tall형 배열을 사용하면 datastore에 상주하지 않는 큰 데이터에 대한 작업을 수행할 수 있습니다.
데이터저장소에서는 대규모 데이터 세트 전체를 메모리에 한 번에 불러오는 대신
이 데이터 세트를 메모리에 담을 수 있는 각각의 작은 블록 단위로 나눠 작업할 수 있습니다.
tall형 배열은 일반적인 함수를 사용하여 메모리에 상주하지 않는 큰 데이터에 대한 작업을 수행할 수 있도록
이 기능을 확장합니다.
1) tall형 배열이란?
데이터를 한 번에 모두 메모리에 불러오지 않기 때문에 첫 번째 차원의 tall형 배열 크기가 임의적으로 커질 수 있습니다
(즉, 가질 수 있는 행 개수에 제한이 없음).
MapReduce 같은 기술로 대규모 데이터에 사용되는 특수 코드를 작성하는 대신,
tall형 배열을 사용하면 메모리 내 MATLAB 배열을 사용하는 것과 유사한 직관적인 방식으로
대규모 데이터 세트를 사용할 수 있습니다.
많은 핵심 연산자와 함수는 메모리 내 배열에서 작동하는 것과 동일하게 tall형 배열에서 작동합니다.
MATLAB은 한 번에 작은 블록 단위의 데이터로 나눠서 작업하며 모든 데이터 청크화 작업과 처리 작업이
백그라운드에서 이루어지기 때문에 A+B 같은 일반적인 표현식으로 빅데이터 세트를 처리할 수 있습니다.
2) tall형 배열의 이점
메모리 내 배열과 달리 tall형 배열은 사용자가 gather 함수를 사용하여 계산 수행 요청을 하지 않으면
해당 데이터를 미평가 상태로 유지합니다.
이렇게 평가 작업을 보류해 두면 대규모 데이터 세트를 신속히 처리할 수 있습니다.
나중에 gather 함수를 사용하여 출력값을 요청할 경우 MATLAB은 가능한 한 대기 중인 계산을 함께 처리할 수 있고,
데이터 통과 횟수를 최소화할 수 있습니다.
데이터 통과 횟수는 실행 시간에 큰 영향을 미치기 때문에 필요한 경우에만 출력값을 요청하는 것이 좋습니다.
참고:
gather 함수가 결과를 메모리 내 MATLAB 배열로 반환하기 때문에 일반 메모리 고려 사항이 적용됩니다.
따라서 gather 함수에서 반환된 결과가 너무 큰 경우 MATLAB은 메모리 부족을 겪을 수도 있습니다.
3) tall형 테이블 만들기
tall형 테이블은 행 개수에 제한이 없다는 점만 제외하면 메모리 내 MATLAB 테이블과 유사합니다.
대규모 데이터 세트에서 tall형 테이블을 만들려면 먼저 해당 데이터를 위한 데이터저장소를 만들어야 합니다.
데이터저장소 ds에 테이블 형식의 데이터가 포함되어 있으면 tall(ds)는 이 데이터를 포함한 tall형 테이블을 반환합니다.
항공편 데이터로 구성된 테이블 형식 파일을 가리키는 스프레드시트 데이터저장소를 만듭니다.
여러 파일이 포함된 폴더의 경우 전체 폴더 위치를 지정하거나 와일드카드 문자 '*.csv'를 사용하여
파일 확장자가 동일한 여러 개의 파일을 데이터저장소에 포함시킬 수 있습니다.
tabularTextDatastore에서 누락된 값을 NaN 값으로 바꿀 수 있도록 'NA' 값을 누락값으로 처리하여 데이터를 정리합니다.
또한 몇 가지 텍스트 변수의 형식을 %s로 설정하여
tabularTextDatastore가 이 변수를 문자형 벡터로 구성된 셀형 배열로 읽어오도록 합니다.

데이터저장소에서 tall형 테이블을 만듭니다.
이 tall형 테이블에 대해 계산을 수행하면 기본 데이터저장소가 데이터의 블록을 읽어온 다음,
처리를 위해 tall형 테이블에 전달합니다. 데이터저장소와 tall형 테이블에는 어떠한 기본 데이터도 없습니다.


위 화면을 보면 행 개수 M을 현재 알 수 없다는 것을 확인할 수 있습니다.
MATLAB은 일부 행만을 표시하며 세로 말줄임표 :를 통해 tall형 테이블에 현재 표시되지 않은 행이 더 많이 있음을
알 수 있습니다.
4) tall형 타임테이블 만들기
사용 중인 데이터의 각 행이 시간과 연관된 경우 tall형 타임테이블을 사용하여 데이터 작업을 수행할 수 있습니다.
다음과 같은 경우, tall형 테이블 tt의 각 행이 시간과 연관되어 있지만 여러 테이블 변수로 나뉘어 있습니다.
이러한 모든 날짜/시간 정보를 새로운 tall datetime형 변수 Dates(출발 시간 DepTime을 기준으로 함)로 결합합니다.
그런 다음 Dates를 행 시간값으로 사용하여 tall형 타임테이블을 만듭니다.
Dates가 유일한 datetime형 변수이기 때문에 table2timetable 함수는 행 시간값에 이 변수를 자동으로 사용합니다.


5) tall형 배열 만들기
tall형 테이블/타임테이블에서 변수를 추출할 경우 해당 기본 데이터형으로 구성된 tall형 배열이 생성됩니다.
tall형 배열은 숫자형, 논리형, datetime형, duration형, calendarDuration형, categorical형, string형
또는 셀형 배열일 수 있습니다.
또한 메모리 내 배열 A를 tA = tall(A)를 사용해 tall형 배열로 변환할 수 있습니다.
메모리 내 배열 A는 지원되는 데이터형 중 하나를 가져야 합니다.
tall형 타임테이블 TT에서 도착 지연 시간 ArrDelay를 추출합니다.
그러면 기본 데이터형이 double인 새 tall형 배열 변수가 생성됩니다.

classUnderlying 함수와 isaUnderlying 함수는 tall형 배열의 기본 데이터형을 확인하는 데 유용합니다.
6) 평가 보류
tall형 배열의 중요한 특성 중 하나는 tall형 배열로 작업할 때 대부분의 연산이 즉시 수행되지 않는다는 점입니다.
사용자가 확실히 계산 수행을 요청할 때까지 계산을 보류해 두기 때문에 연산이 신속하게 실행되는 것처럼 보입니다.
gather 함수나 write 함수를 사용하여 tall형 배열의 평가를 시작할 수 있습니다.
size() 같이 간단한 명령도 10억 개의 행이 포함된 tall형 배열에서 실행하면 빠르게 계산하기 힘들기 때문에
이처럼 평가를 보류하는 것이 매우 중요합니다.
tall형 배열로 작업할 때 MATLAB은 수행되는 모든 연산을 추적합니다.
그런 다음 이 정보는 gather 함수로 출력값을 요청할 때 필요한 데이터 통과 횟수를 최적화하는 데 사용됩니다.
따라서 미평가 tall형 배열로 작업하면서 필요한 경우에만 출력값을 요청하는 것이 일반적입니다.
도착 지연 시간의 평균과 표준편차를 계산합니다.
이러한 값을 기준으로 평균에서 표준편차 1 범위 내에 있는 지연 시간의 상한과 하한을 생성합니다.
각 연산 결과를 보면 배열이 아직 계산되지 않았음을 알 수 있습니다.
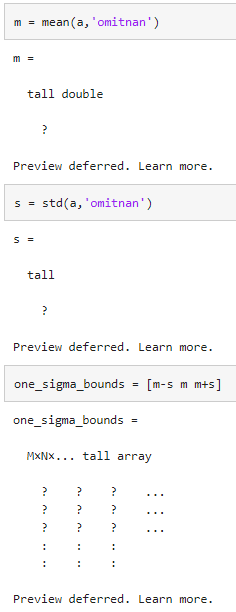
7) gather 함수로 평가
지연된 평가의 이점은 MATLAB이 계산을 수행할 때 데이터 통과 횟수를 최소화하는 방식으로 연산을 결합할 수 있는
경우가 많다는 점입니다.
따라서 많은 연산을 수행할 때도 MATLAB은 반드시 필요한 경우에만 추가적인 데이터 통과를 수행합니다.
gather 함수는 대기 중인 모든 연산을 강제로 평가하고 결과 출력값을 메모리로 가져옵니다.
이런 이유로, tall형 배열과 메모리 내 배열을 연계하는 수단으로 gather를 사용하는 것을 고려해 볼 수 있습니다.
예를 들어, tall 논리형 배열을 사용하면 if 루프 또는 while 루프를 제어할 수 없지만
gather 함수를 사용하여 이 배열을 평가하면 이러한 컨텍스트에서 사용할 수 있는 메모리 내 논리형 배열이 됩니다.
gather는 MATLAB에서 전체 결과를 반환하기 때문에 결과가 메모리에 담길 수 있는지 확인해야 합니다.
gather 함수를 사용하여 one_sigma_bounds를 계산한 후 결과를 메모리로 가져옵니다.
이 경우, one_sigma_bounds를 계산하려면 여러 가지 연산이 필요하지만
MATLAB에서 이러한 연산을 한 번의 데이터 통과로 결합합니다.
이 예제의 데이터는 작기 때문에 gather 함수가 신속히 실행됩니다.
그러나 데이터 크기가 늘어날수록 데이터 통과 횟수를 줄이는 것이 더 중요합니다.
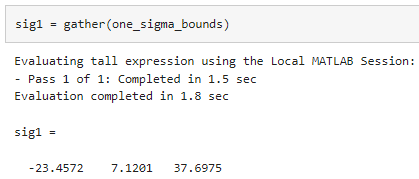
여러 tall형 배열을 한 번에 평가하려는 경우 gather 함수에 대한 입력값과 출력값을 여러 개 지정할 수 있습니다.
이 방법은 gather 함수를 여러 번 호출하는 것보다 더 빠릅니다.
예를 들어, 도착 지연 시간의 최솟값과 최댓값을 계산해 보겠습니다.
각 값을 따로 계산할 경우 각 값에 대해 데이터 통과가 한 번씩 필요하여 총 두 번의 통과에 대해 계산해야 합니다.
그러나 두 값을 동시에 계산할 경우 데이터 통과가 한 번만 필요합니다.

결과를 통해, 대부분의 항공편이 평균적으로 약 7분 늦게 도착한다는 것을 알 수 있습니다.
그러나 이 값은 항공편의 1 표준편차 범위 내에(최대 37분 지연 또는 23분 조기 도착) 있습니다.
데이터 세트에서 가장 일찍 도착한 항공편은 약 1시간 빨랐고 가장 늦게 도착한 항공편은 수 시간 지연되었습니다.
8) tall형 배열 저장, 불러오기 및 검사 지점 생성
save 함수는 tall형 배열의 상태를 저장하지만 데이터를 복사하지는 않습니다.
결과로 나타나는 .mat 파일은 대개 크기가 작습니다.
그러나 이후에 load를 사용하려면 원래 데이터 파일이 동일한 위치에 있어야 합니다.
write 함수는 데이터 복사본을 만들고 여러 개의 파일로 저장하기 때문에 디스크 공간을 많이 쓸 수 있습니다.
write 함수는 값을 쓰기 전에, 대기 중인 모든 tall형 배열에 대한 연산을 실행하여 값을 계산합니다.
write 함수가 데이터를 복사하면 이 복사된 데이터는 원래 원시 데이터에 대해 독립적입니다.
따라서 원래의 원시 데이터를 더 이상 사용할 수 없더라도 복사된 파일에서 tall형 배열을 다시 만들어낼 수 있습니다.
파일이 작성된 위치를 가리키는 새 데이터저장소를 만들어 작성된 파일에서 tall형 배열을 다시 만들 수 있습니다.
이 기능을 사용하여 tall형 배열 데이터의 검사 지점이나 스냅샷을 만들 수 있습니다.
데이터 전처리는 데이터를 불러오기에 더 효율적인 형식으로 만드는 작업인데,
검사 지점 만들기는 이러한 데이터의 전처리 결과를 저장하기에 좋은 방법입니다.
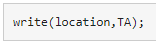
tall형 배열 TA가 있는 경우 다음 명령을 사용하여 이 tall형 배열을 폴더 location에 쓸 수 있습니다.
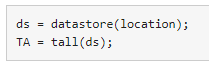
나중에, 이 작성된 파일에서 TA를 다시 생성하려면 다음 명령을 사용하십시오.
그 외에도 write 함수를 사용하여 tall형 배열의 평가를 시작하고 그 결과를 디스크에 쓸 수 있습니다.
write 함수를 사용하는 것은 gather 함수를 사용하는 것과 유사하지만 write 함수는 메모리에 결과를 저장하지 않습니다.
9) 지원 함수
대부분의 핵심 함수는 메모리 내 배열에 대한 작업을 수행할 때와 동일하게 tall형 배열에 대한 작업을 수행합니다.
그러나 tall형 배열에 대한 함수의 작업 방식이 특수하거나 제한 사항이 있는 경우가 있습니다.
어떤 함수가 tall형 배열을 지원하는지 그리고 어떤 제한 사항이 있는지 알아보려면
그 함수 도움말 페이지의 맨 아래에서 확장 기능 섹션을 보십시오(예를 들어, filloutliers 참조).
tall형 배열은 머신러닝 알고리즘 작성, 독립 실행형 앱 배포, 병렬 계산 실행 또는 클러스터에서
계산 실행 같은 작업을 할 수 있는 여러 툴박스에서도 지원됩니다.
https://kr.mathworks.com/help/matlab/import_export/tall-arrays.html
메모리에 담을 수 없는 큰 데이터를 위한 tall형 배열 - MATLAB & Simulink - MathWorks 한국
다음 MATLAB 명령에 해당하는 링크를 클릭했습니다. 명령을 실행하려면 MATLAB 명령 창에 입력하십시오. 웹 브라우저는 MATLAB 명령을 지원하지 않습니다.
kr.mathworks.com