
6. 형태소 분석
6-1. 자연어
* 일상에서 사용하는 언어
* 컴퓨터는 자연어를 직접적으로 이해할 수 없음
→ 컴퓨터가 자연어의 의미를 분석해 처리할 수 있도록 하는 일을 '자연어 처리' 라고 부름.
(Natural Language Processing)
6-2. 토크나이징
* 문장을 의미가 있는 가장 작은 단어들로 나눔
* 나눠진 단어들을 이용해 의미를 분석
* 가장 기본이 되는 단어들을 '토큰'이라고 부름
* 문장 형태의 데이터를 처리하기 위해 제일 먼저 수행해야 하는 기본적인 작업
* 토크나이징을 어떻게 하느냐에 따라 성능에 차이가 있을 수 있음
6-3. 형태소분석
* 자연어의 문장을 형태소라는 최소단위로 분할하고 품사를 판별하는 작업
* 영어의 형태소 분석은 형태소마다 띄어쓰기를 해서 문장을 구성하는 것이 기본
* 아시아계열의 언어분석은 복잡하고 많은 노력이 필요함
* 한국어 형태소 분석 라이브러리: KoNLPy (교육 간 사용예정)
6-4. KoNLPy
* 기본적인 한국어 자연어 처리를 위한 파이썬 라이브러리
* 명사, 대명사, 수사, 동사, 형용사, 관형사, 부사, 조사, 감탄사 총 9가지를 분석
* 분석기
* Hannanum: 한나눔, KAIST에서 개발
* Kkma: 꼬꼬마, 서울대에서 개발
* Komoran: 코모란
* Okt(Open Korean Text): 오픈소스 한국어 분석기
# KoNLPy 설치
KoNLPy는 kolaw(대한민국 헌법 텍스트 파일)를 제공함.
!pip install KoNLPy
from konlpy.corpus import kolaw
# 1개의 파일을 읽어들어올 예정.
kolaw.fileids()
law = kolaw.open('constitution.txt').read()
law
# 정상적으로 읽어오는 것을 확인할 수 있음.
# KoNLPy는 kobill(국회법안 파일)을 제공
from konlpy.corpus import kobill
kobill.fileids()
# 파일 중 임의의 한 파일을 오픈
bill = kobill.open('1809897.txt').read()
bill

from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
law[:50]

nouns(): 명사를 추출
# hannanum 라이브러리를 이용한 명사 추출
hannanum.nouns(law[:50])

# kkma 라이브러리를 이용한 명사 추출
kkma.nouns(law[:50])

# komoran 라이브러리를 이용한 명사 추출
komoran.nouns(law[:50])

# okt 라이브러리를 이용한 명사 추출
okt.nouns(law[:50])

morphs(): 모든 품사를 추출
hannanum.morphs(law[:50])

pos(): 모든 품사를 부착
hannanum.pos(law[:50])

tagset: 부착되는 품사 태그와 기호에 대한 의미를 반환
okt.tagset

text = '아버지가방에들어가신다'
okt.pos(text)

text = '아버지가 방에 들어가신다'
okt.pos(text)

norm = True : 각 형태소에 대한 원형으로 처리
okt.pos('오늘 날씨가 참 좋네욬ㅋㅋㅋㅋㅋㅋㅋ', norm = True)
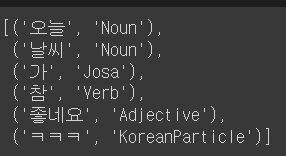
stem = True : 각 형태소에 대한 원형으로 처리
okt.pos('오늘 날씨가 참 좋네욬ㅋㅋㅋㅋㅋㅋㅋ', norm = True, stem = True)

7.워드 클라우드(Word Cloud)
핵심 단어를 시각화하는 기법
문서의 키워드, 개념 등을 직관적으로 파악할 수 있게 핵심 단어를 시각적으로 돋보이게 하는 기법
# 워드클라우드 설치
!pip install wordcloud
# 데이터 적용
text = open('/content/drive/MyDrive/K-DT/python_데이터분석/alice.txt').read()
text
# 워드클라우드 객체 import
from wordcloud import WordCloud
generate(): 단어별 출현 빈도 수를 비율로 반환하는 객체를 생성
wordcloud = WordCloud().generate(text)
# wordcloud 안의 단어들의 빈도 확인
wordcloud.words_

# 시각화를 위해 matplotlib을 import
import matplotlib.pyplot as plt
# wordcloud의 기본형
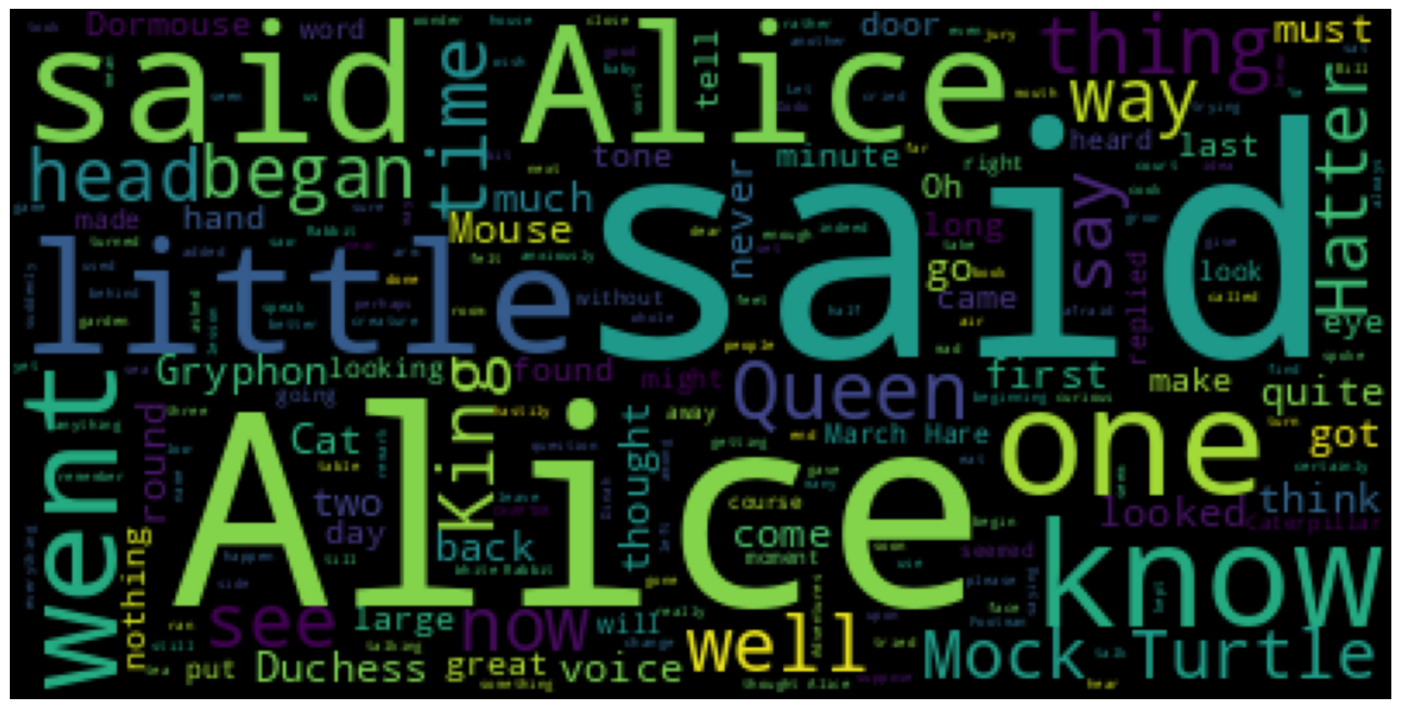
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
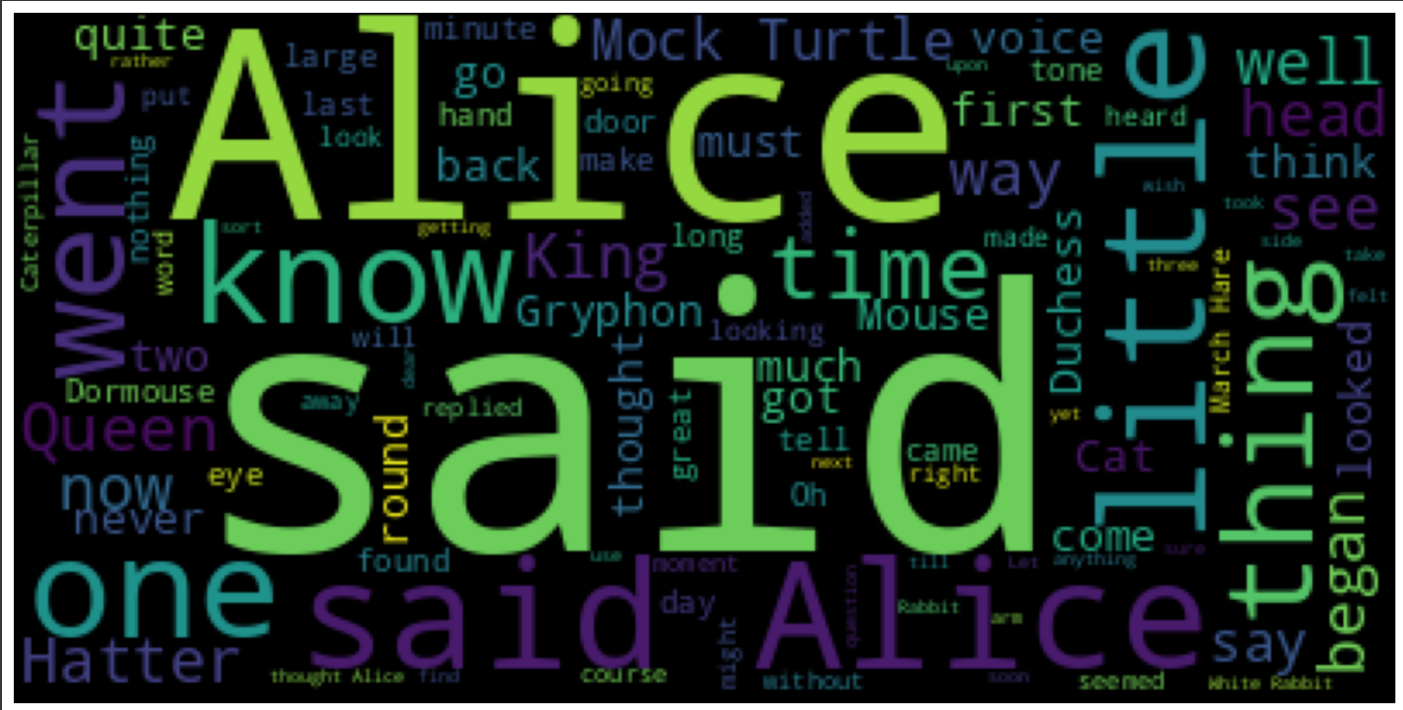
max_words: 워드클라우드에 표시되는 단어의 갯수를 설정
# wordcloud의 단어 수를 최대 100개로 설정하려는 경우
wordcloud = WordCloud(max_words=100).generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 한글은 깨질 우려가 있기 때문에, 글꼴을 별도로 변경해주는 것을 추천함. # 글꼴 변경 코드 !apt-get update -qq !apt-get install fonts-nanum* -qq import matplotlib.font_manager as fm sys_font = fm.findSystemFonts() [f for f in sys_font if 'Nanum' in f] |
# 글꼴 변경
wordcloud = WordCloud(max_words=100, font_path='/usr/share/fonts/truetype/nanum/NanumBarunpenR.ttf').generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

# 불용어 설정. 워드클라우드로 작성할 단어에서 제외할 단어를 설정
from wordcloud import STOPWORDS # 해당 라이브러리 사용
# STOPWORDS에 적용된 단어 리스트
STOPWORDS
# STOPWORDS의 타입
type(STOPWORDS) # STOPWORDS의 타입은 set이다.
# 불용어의 등록 (예: said)
STOPWORDS.add('said')
print(STOPWORDS)
# 불용어의 등록 확인.
wordcloud = WordCloud(max_words=100, font_path='/usr/share/fonts/truetype/nanum/NanumBrush.ttf', stopwords=STOPWORDS). generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# 이미지파일을 코랩에서 이용가능
from PIL import Image
import numpy as np
# 이미지 읽어들이기
alice_mask = np.array(Image.open('/content/drive/MyDrive/K-DT/python_데이터분석/alice_mask.png'))
alice_mask
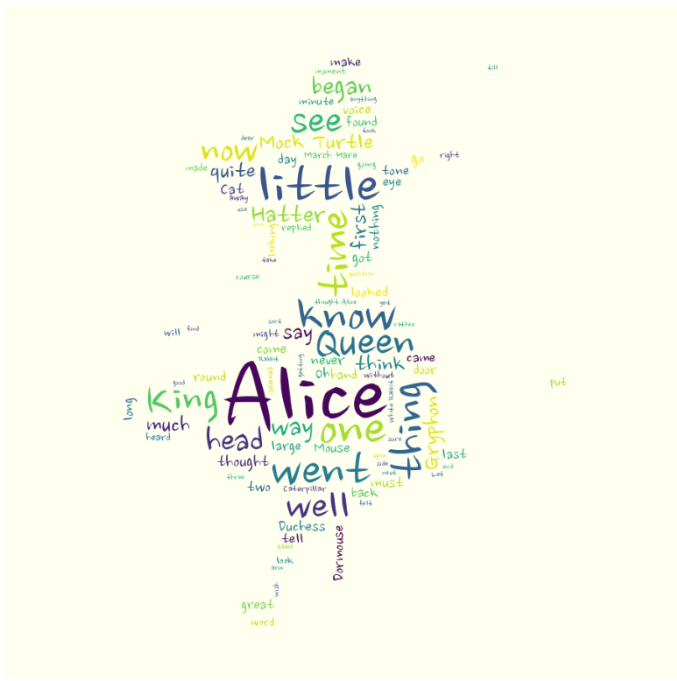
# 이미지에 워드클라우드 적용하기
wordcloud = WordCloud(
max_words=100,
font_path='/usr/share/fonts/truetype/nanum/NanumBrush.ttf',
stopwords=STOPWORDS,
mask=alice_mask,
background_color='ivory').generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

# 이미지파일 이용가능
from PIL import Image
import numpy as np
# 이미지 읽어들이기
alice_mask = np.array(Image.open('/content/drive/MyDrive/K-DT/python_데이터분석/alice_mask.png'))
alice_mask
# 이미지에 워드클라우드 적용하기
wordcloud = WordCloud(
max_words=100,
font_path='/usr/share/fonts/truetype/nanum/NanumBrush.ttf',
stopwords=STOPWORDS,
mask=alice_mask,
background_color='ivory').generate(text)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
# korea_mask.jpg에 적용하기
!pip install konlpy
from konlpy.corpus import kolaw
# constitution.txt를 이용하기.
text = kolaw.open('constitution.txt').read()
text

# okt를 이용해서 명사만 뽑아보기
from konlpy.tag import Okt
okt=Okt()
noun_text = okt.nouns(text)
print(noun_text)

# 1글자가 초과되는 글자만 적용되도록 sorting작업
noun_text.sort(key=lambda x: len(x))
print(noun_text)

# 불용어 몇개 추가. stop_words로 noun_text에서 뺌.
stop_words = ['함', '것', '제', '정', '그']
noun_text =[each_word for each_word in noun_text if each_word not in stop_words]
print(noun_text)

# 1글자가 초과되는 글자의 제외가 적용되도록 sorting작업
noun_text = [each_word for each_word in noun_text if len(each_word) > 1 ]
print(noun_text)

# Counter모듈 사용. (list의 글자의 빈도 수를 dictionary로 return해주는 모듈)
from collections import Counter
count = Counter(noun_text)
print(count)

# 100개까지만 dict의 형태로 뽑아오도록 함.
data = count.most_common(100)
data = dict(data)
print(data)

# 워드클라우드 적용하기
# dict에 저장된 data는 바로 워드클라우드에 적용할 수 없음.
→ generate_from_frequencies()를 사용해야 함.
wordcloud = WordCloud(
max_words=100,
font_path='/usr/share/fonts/truetype/nanum/NanumBrush.ttf').generate_from_frequencies(data)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

# korea-mask에 적용
mask = np.array(Image.open('/content/drive/MyDrive/K-DT/python_데이터분석/korea_mask.jpg'))
wordcloud = WordCloud(
max_words=20,
font_path='/usr/share/fonts/truetype/nanum/NanumBrush.ttf',
background_color='hotpink',
mask=mask).generate_from_frequencies(data)
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()




