
1. 크롤링(Crawling)
데이터 크롤링(Data Crawling)
자동화된 방식으로 웹 페이지를 탐색하고, 필요한 데이터를 수집하는 프로세스를 의미.
크롤러(또는 스파이더, 로봇)라고 불리는 프로그램이 웹 페이지를 방문하며,
링크를 따라 이동하고 페이지의 내용을 분석하여 정보를 추출 → 웹 상의 다양한 데이터를 수집할 수 있음.
예를 들어, 뉴스 기사, 제품 정보, 사용자 리뷰, 소셜 미디어 게시물 등을 크롤링할 수 있음.
데이터 스크래핑(Data Scraping)
크롤링 과정에서 수집한 데이터 중에서 필요한 부분을 추출하는 작업을 의미.
크롤링은 웹 페이지를 탐색하고 데이터를 수집하는 것에 비해,
스크래핑은 수집한 데이터에서 원하는 정보를 추출하는 작업임.
스크래핑은 데이터를 정제하고 구조화하여 다양한 형식으로 저장하거나 분석에 활용할 수 있음.
예를 들어, 크롤링한 웹 페이지에서 제목, 작성자, 게시일 등의 정보를 추출하여 데이터베이스에 저장하거나 분석을 위한 CSV 파일로 변환할 수 있음.
크롤링과 스크래핑은 다양한 목적과 도구를 사용하여 수행될 수 있음.
일부 프로그래밍 언어(Python)와 라이브러리(BeautifulSoup, Scrapy)는 이들을 구현할 수 있는 도구를 제공.그러나 크롤링과 스크래핑을 수행할 때에는 웹 사이트의 이용 약관과 법적 제약 사항을 준수해야 함.
1-1. 영단어 데이터 크롤링
import requests
from bs4 import BeautifulSoup # BeautifulSoup: Markup언어를 parsing하는 것을 도와주는 라이브러리
site = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
request = requests.get(site) # get방식으로 site에 접속
print(request) # request를 print하는 경우, 200이나 404와 같은 응답코드를 출력함
# print(request.text)
soup = BeautifulSoup(request.text) # HTML의 parsing을 도움
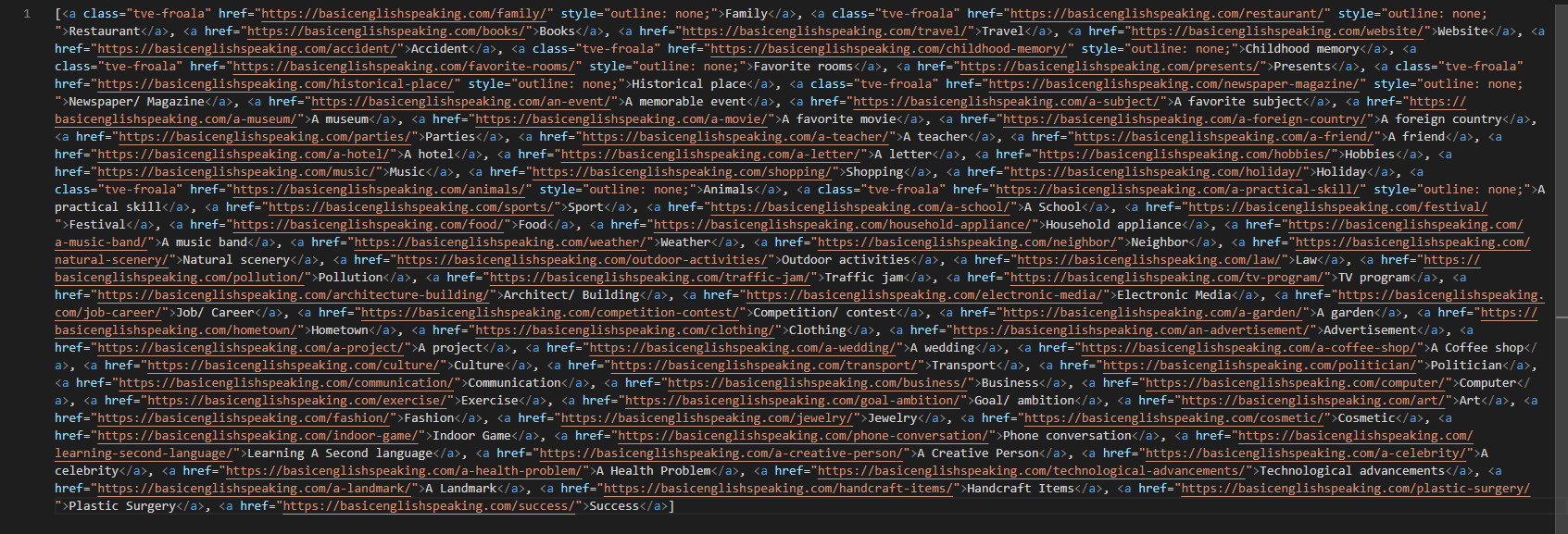
'Family'라는 단어를 가져오고 싶은 경우, 개발자모드 파란색 블록에 위치한 해당 내용을 추출해와야 함.
div의 범위를 설정하여 내부에서만 anchor태그를 추출해오는 것을 추천함.
설정할 div의 범위는 아래와 같음.
div 태그 안의 내용을 가져옴
divs = soup.find('div', {'class':'thrv-columns'}) # soup.find(): 단일 태그를 가져오는 함수.
print(divs)
a 태그만 추출해옴
links = divs.findAll('a') # a 태그를 찾음
print(links)
text로 변환
for link in links:
print(link.text) # links 안의 link에서의 text만 볼 예정

적당히 가공하는 작업을 거침
subject = []
for link in links:
subject.append(link.text)
len(subject)
print('총', len(subject), '개의 주제를 찾았습니다')
for i in range(len(subject)):
print('{0:2d}. {1:s}'.format(i+1, subject[i]))
# 0:2d: 0번자리인 i+1에 2자리의 decimal / # 1:s: 1번자리인 subject[i]에 string

1-2. 기사제목 데이터 크롤링
각 기사 URL의 뒷부분 숫자를 이용해서 기사 제목을 가져오려는 경우
예시 기사)
https://v.daum.net/v/20230601070358358
https://v.daum.net/v/20230601072518640
다음 뉴스의 제목을 추출해주는 crawling 함수를 만듦.
def daum_news_title(new_id):
url = 'https://v.daum.net/v/{ }'.format(new_id)
request = requests.get(url)
soup = BeautifulSoup(request.text)
title = soup.find('h3', {'class':'tit_view'})
if title:
return title.text.strip()
return '제목없음'
====================================================
daum_news_title(20230601070358358)
daum_news_title(20230601072518640)
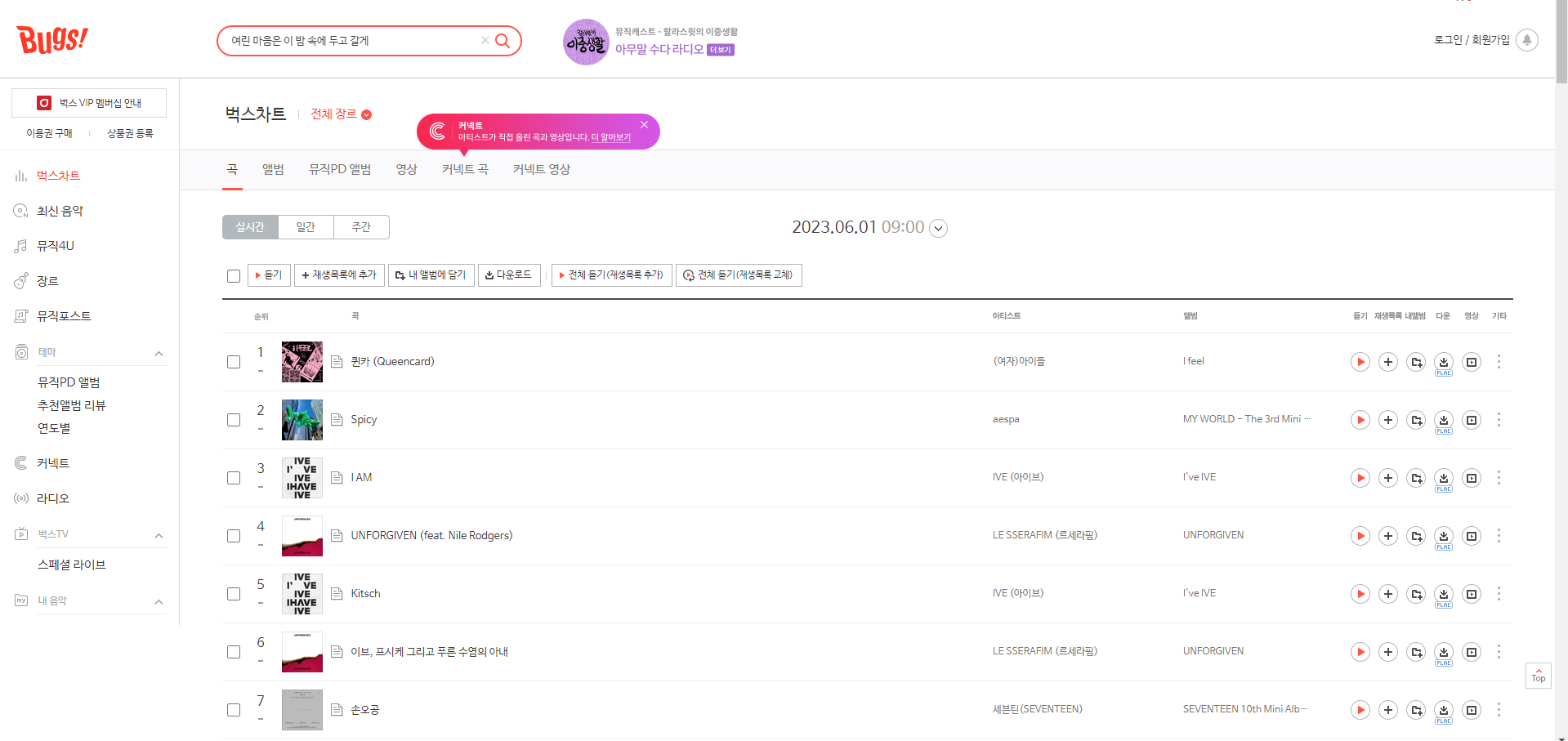
1-3. 음악차트 데이터 크롤링 1
차트 1위~100위까지의 제목, 가수를 크롤링하려는 경우
p 태그로 찾아옴
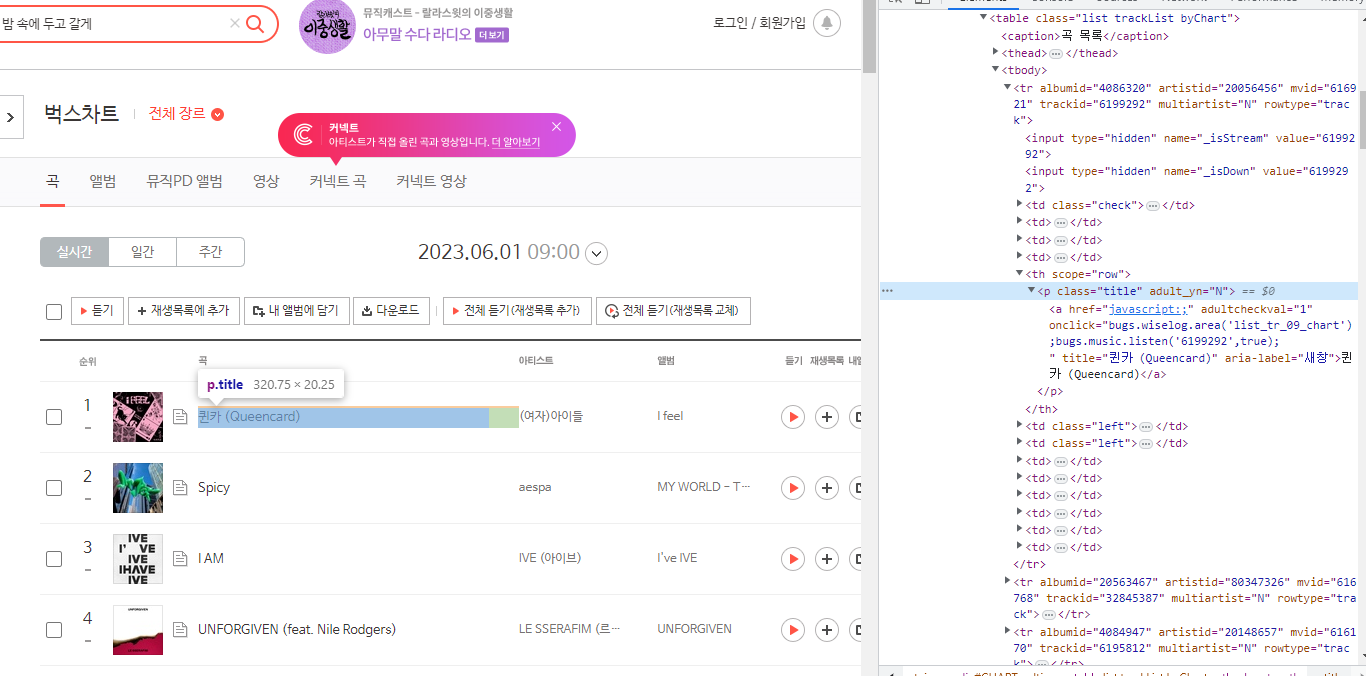
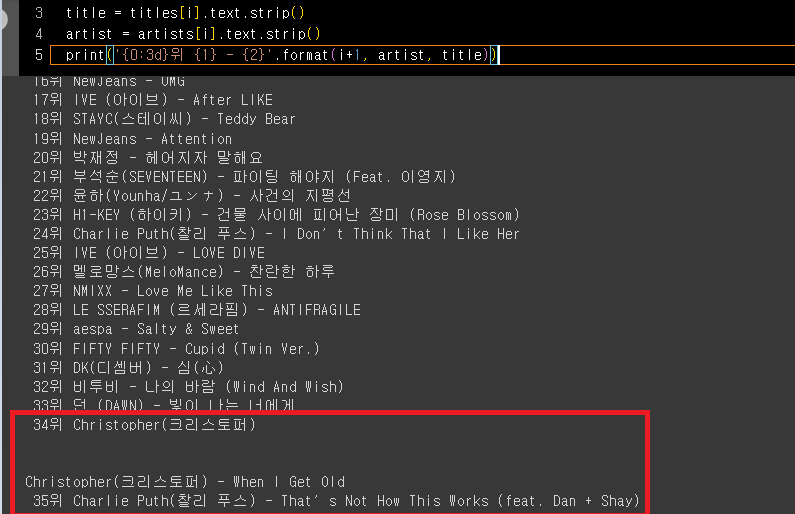
아래와 같은 문제가 발생
(Christopher가 2번이 중복됨)
→ artist에서 \n을 기준으로 split 후
request = requests.get('ht1tps://music.bugs.co.kr/chart')
soup = BeautifulSoup(request.text)
# 제목 찾아오기
titles = soup.findAll('p', {'class':'title'}) # p태그의 class가 title인 것을 모두 불러옴.
# print(titles)
# 가수 찾아오기
artists = soup.findAll('p', {'class':'artist'})
# print(artists)
# 출력
for i in range(len(titles)):
title = titles[i].text.strip()
artist = artists[i].text.strip().split('\n')[0]
# .split('\n')[0]이 없으면, artist의 길이가 길어져서 잘리는 부분은
# 2번 중복으로 들어가는 오류가 발생함.
print('{0:3d}위 {1} - {2}'.format(i+1, artist, title))
# zip함수를 이용하여 위의 코드를 변경하는 경우도 있음.
for i, (title, artist) in enumerate(zip(titles, artists), start=1):
title = title.text.strip()
artist = artist.text.strip().split('\n')[0]
print('{0:3d}위 {1} - {2}'.format(i, artist, title))
1-4. 음악차트 데이터 크롤링 2
robots.txt: 웹사이트의 크롤러같은 로봇들의 접근을 제어하기 위한 규약 파일. 권고안이므로 법적 근거는 없음. 사이트의 뒷부분에 robots.txt를 입력 후 확인이 가능. |
request = requests.get('https://www.melon.com/chart/index.htm')
print(request)
# 페이지를 찾지 못하는 오류인 406이 뜸. → Header가 없는 경우이기 때문에 Header를 만들어주어야 함.
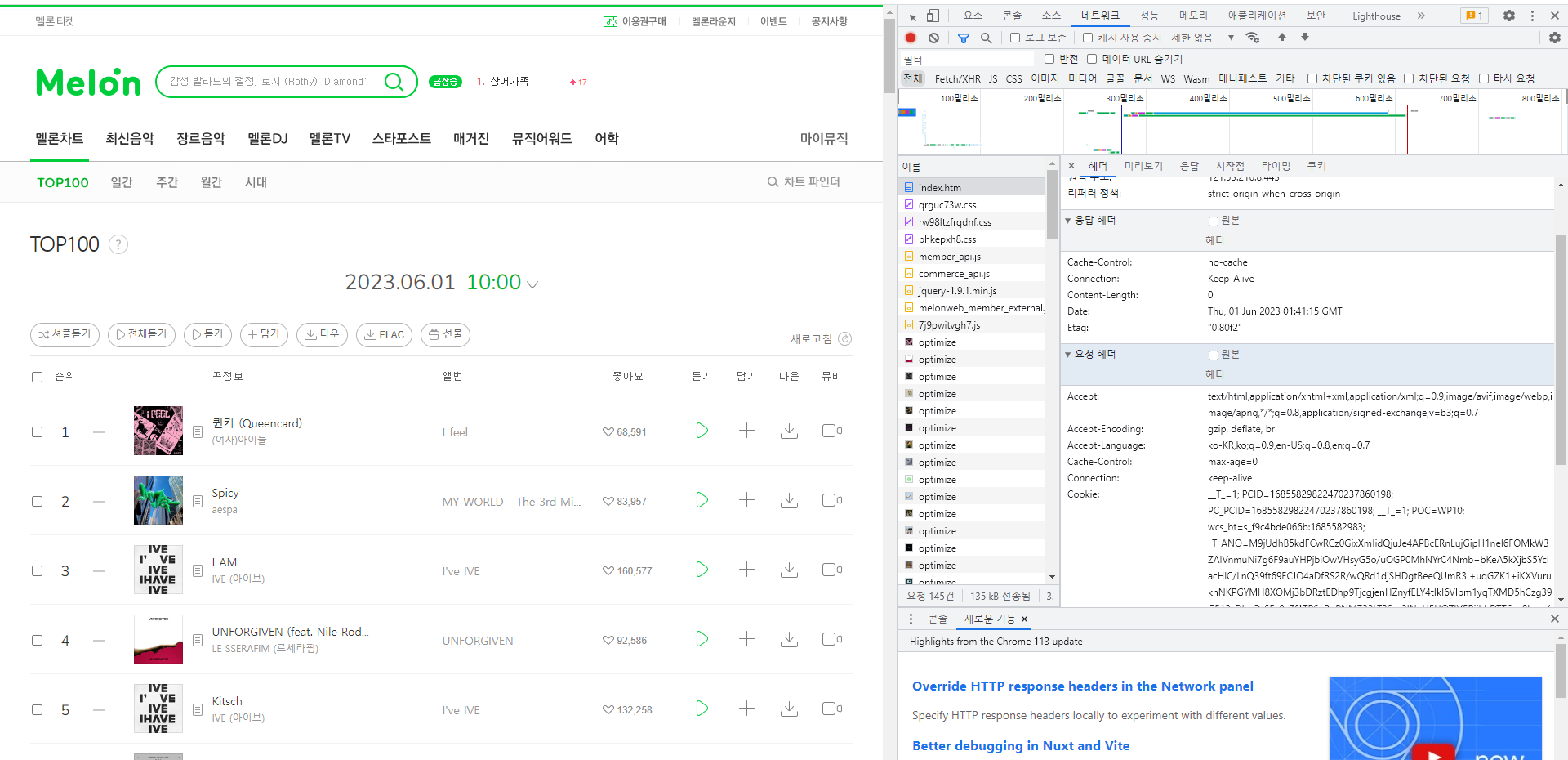
아래 내용을 포함하여 Header를 새로 생성.
\Header를 만드는 방법: [F12] 개발자모드 - 네트워크 - [F5] 새로고침 - 맨 상단의 chart/에서 User-Agent:
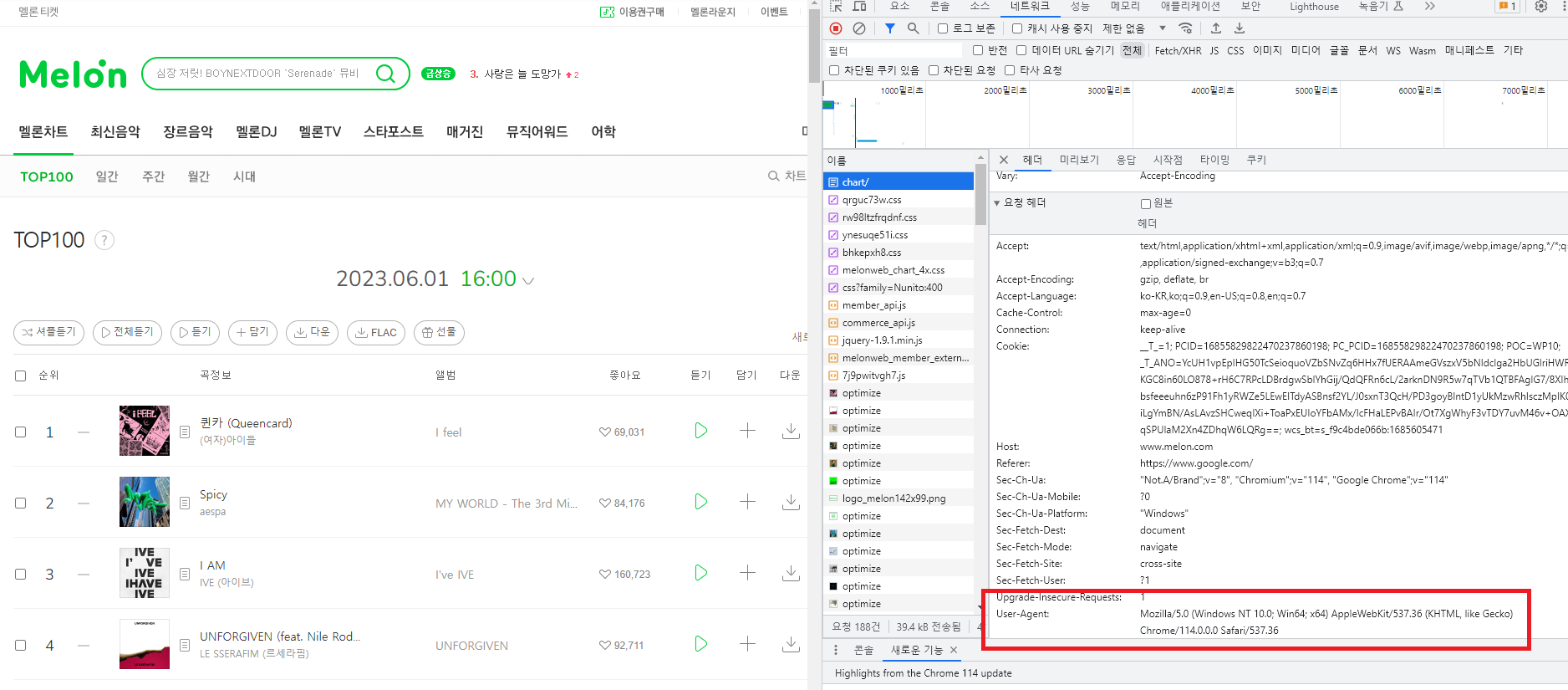

header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
# User-Agent를 전부 넣어줄 필요는 없음.
request = requests.get('https://www.melon.com/chart/index.htm', headers=header)
print(request) # Header를 만들어서 넣어주면 200이 정상적으로 뜸.
soup = BeautifulSoup(request.text)
titles = soup.findAll('div', {'class':'ellipsis rank01'})
artists = soup.findAll('span', {'class':'checkEllipsis'})
for i, (title, artist) in enumerate(zip(titles, artists), start=1):
title = title.text.strip()
artist = artist.text.strip()
print('{0:3d}위 {1} - {2}'.format(i, artist, title))
1-5. 주식 데이터 크롤링
site = 'https://finance.naver.com/item/main.naver?code=293490'
request = requests.get(site)
print(request)
soup = BeautifulSoup(request.text)
div_today = soup.find('div',{'class':'today'})
print(div_today)
em = div_today.find('em') # find()를 사용하면 첫번째 것만 확인
print(em)
price = em.find('span', {'class':'blind'}).text
print(price)
# 회사명 크롤링
wrap_company = soup.find('div',{'class':'wrap_company'})
name = wrap_company.a.text # a 태그에서 찾는 방식 중 하나
print(name)
# 종목코드 크롤링
div_description = wrap_company.find('div',{'class':'description'}) # a 태그에서 찾는 방식 중 하나
code = div_description.span.text
print(code)
#거래량 크롤링
no_info = soup.find('table',{'class':'no_info'})
tds = no_info.find_all('td') # a 태그에서 찾는 방식 중 하나
volume = tds[2].find('span').text
print(volume)
dic = {'price':price 'name':name, 'code':code, 'volume':volume}
dic

# 위의 내용들을 종합하여 코드를 넣으면 내용을 가져올 수 있는 함수만들기
def naver_finance(code):
site = f' https://finance.naver.com/item/main.naver?code= {code}'
request = requests.get(site)
soup = BeautifulSoup(request.text)
div_today = soup.find('div',{'class':'today'})
em = div_today.find('em')
price = em.find('span', {'class':'blind'}).text # 가격
wrap_company = soup.find('div',{'class':'wrap_company'})
name = wrap_company.a.text # 회사명
div_description = wrap_company.find('div',{'class':'description'})
code = div_description.span.text # 코드
no_info = soup.find('table',{'class':'no_info'})
tds = no_info.find_all('td')
volume = tds[2].find('span').text # 거래량
dic = {'price':price, 'name':name, 'code':code, 'volume':volume}
return dic
naver_finance('000910')

# 복수의 코드를 리스트로 만들어서 넣어보기
codes = ['103840', '001120', '005860', '078020']
data = []
for code in codes:
dic = naver_finance(code)
data.append(dic)
print(data)
# dataframe으로 바꿔서 넣어보기
import pandas as pd
df = pd.DataFrame(data)
df
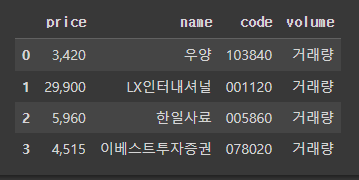
# 엑셀로 뽑아보기
df.to_excel('naver_finance.xlsx')
2. 셀레니움(Selenium)

자동화 웹 브라우저 도구로, 주로 웹 애플리케이션 테스트 및 웹 스크래핑과 같은 작업에 사용됨.
웹 애플리케이션 테스트에서는 자동화된 테스트 케이스를 작성/실행하여 동작을 확인할 수 있음.
웹 스크래핑에서는 웹 페이지에서 데이터를 추출하고 필요한 정보를 수집하는 데 사용됨.
→ 웹 페이지를 자동으로 제어하고 상호 작용할 수 있음.
여러 프로그래밍 언어(자바, 파이썬, C#, 루비)에서 사용할 수 있는 오픈 소스 도구이며
이 도구를 사용하면 웹 브라우저의 자동 실행/로드, 사용자와 상호 작용, 데이터 추출, 테스트 자동화가 가능.
특정 요소의 식별/클릭, 값의 입력이나 웹 페이지의 스크린샷 캡쳐, JavaScript 실행 또한 가능.
교육 간 셀레니움(Selenium)은 Jupyter notebook을 이용하여 실행할 예정.
(브라우저 Chrome을 사용 시, 가장 최신버전을 유지할 수 있도록 하는 것을 추천함)
해당 경로에서 터미널을 통해 실행
XPath: XML 문서의 구조를 탐색하고 원하는 요소나 속성을 선택하기 위한 언어. 원하는 데이터를 추출하거나 특정 요소에 접근하기 위한 목적으로 XML 문서의 경로를 표현하는데 사용되며, 문서의 계층 구조를 효과적으로 탐색할 수 있음. XPath는 다양한 프로그래밍 언어에서 지원되며, XML 파싱 라이브러리나 웹 크롤링 도구 등에서 주로 사용됨. 예) '/html/body/div[1]/div[5]/div/div/div[4]/div[1]/div[3]/div/div/div[8]/a/span[1]') |
2-1. 네이버 웹툰 댓글 데이터 크롤링
# 셀레니움 라이브러리 설치
# 셀레니움에서 Chrome 브라우저를 사용하기 위해 필요한 ChromeDriver를 자동으로 설치하는 도구 설치
!pip install selenium
!pip install chromedriver_autoinstaller
# webdriver 모듈: 웹 드라이버를 초기화하고 웹 브라우저를 제어하는 데 사용
from selenium import webdriver
# 키보드 키를 제어하기 위해 사용되는 Keys 클래스를 가져오는 데 사용
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get('https://www.python.org')
search = driver.find_element('name', 'q')
search.send_keys('날씨')
search.send_keys(Keys.RETURN)
driver = webdriver.Chrome()
driver.get('https://comic.naver.com/webtoon/detail?titleId=183559&no=567')
from bs4 import BeautifulSoup
soup = BeautifulSoup(driver.page_source)
driver.page_source
soup = BeautifulSoup(driver.page_source)
comment_area = soup.findAll('div', {'class', 'u_cbox_comment_box'})
print(comment_area)
print('*****베댓******')
for i in range(len(comment_area)):
comment = commnet_area[i].text.strip()
print(commnet)
print('-'*30)


