이 예제에서는 patients.mat 데이터 파일의 데이터를 그룹으로 분할하는 방법을 보여줍니다.
그런 다음 환자 그룹에 대한 평균 체중과 BMI(체질량지수), 혈압 수치의 분산값을 계산하는 방법을 보여줍니다.
또한 테이블에 결과를 요약해 표시하는 방법도 보여줍니다.
1) 환자 데이터 불러오기
100명의 환자로부터 수집한 샘플 데이터를 불러옵니다.

Gender와 SelfAssessedHealthStatus를 categorical형 배열로 변환합니다.

2) 평균 체중 계산하기
Smoker 변수를 사용하여 환자를 비흡연자와 흡연자로 나눕니다. 각 그룹의 평균 체중을 계산합니다.

findgroups 함수는 Smoker에서 생성된 그룹 번호의 벡터인 G를 반환합니다.
splitapply 함수는 G를 사용하여 Weight를 두 그룹으로 분할합니다.
splitapply는 각 그룹에 mean 함수를 적용하고 평균 체중을 벡터로 결합합니다.
findgroups는 그룹 식별자의 벡터를 두 번째 출력 인수로 반환합니다.
Smoker에 논리값이 포함되어 있으므로 그룹 식별자는 논리값입니다.
첫 번째 그룹의 환자는 비흡연자이고 두 번째 그룹의 환자는 흡연자입니다.

성별과 흡연 여부를 기준으로 환자의 체중을 분할하고, 평균 체중을 계산합니다.

Gender와 Smoker 간의 서로 다른 조합을 통해 네 가지 환자 그룹,
즉 여성 비흡연자, 여성 흡연자, 남성 비흡연자, 남성 흡연자가 식별됩니다.
네 개의 그룹과 각 그룹의 평균 체중을 테이블에 요약해 표시합니다.

T.gender는 categorical형 값을 가지며, T.smoker는 논리값을 가집니다.
이러한 테이블 변수의 데이터형은 Gender와 Smoker의 데이터형과 각각 일치합니다.
네 가지 환자 그룹의 BMI(체질량지수)를 계산합니다.
Height와 Weight를 두 개의 입력 인수로 사용하고, BMI를 계산하는 함수를 정의합니다.

3) 자기 보고를 기반으로 환자 그룹화하기
자신의 건강 상태를 Poor/Fair로 보고하는 환자의 비율을 계산합니다.
먼저, splitapply를 사용하여 각 그룹(여성 흡연자/비흡연자, 남성 흡연자/비흡연자)에 속한 환자의 수를 셉니다.
그런 다음 S와 G에 논리형 인덱싱을 사용하여, 자신의 건강 상태를 Poor/Fair로 보고하는 환자의 수만 셉니다.
이러한 개수로 이루어진 두 집합에서 각 그룹의 비율을 계산합니다.

Poor 또는 Fair로 건강 상태를 보고하는 환자와 Good 또는 Excellent로 건강 상태를 보고하는 환자의
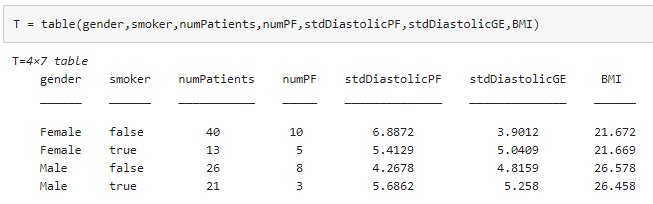
각 Diastolic 측정값에 대한 표준편차를 비교합니다.

결과를 테이블로 수집합니다.
이 환자들 중에서는 Poor나 Fair로 건강 상태를 보고하는 여성 비흡연자가 혈압 수치에서 가장 큰 폭의 차이를 보여줍니다.
데이터를 그룹으로 분할하고 통계량 계산하기 - MATLAB & Simulink - MathWorks 한국
이 예제의 수정된 버전이 있습니다. 사용자가 편집한 내용을 반영하여 이 예제를 여시겠습니까?
kr.mathworks.com