이 예제에서는 파일의 텍스트를 string형 배열로 저장하고, 빈도별로 단어를 정렬하고, 결과를 플로팅하고,
파일에서 발견된 단어에 대한 기본 통계량을 수집하는 방법을 보여줍니다.
1) 텍스트 파일을 string형 배열로 가져오기
fileread 함수를 사용하여 셰익스피어의 소네트에서 텍스트를 읽습니다.
fileread는 텍스트를 1×100266 문자형 벡터로 반환합니다.
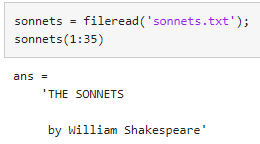
string 함수를 사용하여 텍스트를 문자열로 변환합니다.
그런 다음, splitlines 함수를 사용하여 새 줄 문자에서 분할합니다.
sonnets는 2625×1 string형 배열이 되며, 이 배열의 각 문자열에는 시의 한 라인이 포함됩니다.
sonnets의 처음 다섯 줄을 표시합니다.

2) string형 배열 정리하기
sonnets에서 단어의 빈도수를 계산하려면 먼저 빈 문자열과 문장 부호를 제거하여 배열을 정리하십시오.
그런 다음 개별 단어가 요소로 포함된 string형 배열로 형태 변경합니다.
string형 배열에서 문자가 0개("")인 문자열을 제거합니다.
sonnets의 각 요소와 빈 문자열인 ""을 비교합니다.
큰따옴표를 사용하여 빈 문자열을 비롯한 문자열을 만들 수 있습니다.
TF는 sonnets에서 0개 문자를 포함하는 문자열이 있는 위치마다 true 값을 가지는 논리형 벡터입니다.
TF를 사용하여 sonnets의 요소를 참조하고 0개 문자가 있는 모든 문자열을 삭제합니다.

일부 문장 부호를 공백 문자로 바꿉니다.
예를 들어, 마침표, 쉼표, 세미콜론을 바꿉니다.
아포스트로피는 light's와 같이 소네트의 일부 단어를 구성할 수 있으므로 유지합니다.

sonnets의 각 요소에서 strip 함수를 통해 선행 공백 문자와 후행 공백 문자를 제거합니다.

sonnets를 개별 단어를 요소로 갖는 string형 배열로 분할합니다.
split 함수를 사용하여 공백 문자 또는 구분 기호에서 string형 배열의 요소들을 분할할 수 있습니다.
그러나 split를 사용하려면 string형 배열의 모든 요소를 동일한 개수의 새 문자열로 나눌 수 있어야 합니다.
sonnets의 요소는 공백 수가 서로 다르기 때문에 동일한 개수의 문자열로 나눌 수 없습니다.
sonnets에 split 함수를 사용하려면 한 번에 하나의 요소에 대해 split를 호출하는 for 루프를 작성하십시오.
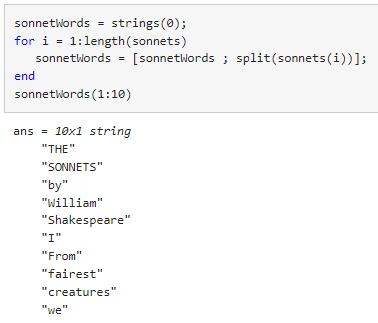
strings 함수를 사용하여 빈 string형 배열 sonnetWords를 생성합니다.
split 함수를 사용하여 sonnets의 각 요소를 분할하는 for 루프를 작성합니다.
split의 출력값을 sonnetWords에 결합합니다.
sonnetWords의 각 요소는 sonnets의 개별 단어를 나타냅니다.
3) 빈도수를 기준으로 단어 정렬하기
sonnetWords에서 고유한 단어를 찾습니다.
고유한 단어를 센 다음, 이러한 단어를 빈도수를 기준으로 정렬합니다.
대/소문자만 다른 단어를 동일한 단어로 취급하려면 sonnetWords를 소문자로 변환하십시오.
예를 들어, The와 the는 같은 단어로 취급됩니다. unique 함수를 사용하여 고유한 단어를 찾습니다.
그런 다음, histcounts 함수를 사용하여 고유한 단어가 나타나는 횟수를 셉니다.

이 횟수를 기준으로 가장 많은 빈도부터 가장 적은 빈도순으로 sonnetWords의 단어를 정렬합니다.

4) 단어 빈도 플로팅하기
소네트의 단어를 가장 많은 빈도부터 가장 적은 빈도순으로 플로팅합니다.
지프의 법칙(Zipf's Law)에 의하면 양이 많은 텍스트에서의 단어 사용 분포는
거듭제곱 법칙(Power-Law)의 분포를 따릅니다.

소네트에서 가장 많이 사용된 10개 단어를 표시합니다.

5) 테이블로 기본 통계량 수집하기
sonnetWords에서 각 단어가 나타나는 총 횟수를 계산합니다.
이 횟수를 총 단어 개수에 대한 비율로 계산하고 가장 많은 빈도순으로 누적 비율을 계산합니다.
단어와 이 단어에 대한 기본 통계량을 테이블에 작성합니다.

가장 많이 사용된 10개 단어에 대한 통계량을 표시합니다.

소네트에서 가장 많이 사용된 단어는 and이며 490회 사용되었습니다.
또한, 가장 많이 사용된 10개 단어가 텍스트에서 차지하는 비율은 20.163%입니다.
https://kr.mathworks.com/help/matlab/matlab_prog/analyze-text-data-with-string-arrays.html
string형 배열의 텍스트 데이터 분석하기 - MATLAB & Simulink - MathWorks 한국
이 예제의 수정된 버전이 있습니다. 사용자가 편집한 내용을 반영하여 이 예제를 여시겠습니까?
kr.mathworks.com