이 예제에서는 categorical형 배열의 데이터를 플로팅하는 방법을 보여줍니다.
1) 샘플 데이터 불러오기
100명의 환자로부터 수집한 샘플 데이터를 불러옵니다. patients MAT 파일에서 배열의 데이터형과 크기를 표시합니다.

2) categorical형 배열 생성하기
작업 공간 변수 Location은 환자의 상태를 조사한 3개의 고유한 의료 시설을 나열합니다.
데이터를 더욱 쉽게 액세스하고 비교하기 위해 Location을 categorical형 배열로 변환합니다.

categorical형 배열을 요약합니다. 요약에는 Location에 각 범주가 나타나는 횟수가 표시됩니다.

39명의 환자가 County General Hospital에서 관찰되고, 24명이 St. Mary's Medical Center에서 관찰되었으며,
37명이 VA Hospital에서 관찰되었습니다.
작업 공간 변수 SelfAssessedHealthStatus는 Excellent, Fair, Good, Poor라는 4개의 고유한 값을 포함합니다.
범주에 수학적 정렬 Poor < Fair < Good < Excellent가 적용되는 순서형 categorical형 배열로
SelfAssessedHealthStatus를 변환합니다.

categorical형 배열 SelfAssessedHealthStatus를 요약합니다.

3) 히스토그램 플로팅
SelfAssessedHealthStatus에서 직접 히스토그램 막대 플롯을 생성합니다.
이 categorical형 배열은 순서형 categorical형 배열입니다.
범주에는 정렬 Poor < Fair < Good < Excellent가 적용되어 있으므로,
이에 따라 플롯의 x축에서의 범주의 순서가 결정됩니다.
histogram 함수는 4개의 범주 각각에 대한 범주 개수를 플로팅합니다.

건강 상태가 Fair 또는 Poor로 평가된 환자에 대한 병원 위치만 나타내는 히스토그램을 생성합니다.

4) 원형 차트 생성하기
categorical형 배열에서 직접 원형 차트를 생성합니다.

함수 pie는 categorical형 배열 SelfAssessedHealthStatus를 받아 4개의 범주를 나타내는 원형 차트를 플로팅합니다.
5) 파레토 차트 생성
4개의 SelfAssessedHealthStatus 범주 각각에 대한 범주 개수를 기반으로 하여 파레토 차트를 생성합니다.
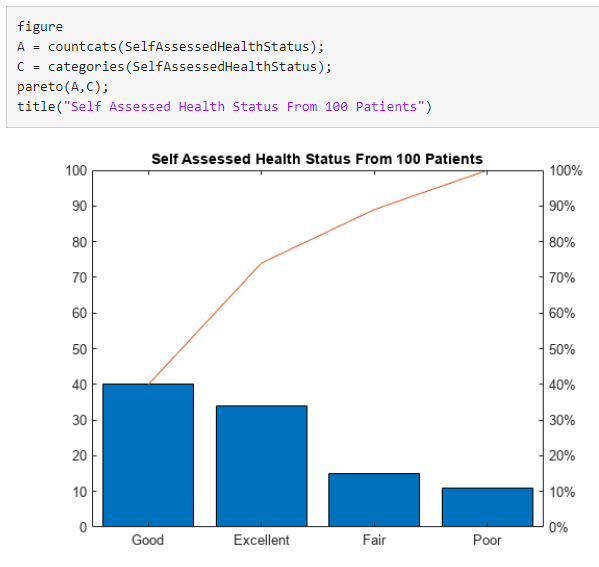
pareto에 대한 첫 번째 입력 인수는 벡터여야 합니다.
categorical형 배열이 행렬이거나 다차원 배열인 경우 countcats 및 pareto를 호출하기 전에 벡터로 형태 변경하십시오.
6) 산점도 플롯 생성
자가 검진한 건강 상태가 혈압 측정값과 관련이 있는지 확인합니다.
두 환자 그룹에 대한 Diastolic 측정값과 Systolic 측정값으로 구성된 산점도 플롯을 생성합니다.
먼저, 두 환자 그룹의 혈압 측정값으로 구성된 x 배열과 y 배열을 생성합니다.
첫 번째 환자 그룹은 자신의 건강 상태를 Poor 또는 Fair로 평가한 사람들로 구성됩니다.
두 번째 환자 그룹은 자신의 건강 상태를 Good 또는 Excellent로 평가한 사람들로 구성됩니다.
categorical형 배열 SelfAssessedHealthStatus를 사용하여 논리형 인덱스를 만들 수 있습니다.
논리형 인덱스를 사용하여 Diastolic과 Systolic의 값을 서로 다른 배열에 추출합니다.

X1 및 Y1은 건강 상태가 Poor 또는 Fair인 환자의 데이터를 포함하는 26×1 숫자형 배열입니다.
X2 및 Y2는 건강 상태가 Good 또는 Excellent인 환자의 데이터를 포함하는 74×1 숫자형 배열입니다.
두 환자 그룹에 대한 혈압 측정값으로 구성된 산점도 플롯을 생성합니다.
플롯에는 두 그룹 간의 차이를 의미할 만한 결과가 나타나지 않습니다.
이는 혈압과 자신의 건강에 대한 환자의 평가 사이에는 관련이 없음을 의미할 수 있습니다.

https://kr.mathworks.com/help/matlab/matlab_prog/plot-categorical-data.html
categorical형 데이터 플로팅하기 - MATLAB & Simulink - MathWorks 한국
이 예제의 수정된 버전이 있습니다. 사용자가 편집한 내용을 반영하여 이 예제를 여시겠습니까?
kr.mathworks.com