
5.선형회귀
5-2. 선형 회귀(Linear Regression)
가장 널리 사용되는 회귀 분석 방법 중 하나. 데이터의 분포를 가장 잘 설명하는 직선을 찾아내는 방법.
* 단순 선형 회귀 분석: 단일 독립변수를 이용.

* 다중 선형 회귀 분석: 다중 독립변수를 이용.

# 선형회귀와 관련된 모듈
from sklearn.linear_model import LinearRegression
# lr이라는 선형회귀의 객체 생성
lr = LinearRegression()
# 학습
lr.fit(X_train, y_train)

# X_test를 입력했을 때의 예측결과 출력
pred = lr.predict(X_test)
5-3. 평가지표 만들기
5-3-1. MSE(평균제곱근오차. Mean Squared Error)
예측값과 실제값의 차이의 제곱의 평균값

p = np.array([3,4,5]) # 예측값
act = np.array([1,2,3]) # 실제값. 예측값과의 오차가 존재함.
def my_mse(pred, actual):
return ((pred-actual)**2).mean()
my_mse(p, act)

5-3-2. MAE(평균절대값오차. Mean Absolute Error)
예측값과 실제값의 차이의 절대값의 평균값
MSE에 비해 잘 사용되지는 않음.

p = np.array([3,4,5]) # 예측값
act = np.array([1,2,3]) # 실제값. 예측값과의 오차가 존재함.
def my_mae(pred, actual):
return np.abs(pred-actual).mean()
my_mae(p, act)

5-3-3. RMSE(Root Mean Squared Error)
예측값과 실제값의 차이의 제곱의 평균의 제곱근값
=MSE의 제곱근값

p = np.array([3,4,5]) # 예측값
act = np.array([1,2,3]) # 실제값. 예측값과의 오차가 존재함.
def my_rmse(pred, actual):
return np.sqrt(my_mse(pred, actual))
my_rmse(p, act)

# mse, mae의 기능을 모듈을 통해 바로 불러오기
from sklearn.metrics import mean_absolute_error, mean_squared_error
# rmse는 직접 불러오는 방법은없음.
# mae 메서드 사용
mean_absolute_error(p,act)

# mse 메서드 사용
mean_squared_error(p,act)

# mse 메서드를 사용하여 rmse를 구하는 방법
mean_squared_error(p,act, squared=False)

5-3-4. 평가지표의 적용
# rent 데이터셋에서 이어짐.
# mse를 이용하여 pred값에 대한 오차를 확인.
mean_squared_error(y_test,pred)

# mae를 이용하여 pred값에 대한 오차를 확인.
mean_absolute_error(y_test,pred)

# rmse를 통해 pred값에 대한 오차를 확인.
mean_squared_error(y_test, pred, squared=False)

# rent 데이터셋에 존재하는 이상값에 대한 평가지표를 적용해보기
→ 이상값이 사라질 때 오차가 감소하는지의 여부 확인
# 1837번 이상치를 삭제하여 적용
X_train.drop(1837, inplace=True)
y_train.drop(1837, inplace=True)
# 다시 학습
lr.fit(X_train, y_train)

# 다시 예측선 그리기
pred = lr.predict(X_test)
# rmse를 통해 오차값을 확인
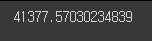
mean_squared_error(y_test, pred, squared=False)
# 1837번 이상치를 삭제함으로써 기존의 rmse의 값(41438.9403701652)에 대한 현재 값(41377.57030234839)과의 차이가 발생 → 오차가 감소함.
5-4. log의 활용
오차를 줄이는 또 하나의 방법.
a = [1,2,3,4,5]
b = [1,10,100,1000,10000]
# a와 b를 x와 y축으로 하여 그래프 작성
sns.lineplot(x=a, y=b)

# log()함수를 이용하여 b의 log값을 구함
b_log = np.log(b)
b_log

# exp()함수를 이용하여 log값을 다시 원래대로 변환
np.exp(b_log) # exp(): 지수함수로 변환시켜주는 함수.

# 곡선의 생성
y_train_log = np.log(y_train)
# X_train과 y_train_log로 학습
lr.fit(X_train, y_train_log)

# 예측
pred = lr.predict(X_test)
# 평가지표 이용
mean_squared_error(y_test,pred, squared=False)
# log를 사용하여 곡선으로 설정 후 오차값을 비교했을 때, 오차의 값이 훨씬 커짐.
→ 해당 data는 곡선형이 아니라 선형이라는 것을 추측할 수 있음.

1837 data를 삭제하기 전 RMSE: 41438.9403701652
1837 data를 삭제한 후 RMSE: 41377.57030234839
log를 사용하여 비선형으로 변경한 후 RMSE: 70418.55375574114
→ data의 분포가 비선형일 때 로그를 사용하는 것이 오차가 적으며,
반대로 선형일 때 로그를 사용하지 않는 것이 오차가 적다는 것을 알 수 있음.
6. 의사결정나무
6-1. bike 데이터셋
bike 데이터셋 관련 내용 * datetime: 날짜 * count: 대여 개수 * holiday : 휴일 * workingday: 근무일 * temp: 기온 * feel_like: 체감온도 * temp_min: 최저온도 * temp_max: 최고온도 * pressure: 기압 * humidity: 습도 * wind_speed: 풍속 * wind_deg: 풍향 * rain_1h: 시간당 내리는 비의 양 * snow_1h: 시간당 내리는 눈의 양 * clouds_all: 구름의 양 * weather_main: 날씨 |
# 필요한 라이브러리를 import
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 다운로드받은 bike.csv 파일을 불러오기
bike_df = pd.read_csv('/content/drive/MyDrive/K-DT/머신러닝과 딥러닝/bike.csv')
▲ 위의 볼드체는 본인이 파일을 다운받은 경로를 입력
bike_df

bike_df.info()

# 'rain_1h'와 'snow_1h' 필드값에 결측치가 존재.
일반적으로 눈과 비가 오지 않은날은 0이기 때문에 해당 필드값에는 null값이 존재해야 함.
bike_df.describe()

# count에 대한 displot 그리기
sns.displot(bike_df['count'])

# count에 대한 boxplot 그리기
sns.boxplot(y=bike_df['count'])

# '체감온도'에 따른 자전거 대여 수를 점그래프로 그리기
sns.scatterplot(x='feels_like', y='count', data=bike_df, alpha=0.3)

# '기압'에 따른 자전거 대여 수를 점그래프로 그리기
sns.scatterplot(x='pressure', y='count', data=bike_df, alpha=0.3)

# '풍속'에 따른 자전거 대여 수를 점그래프로 그리기
sns.scatterplot(x='wind_speed', y='count', data=bike_df, alpha=0.3)

# '풍향'에 따른 자전거 대여 수를 점그래프로 그리기
sns.scatterplot(x='wind_deg', y='count', data=bike_df, alpha=0.3)

# 데이터의 결측치 확인
bike_df.isna().sum()
# 눈, 비의 data에만 결측치가 있음을 확인.

# 데이터의 결측치 퍼센티지 확인
bike_df.isna().mean()

# 결측치를 모두 0으로 채움
bike_df = bike_df.fillna(0)
# 다시한번 결측치 확인 → 이번에는 결측치가 없는 것을 알 수 있음.
bike_df.isna().mean()

bike_df.info()

# dtype이 object형인 것을 바꾸어 줄 필요가 있음. (예: datetime)
# datetime을 사계절로 바꾸어 줄 예정.
# 먼저 datetime의 type을 datetime으로 변경해줌
bike_df['datetime'] = pd.to_datetime(bike_df['datetime'])
bike_df.info()

# bike_df의 연도, 월, 일, 시간을 추출하여 파생변수로 만들 예정
bike_df['year'] = bike_df['datetime'].dt.year
bike_df['month'] = bike_df['datetime'].dt.month
bike_df['date'] = bike_df['datetime'].dt.date
bike_df['hour'] = bike_df['datetime'].dt.hour
bike_df.head()

plt.figure(figsize=(14,4))
sns.lineplot(x='date', y='count', data=bike_df)
plt.xticks(rotation=45)
plt.show()
# 20년 4~5월의 부분의 line이 부자연스러움 → data가 없다는 의미.

# 부자연스러운 데이터의 확인
# 정상적인 구간을 그룹화 (2019년을 월로 묶어서 count의 평균 구하기)
bike_df[bike_df['year']==2019].groupby('month')['count'].mean()

# 위의 연도와 비교하여 2020년도의 구간을 그룹화 → 4월이 없음.
bike_df[bike_df['year']==2020].groupby('month')['count'].mean()

# covid의 이슈에 따른 구간을 나누는 함수 생성
# 2020-04-01 이전: precovid
# 2021-04-01 이전: covid
# 나머지 이후일자: postcovid
def covid(date):
if str(date) < "2020-04-01":
return "precovid"
elif str(date) < "2021-04-01":
return "covid"
else:
return "postcovid" bike_df['date'] < '2020-04-01' # date는 series인데, 이런식으로 비교를 한다면 에러가 발생함. covid(bike_df['date']) <'2020-04-01' # 이것도 1개만 불러오기 때문에 올바른 형태가 아님.
bike_df['date'].apply(covid) # 올바른 방법. DataFrame의 형태로 사용해야 함.

# lambda함수를 이용한 covid 파생변수 생성. (if, else if, else 3개가 있을 때의 한줄 사용법.)
bike_df['covid'] = bike_df['date'].apply(lambda date: 'precovid' if str(date) < '2020-04-01' else 'covid' if str(date) < '2021-04-01' else 'postcovid')
bike_df.head()

# season 파생변수 생성. (3~5월 봄, 6~8월 여름, 9~11월 가을, 12~2월 겨울)
bike_df['season'] = bike_df['month'].apply(lambda x: 'winter' if x == 12 else 'fall' if x >= 9 else 'summer' if x>=6 else 'spring' if x>=3 else 'winter')
bike_df[['month', 'season']]
# day_night 파생변수 생성.
bike_df['day_night'] = bike_df['hour'].apply(lambda x: 'night' if x>=21 else 'late evening' if x>=19 else 'early evening' if x>=17 else 'late afternoon' if x>=16 else 'early afternoon' if x>=13 else 'late morning' if x>=11 else 'early morning' if x>=5 else 'night')
bike_df[['day_night']]

# 필요없는 필드값의 열은 삭제
bike_df.drop(['datetime', 'month', 'date', 'hour'], axis=1, inplace=True)
bike_df.head()

bike_df.info()
# weather_main을 살펴볼 예정

# 해당 필드값의 열들이 종류가 몇개인지 확인
for i in ['weather_main', 'covid', 'season', 'day_night']:
print(i, bike_df[i].nunique())

# weather_main의 열의 종류가 어떤것인지 확인
bike_df['weather_main'].unique()

plt.figure(figsize=(10,5))
sns.boxplot(x='weather_main', y='count', data=bike_df)

# 'weather_main', 'covid', 'season', 'day_night'를 모두 원핫인코딩 해줄 예정
bike_df = pd.get_dummies(bike_df, columns=['weather_main', 'covid', 'season', 'day_night'])
bike_df.head()

# 생략된 열을 모두 보이게 하기
pd.set_option('display.max_columns', 45)
bike_df.head()

# 데이터 쪼개기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(bike_df.drop('count', axis=1), bike_df['count'], test_size=0.2, random_state=10)
print(X_train.shape, X_test.shape)
6-2. 의사결정나무 (Decision Tree)

데이터를 분류(classification)하거나 예측(regression)하는 데 사용되는 지도 학습 알고리즘.
'트리 구조'를 사용하여 데이터의 특징과 목표 변수 간의 관계를 모델링함.
이해하기 쉽고 해석이 용이하며, 다양한 종류의 데이터에 적용할 수 있는 강력한 기계 학습 알고리즘.
의사결정나무는 데이터를 분할하는 분할 규칙을 기반으로 트리를 구성함.
각 분할은 독립 변수의 값을 사용하여 목표 변수를 예측하기 위해 최적화됨.
트리의 맨 위에는 루트 노드(root node)가 있으며, 루트 노드에서 시작하여 가지(branch)로 분할되며,
리프 노드(leaf node)에 도달할 때까지 분할이 반복됨.
특징
1) 분할 기준:
데이터를 분할하는 기준은 정보 이득(information gain), 지니 불순도(Gini impurity) 등과 같은 지표를
사용하여 결정됨. 이 기준은 분할 후의 순도가 증가하거나 불순도가 감소하는 방향으로 분할을 진행함.
2) 과적합 방지:
의사결정나무는 데이터에 과도하게 적합될 수 있는 경향이 있음.
따라서 가지치기(pruning) 또는 최대 깊이(maximum depth), 최소 샘플 수(minimum samples per leaf) 등과
같은 매개변수를 사용하여 과적합을 방지할 수 있음.
3) 해석 가능성:
의사결정나무는 트리의 구조를 시각화하여 해석 가능한 결과를 제공.
각 분할은 조건문으로 표현되므로 모델의 결정 과정을 이해하기 쉬움.
의사결정나무는 분류 문제와 회귀 문제에 모두 사용될 수 있으며,
다른 알고리즘과 결합하여 앙상블 학습(ensemble learning) 방법인 랜덤 포레스트(Random Forest)와
그래디언트 부스팅(Gradient Boosting) 등에 활용될 수 있음.
# 의사결정나무 모듈 불러오기
from sklearn.tree import DecisionTreeRegressor
dt = DecisionTreeRegressor(random_state=10)
# random_state: 하이퍼 파라미터. 계속 값을 유지시켜주는 역할.
# 학습
dt.fit(X_train, y_train)

# 예측
dt.predict(X_test)
pred1 = dt.predict(X_test)
sns.scatterplot(x=y_test, y=pred1) # x는 정답, y는 예측

from sklearn.metrics import mean_squared_error
# 오차율 확인
mean_squared_error(y_test, pred1, squared=False)

6-3. 선형회귀 vs 의사결정나무
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)

pred2 = lr.predict(X_test)
# 선형회귀 모델로 교육을 하였을 때 점그래프를 확인해본 결과 오차가 의사결정나무 모델보다 큰 걸로 추정.
sns.scatterplot(x=y_test, y=pred2)

# 오차율 확인 (실제로는 선형회귀모델의 오차가 더 작음)
mean_squared_error(y_test, pred2, squared=False)

# 하이퍼 파라미터 적용
하이퍼파라미터(Hyperparameter): 머신 러닝 알고리즘의 동작을 제어하고 조정하는 매개변수. 하이퍼파라미터는 모델의 학습 과정에 직접적으로 영향을 주는 변수이며, 모델의 성능, 학습 속도, 과적합 등을 조절하는 데 사용됨. 하이퍼파라미터는 사용자가 직접 설정해야 하는 값으로, 일반적으로 모델을 훈련하기 전에 결정됨. 이와 달리, 모델의 가중치와 편향과 같은 파라미터는 모델 자체에서 학습 과정을 통해 조정됨. 하이퍼파라미터의 선택은 모델의 성능과 일반화 능력에 큰 영향을 미침. 잘 조정된 하이퍼파라미터는 모델의 성능을 향상시키고, 과적합을 방지하며, 더 빠른 학습을 가능하게 함. 하지만 최적의 하이퍼파라미터를 찾는 것은 문제에 따라 어려울 수 있으며, 대부분은 실험과 검증을 통해 조정됨. 일반적으로 사용되는 하이퍼파라미터의 종류: 학습률(learning rate): 경사하강법과 같은 최적화 알고리즘에서 가중치 업데이트 시 적용되는 스텝의 크기를 조절하는 파라미터. 에포크(epoch): 전체 데이터셋을 몇 번 반복해서 학습할지를 결정하는 파라미터. 배치 크기(batch size): 한 번의 반복에서 사용되는 데이터의 샘플 개수를 결정하는 파라미터. 은닉층의 개수와 유닛 수: 신경망 모델에서 사용되는 은닉층의 개수와 각 은닉층의 유닛 수를 조절하는 파라미터. 규제화(Regularization) 관련 파라미터: 모델의 복잡성을 제어하고 과적합을 방지하기 위해 사용되는 파라미터. (예: L1 규제 또는 L2 규제의 강도를 조절하는 하이퍼파라미터가 있음.) 커널 함수와 감마 값: 커널 서포트 벡터 머신(SVM)과 같은 모델에서 사용되는 커널 함수와 감마 값을 조정하는 파라미터. 하이퍼파라미터 튜닝은 일반적으로 그리드 서치(Grid Search)나 랜덤 서치(Random Search)와 같은 기법을 사용하여 수행됨. 이러한 기법을 통해 다양한 하이퍼파라미터 조합을 시도하고, 검증 데이터를 통해 모델의 성능을 평가하여 최적의 하이퍼파라미터 조합을 찾게 됨. |
dt = DecisionTreeRegressor(random_state=10, max_depth=50, min_samples_leaf=30)
# max_depth=50: 트리의 최대 깊이를 지정하는 매개변수. 트리의 깊이는 트리가 얼마나 복잡한 결정 경계를
학습할 수 있는지를 결정함. 이 값은 50으로 설정되어 있으므로 트리의 최대 깊이는 50임.
# min_samples_leaf=30: 리프 노드에 포함되어야 하는 최소 샘플 수를 지정하는 매개변수.
이 값은 30으로 설정되어 있으므로 리프 노드에는 적어도 30개의 샘플이 있어야 함.
dt.fit(X_train, y_train)

pred3 = dt.predict(X_test)
mean_squared_error(y_test, pred3, squared=False) # 오차율이 확 줄어듦 → 성능이 확실히 좋아짐.

# 의사결정나무 하이퍼파라미터 튜닝 RMSE: 187.3015148952268
# 선형회귀모델 RMSE: 228.26128192004947
# 의사결정나무 RMSE: 228.42843328100884
from sklearn.tree import plot_tree
plt.figure(figsize=(24,12))
plot_tree(dt, max_depth=5, fontsize=12)
plt.show()

# 한 눈으로 보기 좋게 편집
plt.figure(figsize=(24,12))
plot_tree(dt, max_depth=5, fontsize=12, feature_names=X_train.columns)
plt.show()
# 아래 그림에서 보면 day_night_night가 가장 영향력이 큰 필드인 것을 확인할 수 있음.




