1) 데이터를 가져오는 데 사용할 수 있는 로우 레벨 함수
로우 레벨 파일 I/O 함수를 사용하면 파일에서 데이터를 읽어오거나 파일에 데이터를 쓸 때 최대한 제어할 수 있습니다.
그러나 이런 함수를 사용할 때는 사용이 쉬운 하이 레벨 함수에 비해 파일에 더 자세한 정보를 지정해야 합니다.
하이 레벨 함수가 데이터를 가져올 수 없는 경우 다음 중 하나를 사용하십시오.
1. fscanf - 텍스트 편집기에서 볼 수 있는 파일(텍스트 파일이나 ASCII 파일)에서 형식 지정된 데이터를 읽어옵니다.
2. fgetl과 fgets - 파일의 라인을 한 번에 하나씩 읽어옵니다. 여기서 각각의 라인은 새 줄(Newline) 문자로 구분됩니다.
3. fread - Byte 또는 Bit 수준에서 데이터 스트림을 읽어옵니다.
참고:
로우 레벨 파일 I/O 함수는 ANSI 표준 C 라이브러리의 함수를 기반으로 합니다.
그러나 MATLAB에서 사용하는 함수는 벡터화된 버전이며,
배열에서 데이터를 읽어오고 쓸 때 최소한의 제어 루프를 사용합니다.
2) 파일에서 이진 데이터 읽어오기
어느 로우 레벨 I/O 함수에서든 파일을 가져오려면 먼저 fopen을 사용하여 파일을 열고 파일 ID를 부여받아야 합니다.
파일에 대한 작업을 마치면 fclose(fileID)를 사용하여 파일을 닫습니다.
기본적으로, fread는 한 번에 1바이트씩 파일을 읽어 각 바이트를 8비트 부호 없는 정수(uint8)로 해석합니다.
fread는 파일의 각 바이트가 하나의 요소로 표현되는 열 벡터를 생성합니다. 열 벡터의 값은 double형 클래스입니다.
예를 들어, 다음과 같이 생성된 파일 nine.bin을 살펴보겠습니다.

파일의 모든 데이터를 double형 클래스의 9×1 열 벡터로 읽어 들이려면 다음을 수행하십시오.

배열의 차원 변경하기
기본적으로, fread는 파일의 모든 값을 열 벡터로 읽어 들입니다.
그러나 사용자가 읽어 들일 값 개수를 지정하거나 2차원 출력 행렬으로 표현할 수도 있습니다.
예를 들어, 이전 예제에서 설명한 nine.bin을 읽어 들이려면 다음을 수행하십시오.

입력값 표현하기
파일의 값이 8비트 부호 없는 정수가 아니라면 값 크기를 지정하십시오.
예를 들어, 다음과 같이 배정밀도 값으로 만든 파일 fpoint.bin이 있다고 가정하겠습니다.

파일을 읽는 방법은 다음과 같습니다.

메모리 절약하기
기본적으로, fread는 double형 클래스로 구성된 배열을 생성합니다.
배열에 배정밀도 값을 저장하는 것은 문자나 정수, 단정밀도 값을 저장할 때보다 더 많은 메모리를 요합니다.
데이터 저장에 필요한 메모리 양을 줄이려면 다음 방법 중 하나를 사용하여 배열의 클래스를 지정하십시오.
* 별표('*')를 사용하여 입력값 클래스를 일치시킵니다.
예를 들어, 단정밀도 값을 single형 클래스의 배열로 읽어오려면 다음 명령을 사용하십시오.
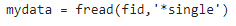
* '=>' 기호를 사용하여 입력값을 새 클래스에 매핑합니다.
예를 들어, uint8 값을 uint16 배열로 읽어오려면 다음 명령을 사용하십시오.

3) 파일의 일부 읽어오기
MATLAB 로우 레벨 함수에는 파일의 이진 데이터의 일부를 읽을 수 있는 여러 가지 옵션이 있습니다.
* 배열의 차원 변경하기에 설명된 대로, 한 번에 지정된 개수의 값을 읽어옵니다.
이 방법을 파일의 끝 테스트하기에 함께 사용해 보십시오.
* 파일 내에서 읽기를 시작할 특정 위치로 이동합니다.
* 요소를 읽을 때마다 특정 바이트 수 또는 비트 수를 건너뜁니다.
파일의 끝 테스트하기
파일을 열면 MATLAB에서 파일 내 현재 위치를 나타내는 포인터가 생성됩니다.
참고:
빈 파일을 열면 파일 위치 표시자가 파일 끝으로 이동하지 않습니다.
읽기 작업을 하거나 fseek 및 frewind 함수를 사용하면 파일 위치 표시자의 위치가 바뀔 수 있습니다.
feof 함수를 사용하여 파일 끝에 도달했는지 확인할 수 있습니다.
feof는 파일 포인터가 파일 끝에 있으면 값 1을 반환합니다. 그렇지 않으면, 0을 반환합니다.
예를 들어, 다음과 같이 큰 파일을 분할하여 읽습니다.

파일 내에서 이동하기
데이터의 선택한 부분을 읽어오거나 쓰려면 파일 위치 표시자를 파일 내 임의 위치로 옮기십시오.
예를 들어, 다음 구문을 사용하여 fseek를 호출합니다.

여기서,
fid는 fopen에서 가져온 파일 ID입니다.
offset은 바이트 단위로 지정된, 양의 오프셋 값이거나 음의 오프셋 값입니다.
origin은 계산을 시작할 위치를 지정합니다.

또는 파일 시작 부분으로 손쉽게 이동하려면 다음을 실행하십시오.

ftell을 사용하여 지정된 파일 내에서의 현재 위치를 찾을 수 있습니다.
ftell은 파일의 시작 부분부터 떨어진 거리를 바이트 수로 반환합니다.
예를 들어, 파일 five.bin을 만들어 보겠습니다.

fwrite를 호출하면 short 형식이 지정되기 때문에 A의 각 요소는 five.bin에서 2바이트 저장 공간을 사용합니다.
읽기 목적으로 five.bin을 다시 엽니다.

파일 위치 표시자를 파일의 시작 부분에서 6바이트 앞으로 움직입니다.

그 다음 요소를 읽습니다.
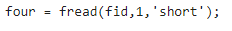
읽기를 수행하면 파일 위치 표시자가 앞으로 이동합니다.
파일 위치 표시자의 현재 위치를 확인하려면 ftell:을 호출하십시오.

파일 위치 표시자를 4바이트 뒤로 이동하려면 fseek를 다시 호출하십시오.

그 다음 값을 읽습니다.

4) 다른 시스템에서 만든 파일 읽어오기
운영 체제마다 바이트 또는 비트 수준에서 정보를 저장하는 방식이 서로 다릅니다.
빅 엔디안 시스템은 가장 큰 주소의 바이트부터 메모리에 저장합니다(즉, 큰 쪽(big end)부터 시작합니다).
리틀 엔디안 시스템은 가장 작은 주소의 바이트부터 저장합니다(즉, 작은 쪽(little end)부터 시작합니다).
Windows 시스템은 리틀 엔디안 바이트 순서를 사용하고 UNIX® 시스템은 빅 엔디안 바이트 순서를 사용합니다.
상반되는 엔디안 시스템에서 생성된 파일을 읽어오려면 파일을 생성할 때 사용한 바이트 순서를 지정하십시오.
순서는 파일을 열기 위해 호출할 때나 파일을 읽기 위해 호출할 때 지정할 수 있습니다.
예를 들어, 리틀 엔디안 시스템에서 생성되고 배정밀도 값을 가진, little.bin 파일이 있다고 가정해 보겠습니다.
이 파일을 빅 엔디안 시스템에서 읽어오려면 다음 명령 중 하나(또는 둘 다)를 사용하십시오.
다음과 같이 파일을 엽니다.

다음과 같이 파일을 읽습니다.

여기서 'l'은 리틀 엔디안 순서를 나타냅니다.
현재 시스템에서 사용하는 바이트 순서를 잘 모르는 경우 computer 함수를 호출하십시오.

반환되는 ordering이 'L'이면 리틀 엔디안 시스템이고 'B'이면 빅 엔디안 시스템입니다.