, F: False, P: Positive, N: Negative
* TN: Negative로 예측, True인 경우(=승진하지 못했는데, 승진하지 못했다고 예측)
* FN: Negative로 예측, False인 경우(=승진하지 못했는데, 승진했다고 예측)
* FP: Positive로 예측, False인 경우(=승진했는데, 승진하지 못했다고 예측)
* TP: Positive로 예측, True인 경우(=승진했는데, 승진했다고 예측)
# confusion_matrix의 사용. 4가지 요소를 가진 행렬이 출력됨.
confusion_matrix(y_test, pred)
# confusion_matrix를 히트맵으로 표현
sns.heatmap(confusion_matrix(y_test, pred), annot=True, cmap='Blues') # Blues: Blue의 계열색들
7-3-1. 정밀도(precision)
* TP / (TP + FP)
* 모델이 양성으로 예측한 데이터 중에서 실제로 양성인 데이터의 비율을 계산.
* 실제 1인 것 중, 얼마만큼을 제대로 맞췄는지의 여부를 확인하는 퍼센티지
7-3-2. 재현율(recall)
* TP / (TP + FN)
* 실제로 양성인 데이터 중에서 모델이 양성으로 예측한 데이터의 비율을 계산.
* 1이라고 예측한 것 중, 얼마만큼을 제대로 맞췄는지의 여부를 확인하는 퍼센티지
* =민감도, =TPR(True Positive Rate)
7-3-3. F1 score
* 정밀도와 재현율의 조화평균을 나타내는 지표.

산술평균 (Arithmetic Mean): 산술평균은 주어진 데이터 집합의 값들을 모두 더한 후, 데이터의 개수로 나눈 값. 주로 데이터 집합의 중심 경향성을 나타내는 지표로 사용됨. 산술평균 = (데이터 값의 합) / (데이터의 개수) 예를 들어, [2, 4, 6, 8, 10]이라는 데이터가 주어진 경우, 데이터의 합은 2 + 4 + 6 + 8 + 10 = 30이고, 데이터의 개수는 5이다. 따라서 산술평균은 30 / 5 = 6이다. 조화평균 (Harmonic Mean): 조화평균은 주어진 데이터 집합의 역수들의 산술평균의 역수이다. 주로 비율과 비율의 평균을 구할 때 사용된다. 데이터 값들이 서로 반비례하는 경우에 유용하다. 조화평균 = (데이터의 개수) / (데이터 값의 역수들의 합) 예를 들어, [2, 4, 8]이라는 데이터가 주어진 경우, 데이터 값들의 역수는 1/2, 1/4, 1/8이며, 이들의 합은 1/2 + 1/4 + 1/8 = 7/8이다. 따라서 조화평균은 3 / (7/8) = 24/7 (약 3.43)이다. |
| 정밀도 | 재현율 | 산술평균 | 조화평균 |
| 0.4 | 0.6 | 0.5 | 0.48 |
| 0.3 | 0.7 | 0.5 | 0.42 |
| 0.5 | 0.5 | 0.5 | 0.5 |
# 위의 내용에 대한 모듈 import
from sklearn.metrics import precision_score, recall_score, f1_score
# y_test의 정밀도 예측
precision_score(y_test, pred)
# y_test의 재현율 예측
recall_score(y_test, pred)

# y_test의 f1 score 예측
f1_score(y_test, pred)

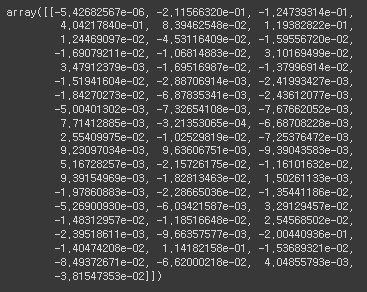
# 58개의 column에 대한 기울기
lr.coef_
X_train

# 독립변수 2개('age', 'length_of_service'), 종속변수 1개('is_promoted')를 선택
TempX = hr_df[['age', 'length_of_service']]
tempY = hr_df[['is_promoted']]
# 로지스틱회귀 객체 1개 더 생성
temp_lr = LogisticRegression()
# 학습
temp_lr.fit(TempX, tempY)
# age와 length_of_service로 dataFrame을 생성
temp_df = pd.DataFrame({'age':[20,27,30], 'length_of_service':[1,3,6]})
temp_df
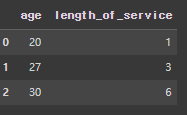
# 위의 3개가 승진이 가능한지를 예측 → 0,0,0이므로 승진을 할 수 없다고 예상함.
pred = temp_lr.predict(temp_df)
pred
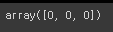
# 독립변수 2개('age', 'length_of_service')의 기울기
temp_lr.coef_

# 로지스틱회귀의 절편값.
# 절편은 모델의 기본 예측값이나 경향을 나타내는 상수.
로지스틱 회귀에서는 입력 변수에 따른 선형 결합에 절편을 더하여 로지스틱 함수를 적용하여 확률을 계산.
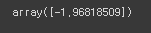
temp_lr.intercept_
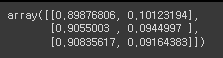
# proba: 위의 3줄에 대한 확률. (승진못할확률=0, 승진할확률=1)
# proba는 주로 다중 클래스 분류 문제에서 각 클래스에 속할 확률 값을 반환하며,
이를 기반으로 최종 클래스를 예측하거나 결정 경계를 그리는 등의 작업을 수행할 수 있음.
proba = temp_lr.predict_proba(temp_df)
proba
# 예: 0.89876806 -> 0일 확률 89.9%, 1일 확률 10.1%
7-4. 교차검증(Cross Validation)
train_test_split에서 발생하는 데이터의 섞임에 따라 성능이 좌우되는 문제를 해결하기 위한 기술.
K겹(K-fold) 교차 검증을 가장 많이 사용함.
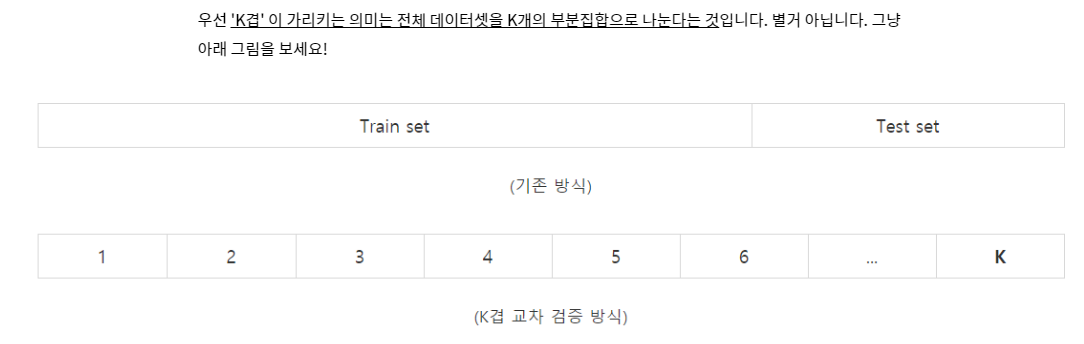
K-겹 교차 검증(K-fold cross-validation):
기계 학습 모델의 성능을 평가하기 위해 사용되는 일반적인 교차 검증 기법.
주어진 데이터를 K개의 폴드(또는 부분 집합)로 나눈 뒤, K번의 반복을 통해 모델을 학습하고 평가하는 과정.

K-겹 교차 검증의 작동 방식:
데이터를 K개의 동일한 크기로 분할.
모델을 K-1개의 폴드로 학습하고 나머지 1개의 폴드로 검증하여 이를 K번 반복.
각 반복에서 얻은 성능 지표(예: 정확도, 오차 등)를 기록하고, 이들을 평균하여 최종 성능 평가 지표를 계산.
K-겹 교차 검증은 일반화 능력을 평가하기 위해 사용되며, 과적합(overfitting)을 감지하거나 모델의 성능을
평가하는 데에도 유용함. 데이터를 K개의 폴드로 나누기 때문에, 모든 데이터를 효율적으로 활용하며,
일반화 성능을 더 정확하게 추정할 수 있음.
또한, 데이터셋에 대한 모델의 안정성을 평가할 수 있고, 편향된 모델 평가를 방지하는 데 도움을 줌.
일반적으로, K 값은 5 또는 10으로 선택되는 경우가 많음.
그러나 데이터의 크기와 특성에 따라 최적의 K 값은 달라질 수 있으며,
K-겹 교차 검증은 계산 비용이 높을 수 있으므로, 큰 데이터셋이나 복잡한 모델을 다룰 때 유의해야 함.
# kfold 모듈 import
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
kf
# random_state=None이고 shuffle=False이므로 random한 shuffle이 없는 상황
hr_df
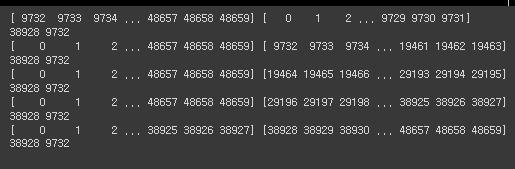
for train_index, test_index in kf.split(range(len(hr_df))):
# hr_df의 전체 data를 쪼갠 5개라는 갯수만큼 순회하면서 train_index, test_index를 출력
print(train_index, test_index)
print(len(train_index), len(test_index))
# data가 index 0~4까지 5개로 나누어져서 차례대로 분할된 상황.
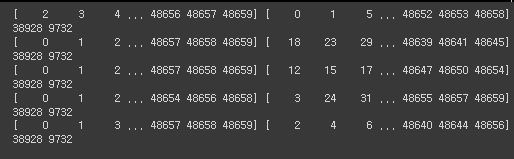
# 데이터를 shuffle함
kf = KFold(n_splits=5, random_state=10, shuffle=True)
kf

for train_index, test_index in kf.split(range(len(hr_df))): # 위와 달리 data가 shuffle된 것을 확인할 수 있음.
print(train_index, test_index)
print(len(train_index), len(test_index))
# 위의 내용과 동일하게 accuracy score를 통해 5바퀴를 순회하여 학습
acc_list=[ ]
for train_index, test_index in kf.split(range(len(hr_df))):
X = hr_df.drop('is_promoted', axis=1) # is_promoted를 제외하고 독립변수
y = hr_df['is_promoted'] # is_promoted를 종속변수
X_train = X.iloc[train_index]
X_test = X.iloc[test_index]
y_train = y.iloc[train_index]
y_test = y.iloc[test_index]
lr = LogisticRegression()
lr.fit(X_train, y_train)
pred=lr.predict(X_test)
acc_list.append(accuracy_score(y_test, pred))
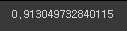
# 얼마만큼 잘 맞힐 수 있는지의 확률을 5개를 뽑아냄. (91.1% -> 90.9% -> 91.7% → 91.4% → 91.2%)
acc_list
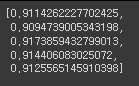
# 위의 5개 확률의 평균값
np.array(acc_list).mean()
8. 서포트 벡터 머신
8-1. 손글씨 데이터셋
from sklearn.datasets import load_digits
load_digits scikit-learn 라이브러리에서 제공하는 내장 데이터셋 중 하나로, 손으로 쓴 숫자 이미지 데이터셋이다. 이 데이터셋은 숫자 0부터 9까지의 손글씨 이미지를 포함하고 있으며, 각 이미지는 8x8 픽셀 크기로 구성되어 있다. load_digits 함수는 데이터셋을 로드하고 딕셔너리 형태로 반환하며, 다양한 정보가 포함되어 있다. load_digits 함수를 사용하여 데이터셋을 로드하고, 해당 데이터셋을 사용하여 숫자 인식과 같은 작업에 머신 러닝 모델을 훈련시킬 수 있다. |
# digits라는 매개변수 선언
digits = load_digits()
# digits의 key항목들
digits.keys()

data = digits['data']
data.shape
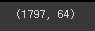
data[0]

target = digits['target']
target.shape # 1797개의 데이터
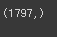
# matplotlib으로 출력
import matplotlib.pyplot as plt
# subplot으로 손글씨들을 출력
fig, axes = plt.subplots(2,5,figsize=(14,8))
for i, ax in enumerate(axes.flatten()): # flatten(): 다차원 배열을 1차원으로 평탄화해주는 함수.
ax.imshow(data[i].reshape((8,8)), cmap='gray')
ax.set_title(target[i])
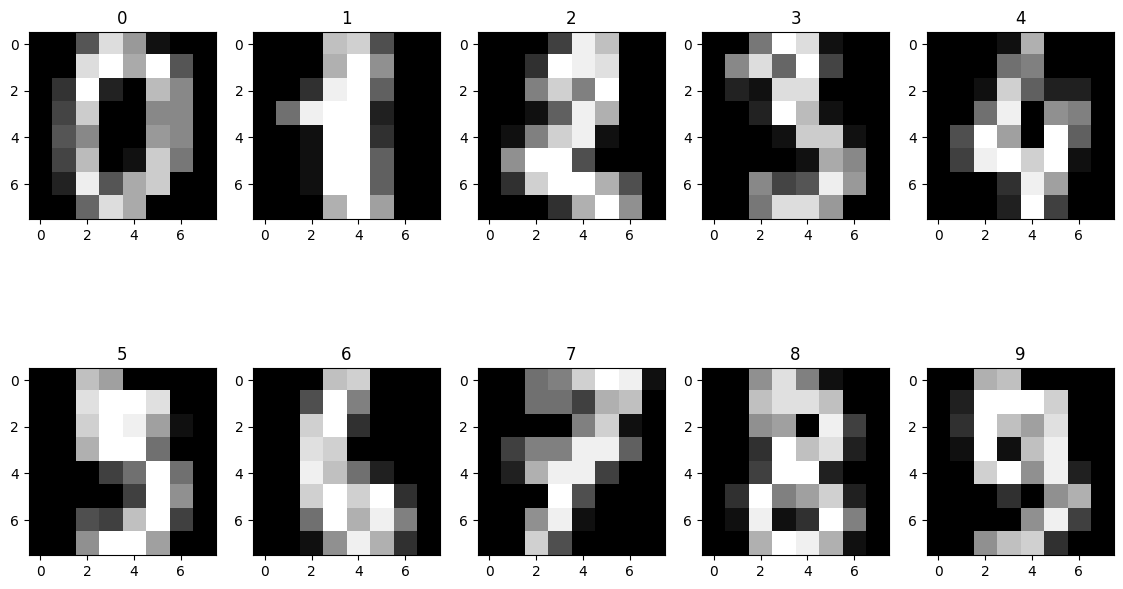
# fig: 화면 전체를 생성. axes: subplot를 2행 5열로 생성.
fig, axes = plt.subplots(2,5,figsize=(14,8))
print(fig)
print(axes)
8-2. 정규화(Normalization)
data[0]

from sklearn.preprocessing import MinMaxScaler
MinMaxScaler scikit-learn 라이브러리에서 제공하는 데이터 전처리(preprocessing) 도구 중 하나임. 이 클래스는 주어진 데이터를 최소-최대 스케일링(min-max scaling)을 사용하여 정규화(normalization)하는 데 사용됨. 최소-최대 스케일링은 데이터의 최소값과 최대값을 이용하여 데이터를 [0, 1] 범위로 변환하는 과정임. 이렇게 정규화된 데이터는 각각의 특성(feature)이 동일한 스케일을 가지게 되어, 다른 특성들 간의 크기 차이로 인한 문제를 완화시킴. MinMaxScaler는 다양한 머신러닝 모델에서 데이터 전처리 단계에서 활용되며, 특히 입력 데이터의 스케일이 중요한 모델(예: K-NN, 신경망 등)에서 유용함. 데이터의 스케일을 조정하여 모델의 학습을 개선하고, 데이터 특성들 간의 비교를 용이하게 함. |
scaler = MinMaxScaler()
# 모든 데이터를 0에서 1사이로 scaling
scaled = scaler.fit_transform(data)
scaled[0]
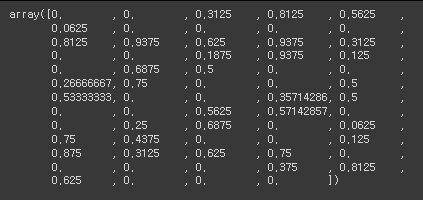
# 데이터셋의 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled, target, test_size=0.2, random_state=10)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# 1437과 360으로 나눠짐
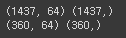
8-3. 서포트 벡터 머신(SVM)
지도학습 알고리즘 중 하나로, 주어진 데이터를 바탕으로 패턴 인식, 회귀 분석, 이상치 탐지 등
다양한 작업에 사용.
SVM은 데이터 포인트들을 고차원 공간으로 매핑(mapping)한 후,
이를 분리하는 최적의 초평면(hyperplane)을 찾는 것이 핵심 아이디어임.
SVM의 특징:
1) 마진 최대화(Maximum Margin):
SVM은 클래스를 구분하는 초평면을 찾을 때, 클래스 간의 거리(마진)를 최대화하도록 함.
이는 분류 경계를 더욱 일반화하고, 새로운 데이터에 대한 일반화 성능을 향상시키는데 도움을 줌.
2) 커널 트릭(Kernel Trick):
SVM은 비선형 분류 문제를 해결하기 위해 커널 트릭을 사용할 수 있음.
커널 함수를 이용하여 원래의 데이터를 고차원 특징 공간으로 변환함으로써,
비선형 문제를 선형 분류 문제로 해결할 수 있음.
3) 서포트 벡터(Support Vectors):
SVM은 결정 경계에 가장 가까운 일부 데이터 포인트들을 서포트 벡터라고 부름.
이 서포트 벡터들이 결정 경계를 구성하는데 중요한 역할을 하며,
학습된 SVM 모델의 일부만 사용하여 예측을 수행할 수 있음.
SVM은 이진 분류를 위한 모델로 시작되었지만, 다중 클래스 분류 문제에도 적용할 수 있음.
일대다(one-vs-rest) 또는 일대일(one-vs-one) 방법을 사용하여 다중 클래스 문제를 처리할 수 있음.
또한, SVM은 분류 뿐만 아니라 회귀 분석에도 사용될 수 있음.
서포트 벡터 회귀(Support Vector Regression, SVR)는 데이터 포인트들이 일정한 마진 내에서
회귀 함수와 가까워지도록 학습하는 방식임.
SVM은 다양한 분야에서 사용되며, 텍스트 분류, 이미지 분류, 이상치 탐지, 생물 정보학 등
다양한 문제에 적용될 수 있음.
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
model =SVC()
SVC(): 서포트 벡터 머신(Support Vector Machine, SVM)을 이용한 분류를 수행하는 클래스. scikit-learn 라이브러리에서 제공되는 지도학습 알고리즘 중 하나로, SVM의 분류 작업을 수행하는 모델을 구현한 것임. SVC는 SVM의 기본적인 개념과 원리를 기반으로 하며, 다양한 매개변수를 설정하여 모델의 성능과 일반화 능력을 조정할 수 있음. |
# 학습
model.fit(X_train, y_train)
# 예측값 확인
y_pred = model.predict(X_test)
# 정답률 98%임을 확인할 수 있음.
accuracy_score(y_test, y_pred)

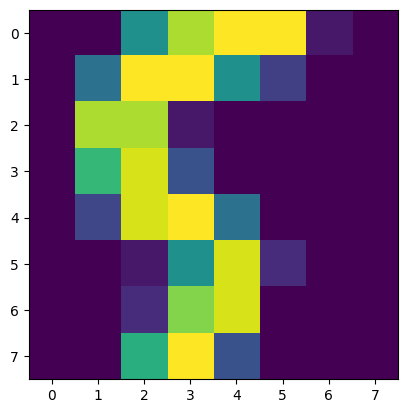
print(y_test[0], y_pred[0])
plt.imshow(X_test[0].reshape(8,8))
plt.show # 손글씨 5의 그림이 출력
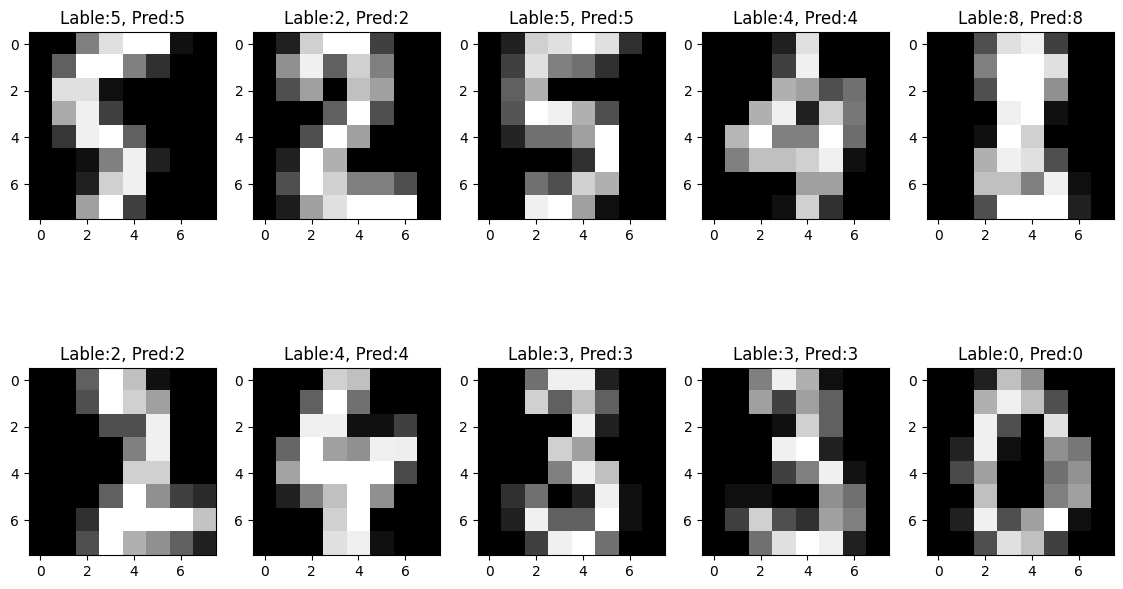
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,5, figsize=(14,8)) # 2행 5열크기의 subplot 생성
for i , ax in enumerate(axes.flatten()):
ax.imshow(X_test[i].reshape(8,8), cmap='gray')
ax.set_title(f'Lable:{y_test[i]}, Pred:{y_pred[i]}')
9. 랜덤 포레스트(Random Forest)

앙상블 학습(Ensemble Learning)의 일종으로, 의사결정 트리(Decision Tree)를 기반으로 한
분류 및 회귀 작업에 사용되는 알고리즘.
여러 개의 의사결정 트리를 조합하여 예측을 수행하고, 그 결과를 평균화하여 더 정확하고 안정적인 예측을 제공하는 것이 특징임.
랜덤 포레스트의 특징:
1) 의사결정 트리의 앙상블:
랜덤 포레스트는 여러 개의 의사결정 트리를 동시에 학습하고 예측에 사용함.
각각의 의사결정 트리는 독립적으로 학습되며, 병렬적으로 예측 결과를 생성함.
2) 부트스트랩 샘플링:
각 의사결정 트리를 학습하기 위해 부트스트랩 샘플링(Bootstrap Sampling)을 사용함.
이는 원본 데이터에서 복원 추출을 통해 샘플을 선택하는 방법으로, 각 의사결정 트리가 다른 데이터 부분 집합으로 학습되도록 함.
3) 랜덤한 특성 선택:
각 의사결정 트리가 분할을 결정할 때, 랜덤하게 일부 특성(feature)만을 고려함.
이는 트리들이 서로 다른 측면에서 데이터를 살펴보고 다양한 특성의 영향을 고려할 수 있도록 함.
4) 앙상블 예측:
모든 의사결정 트리의 예측 결과를 종합하여 최종 예측 결과를 만듦.
분류 작업의 경우, 각 트리의 예측을 투표하여 가장 많은 투표를 받은 클래스를 선택함.
회귀 작업의 경우, 각 트리의 예측 값을 평균하여 최종 예측 값을 구함.
랜덤 포레스트는 다양한 문제에 적용될 수 있으며, 특히 데이터의 특성을 고려하여 과적합(Overfitting)을 줄이고 일반화 성능을 향상시키는 데 도움이 됨.
또한, 변수의 중요도를 평가할 수 있어 특성 선택이나 변수 중요도 추정에 활용될 수 있음.
9-1. Hotel 데이터셋
Hotel 데이터셋 관련 내용 * hotel: 호텔종류 * is_canceled: 취소여부 * lead_time: 예약시점으로부터 체크인때까지의 기간 * arrival_date_year: 숙박년도 * arrival_date_month: 숙박월 * arrival_date_week_number: 숙박주 * arrival_date_day_of_month: 숙박일 * stays_in_weekend_nights: 주말포함숙박일 * stays_in_week_nights: 평일포함숙박일 * adults: 성인 수 * children: 어린이 수 * babies: 아기 수 * meal: 식사형태 * country: 지역 * distribution_channel: 예약경로 * is_repeated_guest: 이전예약여부 * previous_cancellations: 예약취소이력여부 * previous_bookings_not_canceled: 정상숙박이력여부 * reserved_room_type: 예약객실타입 * assigned_room_type: 배정객실타입 * booking_changes: 예약변경횟수 * deposit_type: 요금납부방식 * days_in_waiting_list: 대기일 * customer_type: 고객유형 * adr: 특정일의 가격 * required_car_parking_spaces: 주차공간요청여부 * total_of_special_requests: 별도요청사항여부 * reservation_status_date: 예약일자 * name: 이름 * email: 이메일 * phone-number: 휴대폰번호 * credit_card: 신용카드 |
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
hotel_df = pd.read_csv('/content/drive/MyDrive/K-DT/머신러닝과 딥러닝/hotel.csv')
▲ 위의 볼드체는 본인이 파일을 다운받은 경로를 입력
hotel_df
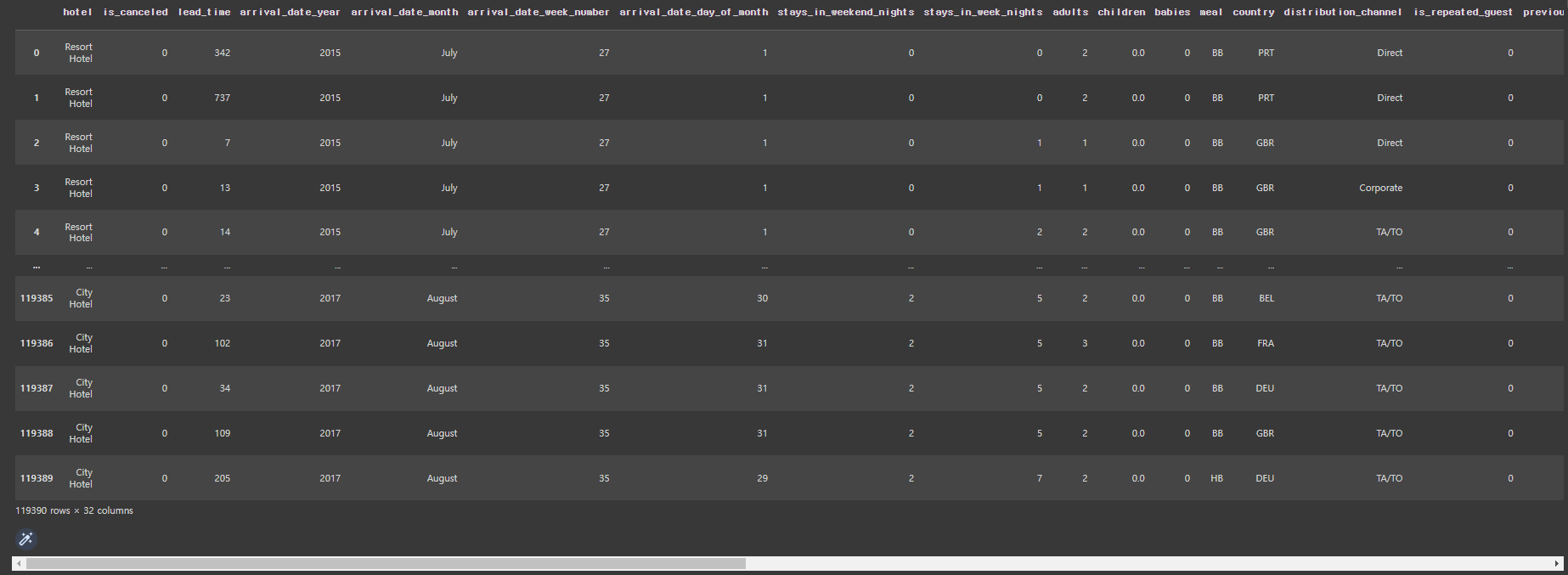
# 가로열은 생략없이 모두 펼쳐서 보기
pd.set_option('display.max_columns', 100)
hotel_df.head()

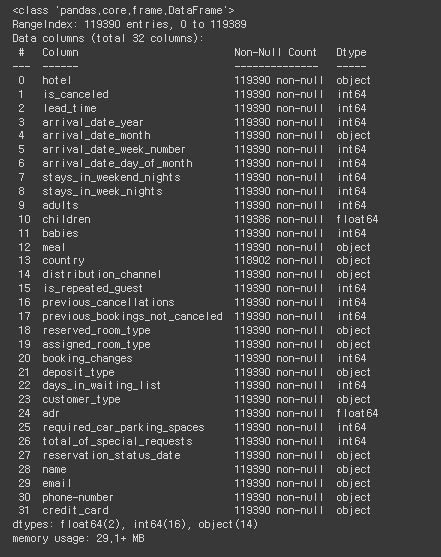
hotel_df.info()
# 삭제할 필드값 지정
hotel_df.drop(['credit_card', 'email', 'name', 'phone-number', 'reservation_status_date'], axis=1, inplace=True)
hotel_df.describe()

# lead_time에 대한 displot
sns.displot(hotel_df['lead_time'])
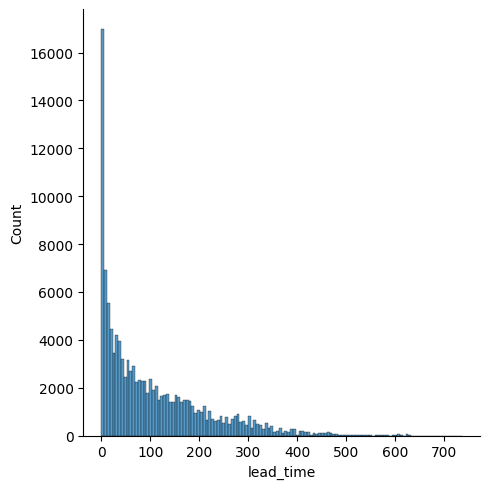
# lead_time에 대한 boxplot
sns.boxplot(hotel_df['lead_time'])

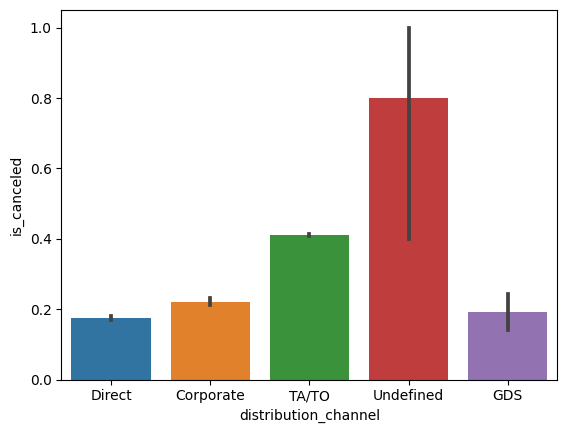
# distribution_channel,is_canceled 대한 barplot
sns.barplot(x= hotel_df['distribution_channel'],y=hotel_df['is_canceled'] )
# undefined의 data 수가 제일 적을 것이라 추정
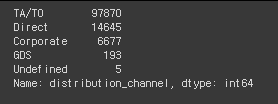
# value_counts확인 결과 Undefined의 수가 제일 적은 것이 맞음.
hotel_df['distribution_channel'].value_counts()
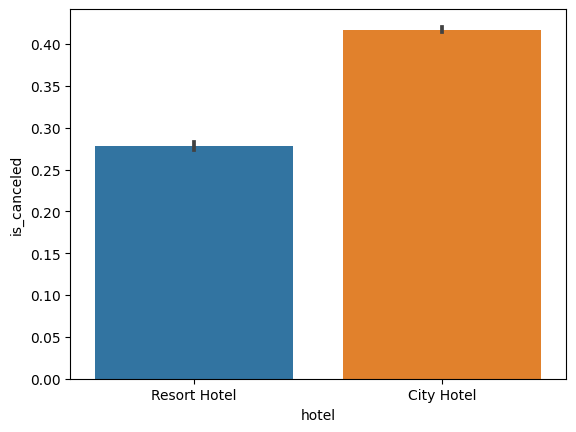
# hotel의 종류에 대한 취소율 barplot
sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
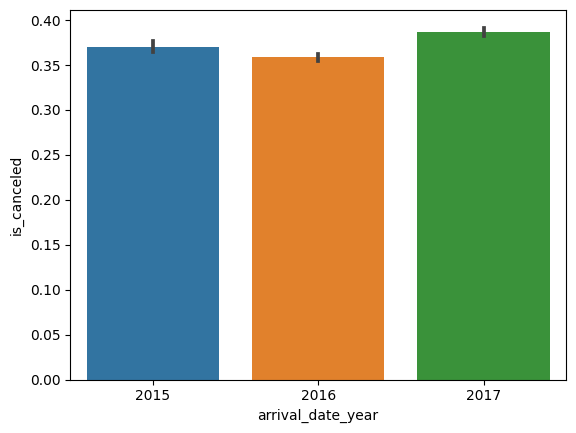
# 연도에 대한 취소율 barplot
sns.barplot(x=hotel_df['arrival_date_year'], y=hotel_df['is_canceled'])
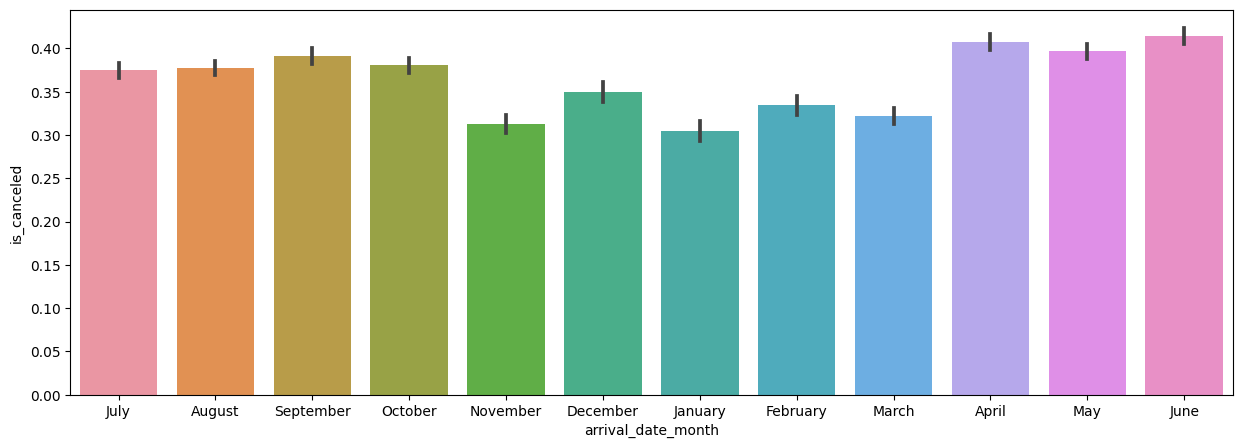
# 월에 대한 취소율 barplot
plt.figure(figsize=(15,5))
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'])
# 월이 정렬이 되어있지 않음.
# calendar 라이브러리 import
import calendar
# 해당 월에 대한 달의 이름이 출력
print(calendar.month_name[1])
print(calendar.month_name[2])
print(calendar.month_name[3])
# 전체 월의 출력
month = [ ]
for i in range(1,13):
month.append(calendar.month_name[i])
print(month)

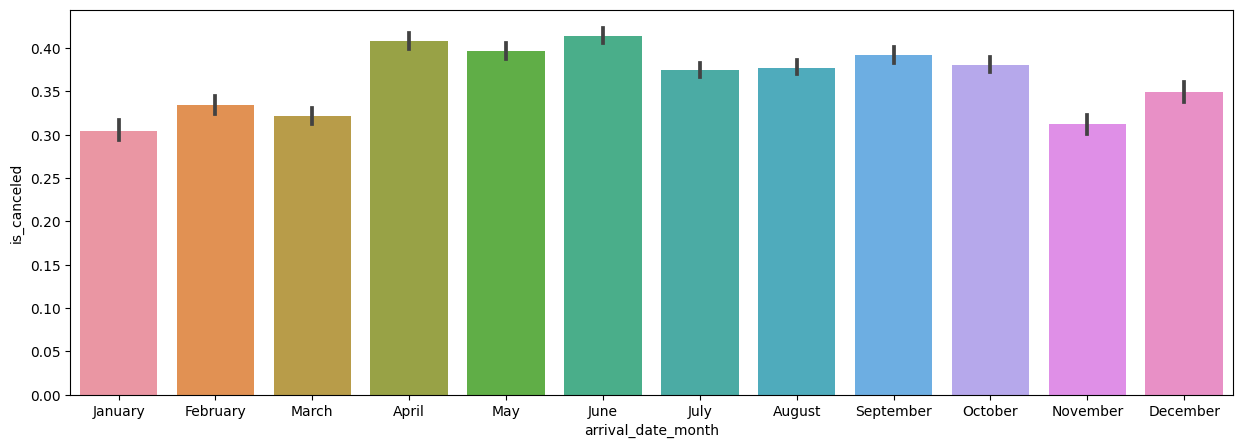
# 월에 대한 취소율 barplot (차례대로 정렬)
plt.figure(figsize=(15,5))
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'], order=month)
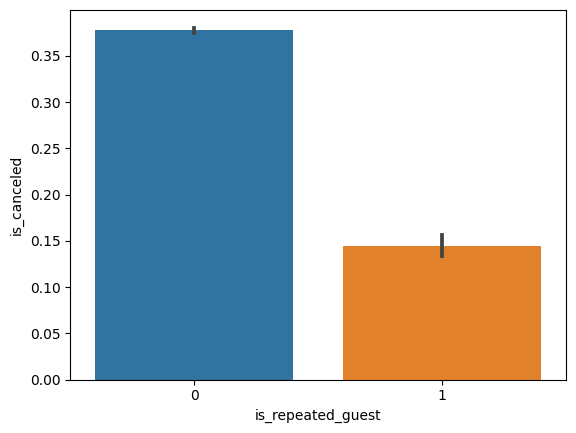
# 재예약여부에 따른 취소율 barplot
sns.barplot(x=hotel_df['is_repeated_guest'], y=hotel_df['is_canceled'])
# 결제유형에 따른 취소율 barplot
sns.barplot(x=hotel_df['deposit_type'], y=hotel_df['is_canceled'])
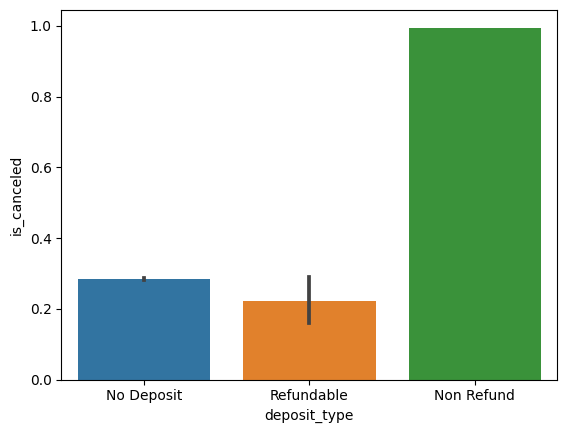
# 결제유형의 value_counts()
hotel_df['deposit_type'].value_counts()
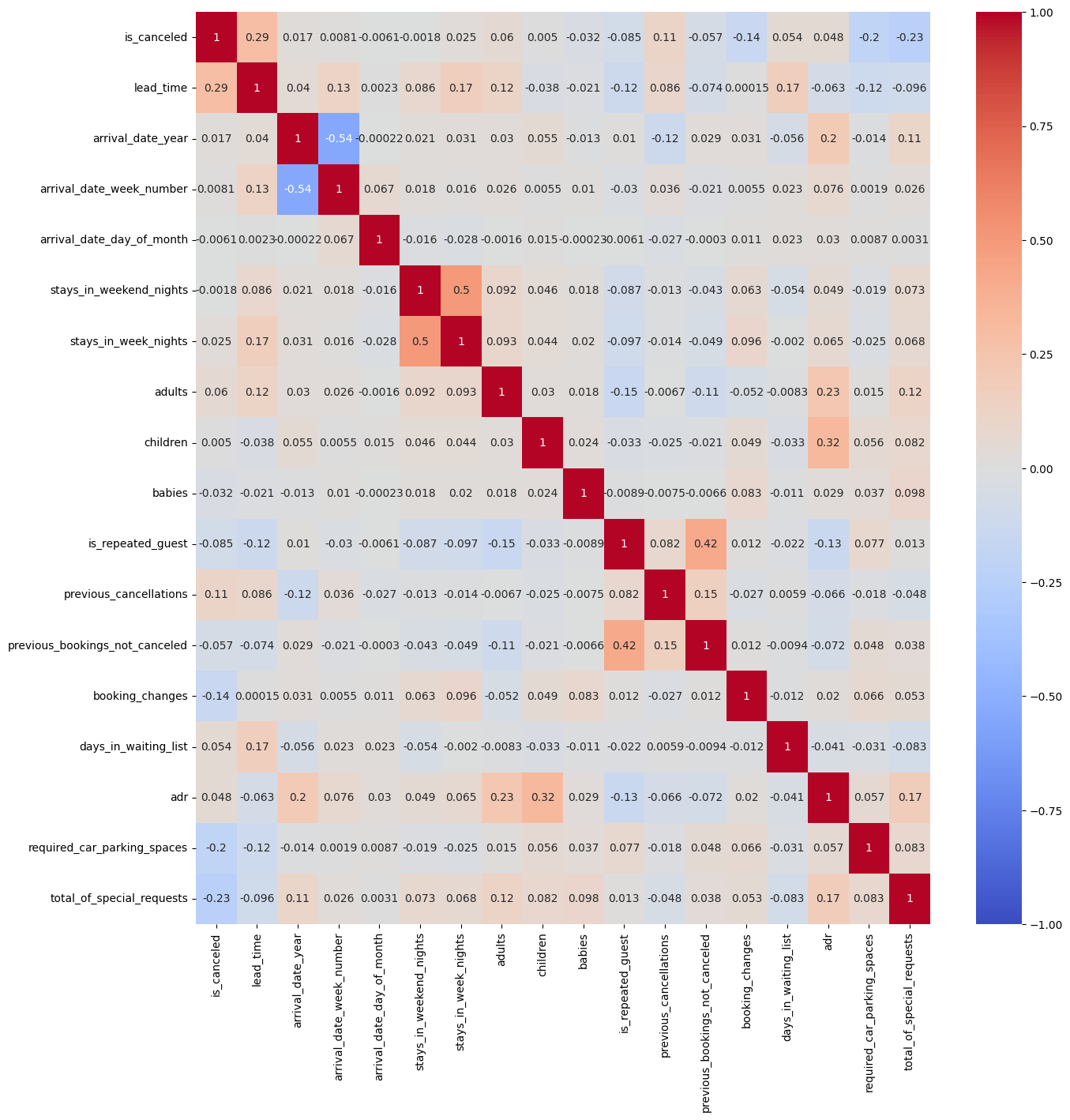
# 각 조건에 대한 전체 heatmap 그려보기
plt.figure(figsize=(15,15))
sns.heatmap(hotel_df.corr(), cmap='coolwarm', vmax=1, vmin=-1, annot=True)
# annot=True: 네모 박스 안에 숫자를 삽입
# 결측값 전체 삭제
hotel_df=hotel_df.dropna()
hotel_df.head()

# adult가 0인 data의 수
hotel_df[hotel_df['adults']==0] # 393개가 존재

# 파생변수 people을 새로 생성
hotel_df['people'] = hotel_df['adults']+hotel_df['children']+hotel_df['babies']
hotel_df.head()

# 파생변수 people의 수가 0인 경우는?
hotel_df[hotel_df['people']==0] #170명이 존재
# 파생변수 people의 수가 0인 경우를 모두 제외함
hotel_df = hotel_df[hotel_df['people']!=0]
hotel_df
# 파생변수 total_nights을 새로 생성
hotel_df['total_nights']=hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
hotel_df[hotel_df['total_nights']==0]
# 월을 묶어 계절로 만듦
hotel_df['arrival_date_month'].apply(lambda x: 'spring' if x in ['March', 'April', 'May'] else 'summer' if x in ['June', 'July', 'August'] else 'fall' if x in ['September', 'October','November'] else 'winter')
# 이렇게 작성할 수도 있음
season_dic ={'spring':[3,4,5], 'summer':[6,7,8], 'fall':[9,10,11], 'winter':[12,1,2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar.month_name[j]] = i
new_season_dic
# season이라는 파생변수를 생성
hotel_df['season']=hotel_df['arrival_date_month'].map(new_season_dic)
hotel_df.head()

# expected_room_type이라는 파생변수 생성 (reserved와 assigned가 동일할 경우 True, 아니면 False)
hotel_df['expected_room_type'] = hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']
hotel_df.head()




