10. 전국 도시 공원 데이터 분석 예제
# 라이브러리 추가
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 한글이 사용가능하도록 함 !sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf plt.rc('font', family='NanumBarunGothic') |
park = pd.read_csv('/content/drive/MyDrive/K-DT/python_데이터분석/전국도시공원표준데이터.csv',
encoding='ms949')
# 뒤에 encoding='ms949'가 없이 실행될 경우, 인코딩문제로 오류가 발생함.
→ utf-8이 아닌 리눅스의 방식으로 인코딩을 변경해 줄 필요가 있음.
# park의 데이터 출력
park.head()
# park의 정보
park.info()
# 결측치의 확인
park.isnull().sum()
# park의 columns확인
park.columns
# 필요없는 columns의 삭제
park.drop(columns=['공원보유시설(운동시설)', '공원보유시설(유희시설)' ,'공원보유시설(편익시설)',
'공원보유시설(교양시설)', '공원보유시설(기타시설)', '지정고시일', '관리기관명', 'Unnamed: 19' ],
inplace=True)
# 삭제 후의 column 확인
park.columns
# 해당 data를 점그래프로 작성
park.plot.scatter(x='경도', y='위도', figsize=(8,10), grid=True)
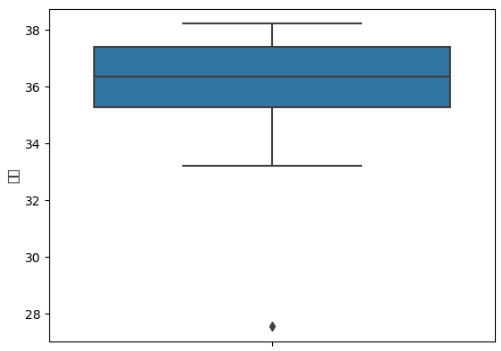
# 위도에 대한 boxplot(범위)를 출력
sns.boxplot(y=park['위도'])
# box의 가운데라인: 50%값(중위값)
# 맨 아래의 점: 이상한 값
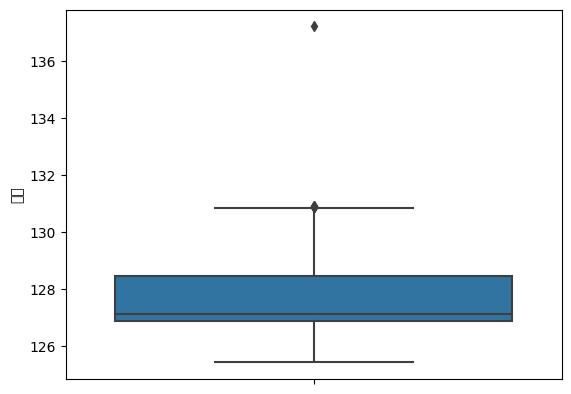
# 경도에 대한 boxplot(범위)를 출력
sns.boxplot(y=park['경도'])
# 위도, 경도가 잘못 입력된 이상한 값을 확인
# 경도가 132이상, 위도가 32이하인 것은 잘못된 이상한 값
# 잘못 입력된 값의 확인
park.loc[(park['위도']<32) | (park['경도']>132)]
# series의 비교는 'or' 연산자를 사용하지 않고, ' | ' 를 사용해야 한다.

# 이상한 값의 선택
park_loc_error = park.loc[(park['위도']<32) | (park['경도']>132)]
# 올바른 값의 추출
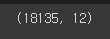
park = park.loc[(park['위도']>=32) & (park['경도']<=132)]
# 올바른 값의 추출 확인
park.shape
# '공원면적비율' 파생변수 만들기
# 공식: sqrt(공원면적) * 0.01
park['공원면적비율'] = park['공원면적'].apply(lambda x: np.sqrt(x) * 0.01) # lambda 함수 사용
# 파생변수의 정상적인 생성 확인
park.head()

#1 '도로명주소'는 입력되지 않고 '지번주소'만 입력된 데이터를 확인
park.loc[(park['소재지도로명주소'].isnull()) & (park['소재지지번주소'].notnull())]
# '도로명주소'와 '지번주소'가 모두 입력된 데이터를 확인
park.loc[(park['소재지도로명주소'].notnull()) & (park['소재지지번주소'].notnull())]
# '도로명주소'와 '지번주소'가 모두 입력되지 않은 데이터를 확인
park.loc[(park['소재지도로명주소'].isnull()) & (park['소재지지번주소'].isnull())]

# '도로명주소'가 입력되지 않은 데이터를 지번 주소로 대신 채움
park['소재지도로명주소'].fillna(park['소재지지번주소'], inplace=True)
park.head()

# 소재지도로명주소의 시군구 분할
str.split(' ', expand=True): 데이터프레임으로 변환 후 데이터 분리 → 인덱싱/슬라이싱 가능
park['소재지도로명주소'].str.split(' ', expand=True)
# 도로명주소에서 시도만 추출하여 시도 파생변수 만들기
park['시도']=park['소재지도로명주소'].str.split(' ', expand=True)[0]
park.head()

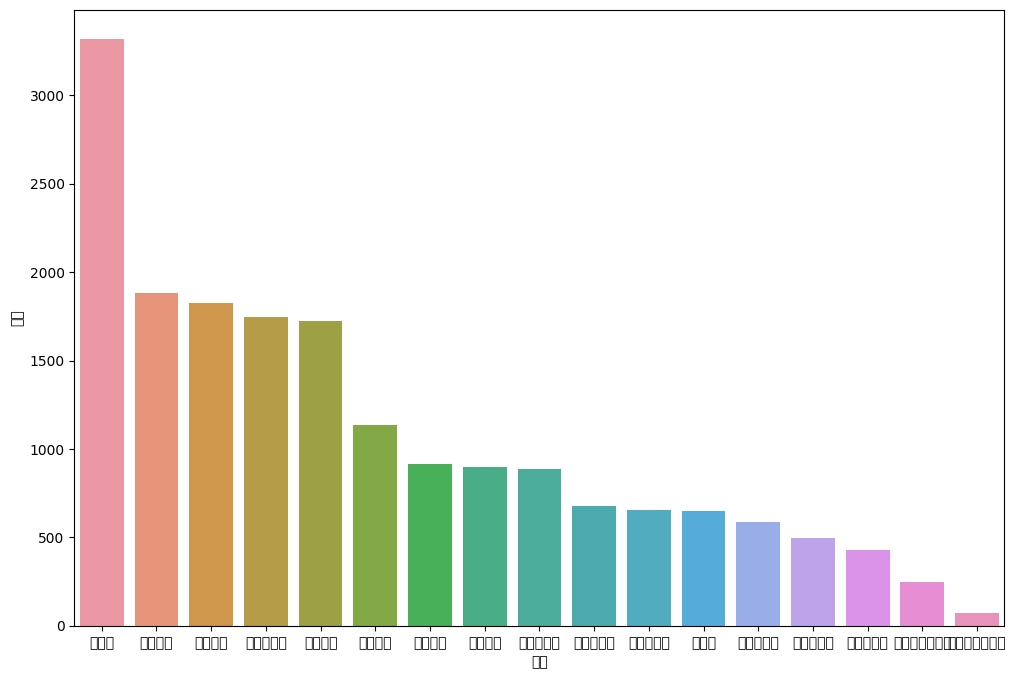
park['시도'].value_counts()

park.shape

#시도의 '강원'을 '강원도'로 변경
park['시도'][park['시도']=='강원'] = '강원도'
park['시도'].value_counts()

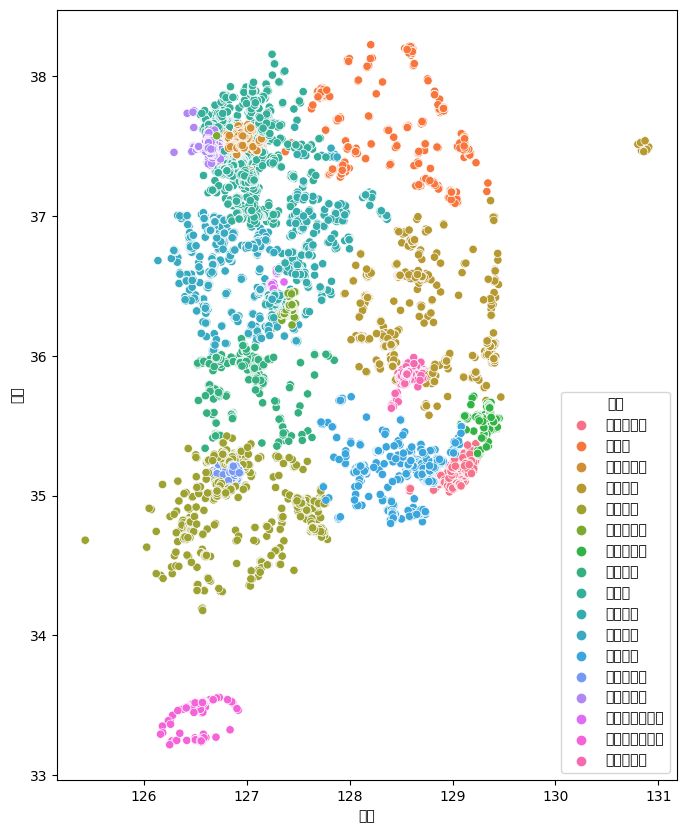
plt.figure(figsize=(8,10))
sns.scatterplot(data=park, x='경도', y='위도', hue='시도')
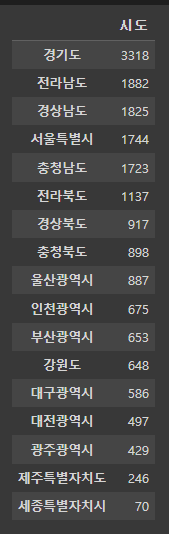
park_sido = pd.DataFrame(park['시도'].value_counts())
park_sido
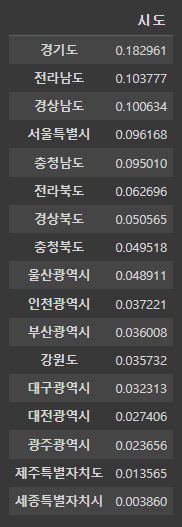
value_counts(normalize=True): 전체 합계에 대한 비율 계산
park_sido_normalize = pd.DataFrame(park['시도'].value_counts(normalize=True))
park_sido_normalize
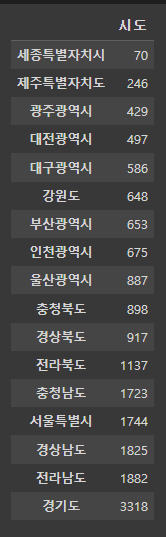
# value_counts(ascending=True): 오름차순 정렬
park_sido_ascending = pd.DataFrame(park['시도'].value_counts(ascending=True))
park_sido_ascending
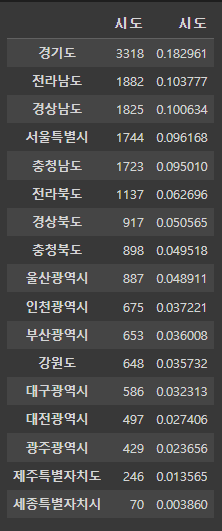
# 시도별 합계 데이터(park_sido)와 비율 데이터(park_sido_normalize)를 병합
pd.concat([park_sido, park_sido_normalize], axis=1)
# 또다른 병합방법
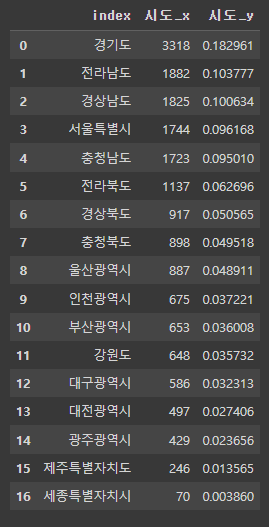
park_sido = park_sido.merge(park_sido_normalize, left_index=True, right_index=True).reset_index()
park_sido
# 컬럼 이름을 수정
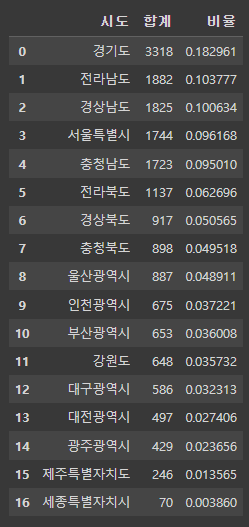
park_sido.columns = ['시도', '합계', '비율']
park_sido
plt.figure(figsize=(12,8))
sns.barplot(data=park_sido, x='시도', y='합계')